[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version] 5.4.2
[Reproduction Path] After executing the command tiup cluster scale-in to scale in TiKV, the issue was discovered.
[Encountered Issue: Symptoms and Impact]
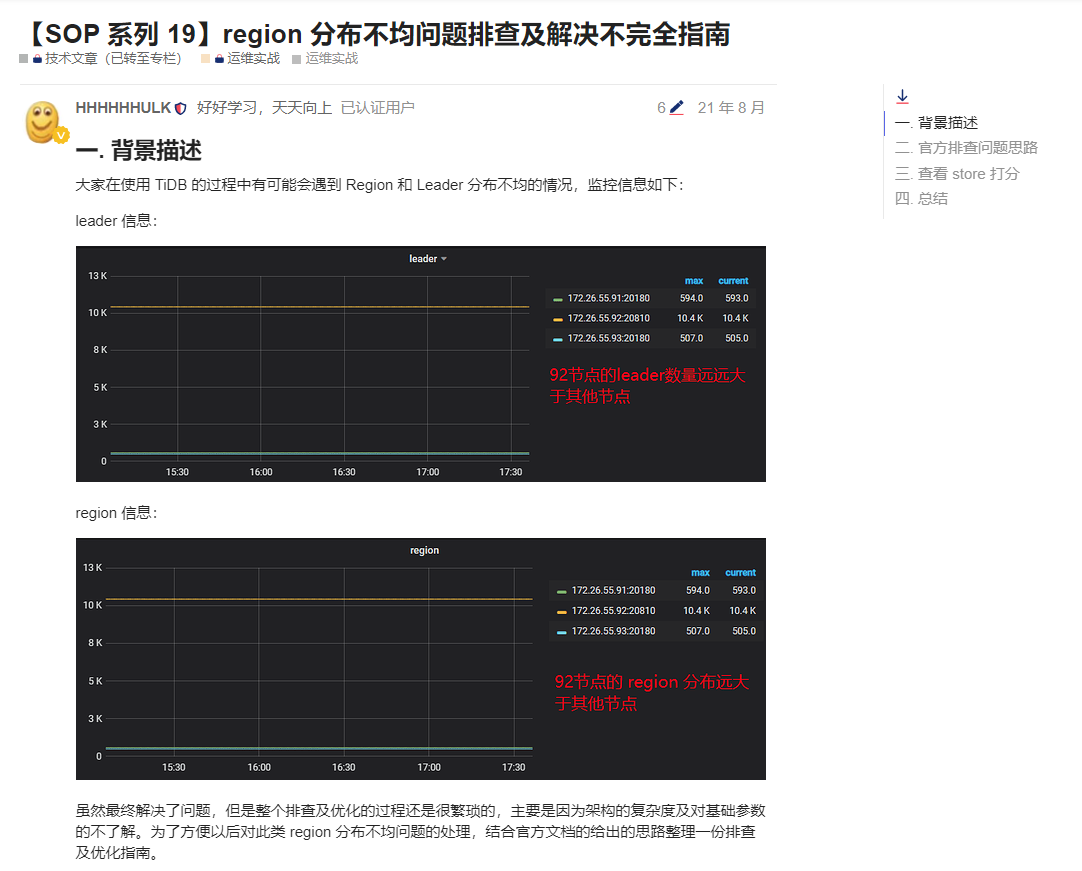
It was found that the leaders of each TiKV were unevenly distributed, with one node’s TiKV leader count dropping to 0, and the regions were also very unevenly distributed.
Follow the steps in the SOP to troubleshoot first, summarize the issue, and if it still can’t be resolved, add some more information and take another look.
Your cluster is quite impressive, with over 200k regions. That’s really awesome, and it must require a large disk. The imbalance is most likely due to the labels. For example, with 3 replicas, they need to be on 3 different machines. If you have 3 machines, A, B, and C, and you have 2 TiKV instances on machine A, then the 2 TiKV instances on A will share one replica. This means that the regions on TiKV1 + TiKV2 on A will equal the number of regions on the other machines.
It should still be related to the scheduling parameters. Follow the SOP above for the troubleshooting process and confirm whether the specific scheduling parameters are reasonable.
In my case, there is one KV per server, and there is no situation where one server has two KVs. After scaling down one KV, the distribution of regions across the KVs becomes unbalanced.
Version 5.4.2 is not recommended.
There doesn’t seem to be any issue based on what you posted.
If you still want to investigate further, check the PD panel in Grafana and look at the operators to see if there are any create or cancel actions.