Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 服务器断电重启后集群无法启动
[TiDB Usage Environment] Production Environment
[TiDB Version] 7.1
[Reproduction Path] After the server power outage and restart, both TiKV and TiDB nodes cannot start. Tried using the tiup cluster restart command to restart the cluster.
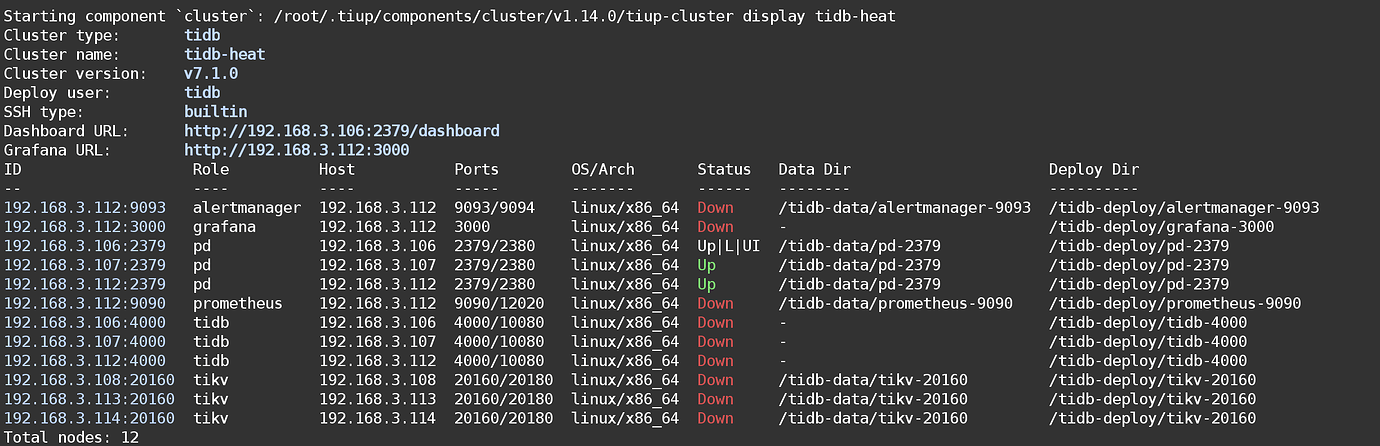
[Encountered Problem: Phenomenon and Impact] After the server power outage and restart, the cluster cannot start, only the PD node is in the up state.
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
Screenshot:
TiKV Log:
tikv0703.log (742.3 KB)
It looks like the file is corrupted. Is your environment a physical machine? Did all the machines lose power?
[2024/07/03 20:13:22.629 +08:00] [FATAL] [server.rs:921] ["failed to start node: Engine(Other(\"[components/raftstore/src/store/fsm/store.rs:1230]: \\\"[components/raftstore/src/store/entry_storage.rs:657]: [region 16] 17 validate state fail: Other(\\\\\\\"[components/raftstore/src/store/entry_storage.rs:472]: log at recorded commit index [12510] 39842466 doesn't exist, may lose data, region 16, raft state hard_state { term: 12510 vote: 204 commit: 39842344 } last_index: 39842345, apply state applied_index: 39842466 commit_index: 39842466 commit_term: 12510 truncated_state { index: 39842459 term: 12510 }\\\\\\\")\\\"\"))"]
The virtual machine is installed on a physical machine, and TiDB is installed on the virtual machine. The physical machine lost power, and all nodes went down. Is there any way to save this situation?
Is there a lossless repair solution? Or a solution with minimal loss?
You have to go for lossy recovery. Lossy recovery doesn’t necessarily mean that your data will be significantly affected. The lost data might be something you don’t need or isn’t important. Recover first and then evaluate.
Send the logs of other components and take a look.
Before restoring, make sure to back up the physical data of TiKV. Otherwise, any operational mistakes will be irreversible.
You need to back up the /tidb-data/tikv-20160 directory on each TiKV node, right?
So, you’re saying that lossy recovery might result in the loss of data from the short period when the issue occurred, right?
Power outages are indeed common in most work environments. I also want to know how to achieve minimal recovery without data loss.
pd.log (60.0 KB)
tidb.log (15.8 KB)
Not necessarily, it depends on whether the disk of your physical machine has failed due to a power outage. If the power outage directly causes a disk to fail and you haven’t set up RAID, it can be difficult. Of course, TiDB uses a 3-replica mechanism, so if your 3 TiKV instances are using three different disks, it doesn’t matter if one of them fails.
For backing up the data directory specified in your configuration, you can try to repair the region. There is also a worst-case recovery method, but it is not recommended. Network Failure Collective Migration IP Failure Recovery Process - TiDB Q&A Community (asktug.com)
Yes, the disk should not be damaged. It can still be mounted, and the files on the disk are still visible.
 Normally, a UPS and even a diesel generator are required. There generally shouldn’t be any power outages.
Normally, a UPS and even a diesel generator are required. There generally shouldn’t be any power outages.
[2024/07/03 20:15:44.482 +08:00] [FATAL] [server.rs:921] [“failed to start node: Engine(Other("[components/raftstore/src/store/fsm/store.rs:1230]: \"[components/raftstore/src/store/entry_storage.rs:657]: [region 16] 17 validate state fail: Other(\\\"[components/raftstore/src/store/entry_storage.rs:472]: log at recorded commit index [12510] 39842466 doesn’t exist, may lose data, region 16, raft state hard_state { term: 12510 vote: 204 commit: 39842344 } last_index: 39842345, apply state applied_index: 39842466 commit_index: 39842466 commit_term: 12510 truncated_state { index: 39842459 term: 12510 }\\\")\""))”]
Are all three nodes reporting this error? If they all fail to start due to this reason, you might have to resort to a loss recovery.
All three nodes are reporting this error.
Let’s start with lossy recovery. Are all of these on a single disk?