Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 新表做了热点打散,但是leader region还是集中在一个节点。无法避免热点问题。
[TiDB Version] V5.4
[Overview] A new table was created with hotspot scattering, but the leader regions are still concentrated on one node, unable to avoid hotspot issues.
The table data is written from consuming MQ information, with frequent insert, update, and select operations. To avoid hotspot issues, SHARD_ROW_ID_BITS and PRE_SPLIT_REGIONS parameters were manually set to scatter the data. However, after creating the table, the leader region distribution is uneven, all concentrated on one node.
[Background] Operations performed
Recreated the table with SHARD_ROW_ID_BITS = 4 and PRE_SPLIT_REGIONS = 4.
[Phenomenon] Business and database phenomenon
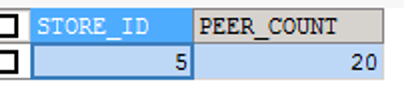
All leader regions are allocated to the node with store id 5, causing the CPU of that node to spike.
SELECT
p.STORE_ID,
COUNT(s.REGION_ID) PEER_COUNT
FROM
INFORMATION_SCHEMA.TIKV_REGION_STATUS s
JOIN INFORMATION_SCHEMA.TIKV_REGION_PEERS p ON s.REGION_ID = p.REGION_ID
WHERE
TABLE_NAME = 'XXX'
AND p.is_leader = 1
GROUP BY
p.STORE_ID
ORDER BY
PEER_COUNT DESC;
Is there any way to avoid having all leaders on one node?
The quickest solution is to check the slow SQL of the related table and see if the filtering conditions are highly selective. If they are, add an index to reduce full table scans, and you can see the effect immediately. If adding an index doesn’t solve the problem, you can look into Follower Read.
Refer to the troubleshooting steps in the official documentation: PD 调度策略最佳实践 | PingCAP 文档中心
Show the create table statement for XXXX, and also take a look at the related SQL for the table.
There are also Grafana screenshots related to regions, etc.
Does the table have a primary key? What is the data type of the primary key field?
CREATE TABLE `XXX` (
`ID` VARCHAR(200) NOT NULL COMMENT 'ID',
`VEHICLE_NO` VARCHAR(50) DEFAULT NULL COMMENT '',
`WAYBILL_NO` VARCHAR(50) NOT NULL COMMENT 'Waybill Number',
....
`DEP_NODE_THREE` INT(10) DEFAULT NULL COMMENT 'Departure Node 3',
`DEP_NODE_FOUR` INT(10) DEFAULT NULL COMMENT 'Departure Node 4',
`DEP_NODE_FIVE` INT(10) DEFAULT NULL COMMENT 'Departure Node 5',
`TKHK_TICKS` INT(10) DEFAULT NULL COMMENT 'Express xx Tickets',
`EXP_TICKS` INT(10) DEFAULT NULL COMMENT 'x',
`ACTIVE` CHAR(1) DEFAULT NULL COMMENT 'Is Active',
`CREATE_TIME` DATETIME(6) DEFAULT NULL COMMENT 'Creation Time',
`PARTITION_DATE` DATE NOT NULL COMMENT 'Partition Date',
`SHARDING_ITEM` INT(10) DEFAULT NULL COMMENT 'Sharding Item',
PRIMARY KEY (`ID`) /*T![clustered_index] NONCLUSTERED */,
KEY `IDX_UPII_WAYBILL_NO` (`WAYBILL_NO`),
KEY `IDX_UPII_CREATE_TIME` (`CREATE_TIME`),
KEY `IDX_ITEM_TIME` (`SHARDING_ITEM`,`CREATE_TIME`),
KEY `IDX_UPII_GROUP_BY_COMPOSITE` (`VEHICLE_NO`,`ARRIVE_ORG_CODE`,`CONSUMER_TAG`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='xxx' SHARD_ROW_ID_BITS = 4,PRE_SPLIT_REGIONS = 4;
ID VARCHAR(200) NOT NULL COMMENT ‘ID’
The distribution of hot write regions has always been uneven.
The distribution of write leaders is uneven, while the distribution of read leaders is very even. This indicates that store 5 has a high write volume, causing regions to continuously split in store 5 and then be scheduled to other stores.
How did you determine that it is the leader related to this table? I suspect it might be other tables or indexes.
If you take out the heatmap from the dashboard, you will know which table it is.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.