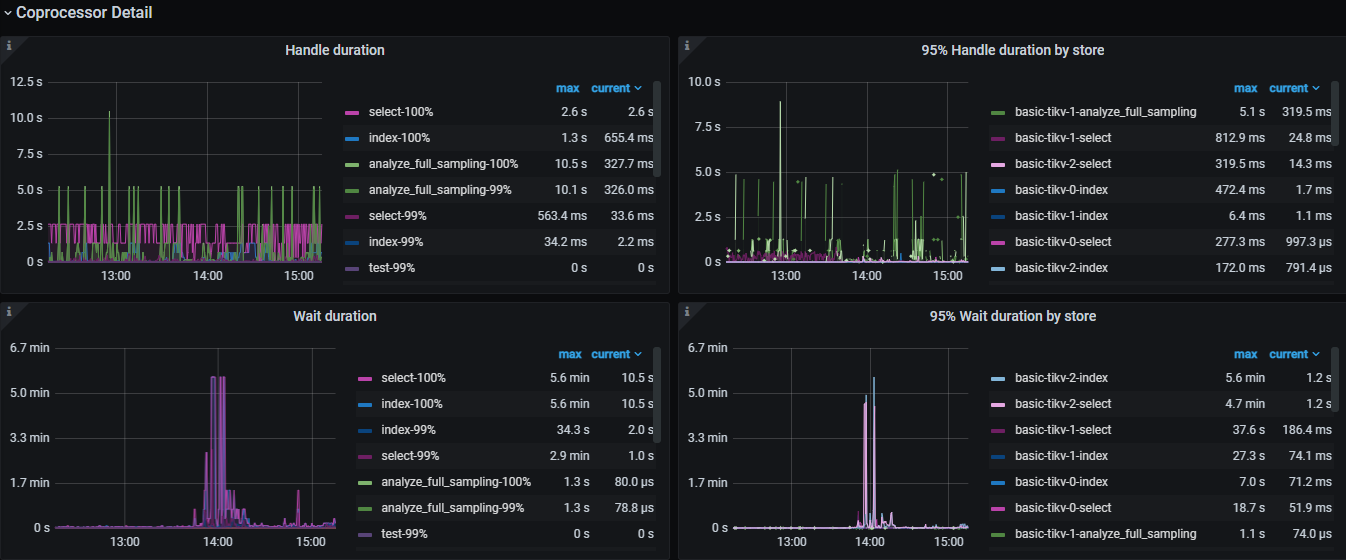
Is there any expert who can determine why the leader keeps migrating:
[2023/09/05 05:56:33.172 +00:00] [INFO] [region.go:652] [“leader changed”] [region-id=14949] [from=1] [to=5]
[2023/09/05 05:56:33.173 +00:00] [INFO] [operator_controller.go:565] [“operator finish”] [region-id=14949] [takes=19.191438ms] [operator=“"transfer-hot-write-leader {transfer leader: store 1 to 5} (kind:hot-region,leader, region:14949(689, 5), createAt:2023-09-05 05:56:33.152466395 +0000 UTC m=+442838.523916073, startAt:2023-09-05 05:56:33.154171016 +0000 UTC m=+442838.525620714, currentStep:1, size:67, steps:[transfer leader from store 1 to store 5], timeout:[1m0s]) finished"”] [additional-info=]
[2023/09/05 05:57:44.090 +00:00] [INFO] [operator_controller.go:452] [“add operator”] [region-id=14949] [operator=“"transfer-hot-write-leader {transfer leader: store 5 to 1} (kind:hot-region,leader, region:14949(689, 5), createAt:2023-09-05 05:57:44.08887786 +0000 UTC m=+442909.460327558, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, size:69, steps:[transfer leader from store 5 to store 1], timeout:[1m0s])"”] [additional-info=]
[2023/09/05 05:57:44.091 +00:00] [INFO] [operator_controller.go:651] [“send schedule command”] [region-id=14949] [step=“transfer leader from store 5 to store 1”] [source=create]
[2023/09/05 05:57:44.111 +00:00] [INFO] [region.go:652] [“leader changed”] [region-id=14949] [from=5] [to=1]
[2023/09/05 05:57:44.112 +00:00] [INFO] [operator_controller.go:565] [“operator finish”] [region-id=14949] [takes=20.841019ms] [operator=“"transfer-hot-write-leader {transfer leader: store 5 to 1} (kind:hot-region,leader, region:14949(689, 5), createAt:2023-09-05 05:57:44.08887786 +0000 UTC m=+442909.460327558, startAt:2023-09-05 05:57:44.091564863 +0000 UTC m=+442909.463014581, currentStep:1, size:69, steps:[transfer leader from store 5 to store 1], timeout:[1m0s]) finished"”] [additional-info=]
[2023/09/05 06:02:30.686 +00:00] [INFO] [operator_controller.go:452] [“add operator”] [region-id=14949] [operator=“"transfer-hot-write-leader {transfer leader: store 1 to 4} (kind:hot-region,leader, region:14949(689, 5), createAt:2023-09-05 06:02:30.685909429 +0000 UTC m=+443196.057359127, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, size:67, steps:[transfer leader from store 1 to store 4], timeout:[1m0s])"”] [additional-info=]
[2023/09/05 06:02:30.687 +00:00] [INFO] [operator_controller.go:651] [“send schedule command”] [region-id=14949] [step=“transfer leader from store 1 to store 4”] [source=create]
[2023/09/05 06:02:30.753 +00:00] [INFO] [region.go:652] [“leader changed”] [region-id=14949] [from=1] [to=4]
[2023/09/05 06:02:30.754 +00:00] [INFO] [operator_controller.go:565] [“operator finish”] [region-id=14949] [takes=67.698522ms] [operator=“"transfer-hot-write-leader {transfer leader: store 1 to 4} (kind:hot-region,leader, region:14949(689, 5), createAt:2023-09-05 06:02:30.685909429 +0000 UTC m=+443196.057359127, startAt:2023-09-05 06:02:30.68728017 +0000 UTC m=+443196.058729868, currentStep:1, size:67, steps:[transfer leader from store 1 to store 4], timeout:[1m0s]) finished"”] [additional-info=]
[2023/09/05 06:11:50.704 +00:00] [INFO] [operator_controller.go:452] [“add operator”] [region-id=14949] [operator=“"transfer-hot-write-leader {transfer leader: store 4 to 5} (kind:hot-region,leader, region:14949(689, 5), createAt:2023-09-05 06:11:50.702114441 +0000 UTC m=+443756.073564119, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, size:65, steps:[transfer leader from store 4 to store 5], timeout:[1m0s])"”] [additional-info=]
[2023/09/05 06:11:50.705 +00:00] [INFO] [operator_controller.go:651] [“send schedule command”] [region-id=14949] [step=“transfer leader from store 4 to store 5”] [source=create]
[2023/09/05 06:11:50.727 +00:00] [INFO] [region.go:652] [“leader changed”] [region-id=14949] [from=4] [to=5]
[2023/09/05 06:11:50.727 +00:00] [INFO] [operator_controller.go:565] [“operator finish”] [region-id=14949] [takes=22.1607ms] [operator=“"transfer-hot-write-leader {transfer leader: store 4 to 5} (kind:hot-region,leader, region:14949(689, 5), createAt:2023-09-05 06:11:50.702114441 +0000 UTC m=+443756.073564119, startAt:2023-09-05 06:11:50.705766004 +0000 UTC m=+443756.077215702, currentStep:1, size:65, steps:[transfer leader from store 4 to store 5], timeout:[1m0s]) finished"”] [additional-info=]