Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: Sort算子落盘性能太慢,希望产品层面进行优化
[Problem Scenario Involved in the Requirement]
During the performance testing of traditional databases and TiDB databases, regarding sorting, as long as it involves disk spilling, TiDB’s performance will have a significant discount.
Here, we use the open-source database PostgreSQL (referred to as: pg) as a test case to compare the performance of the sort operator. The comparison methods are:
- Single-threaded in-memory sorting, observing efficiency.
- Single-threaded disk spill sorting, observing efficiency.
- pg multi-threaded disk spill sorting, observing efficiency. (pg’s in-memory sorting method is quicksort, which does not support parallelism, while disk spill sorting supports parallelism)
Other notes: TiDB does not support parallel sorting, so only single-threaded tests are conducted.
The table structure and data volume are as follows:
mysql> show create table customer \G
*************************** 1. row ***************************
Table: customer
Create Table: CREATE TABLE `customer` (
`C_CUSTKEY` bigint(20) NOT NULL,
`C_NAME` varchar(25) NOT NULL,
`C_ADDRESS` varchar(40) NOT NULL,
`C_NATIONKEY` bigint(20) NOT NULL,
`C_PHONE` char(15) NOT NULL,
`C_ACCTBAL` decimal(15,2) NOT NULL,
`C_MKTSEGMENT` char(10) NOT NULL,
`C_COMMENT` varchar(117) NOT NULL,
PRIMARY KEY (`C_CUSTKEY`) /*T![clustered_index] CLUSTERED */,
KEY `customer_idx1` (`C_PHONE`),
KEY `customer_idx2` (`C_NATIONKEY`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
1 row in set (0.00 sec)
mysql> select count(*) from customer;
+----------+
| count(*) |
+----------+
| 1500000 |
+----------+
1 row in set (0.56 sec)
1. Single-threaded in-memory sorting, observing efficiency.
TiDB:
Set the statement memory size to 1GB, table scan concurrency to 1;
set tidb_distsql_scan_concurrency=1;
set tidb_mem_quota_query=1073741824;
mysql> explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+---------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+---------+
| Sort_4 | 1500000.00 | 1500000 | root | | time:7.26s, loops:1466 | tpch.customer.c_comment:desc, tpch.customer.c_acctbal | 351.5 MB | 0 Bytes |
| └─TableReader_8 | 1500000.00 | 1500000 | root | | time:1.86s, loops:1471, cop_task: {num: 8, max: 445.5ms, min: 67.7ms, avg: 231.2ms, p95: 445.5ms, max_proc_keys: 297022, p95_proc_keys: 297022, tot_proc: 1.32s, tot_wait: 2ms, rpc_num: 8, rpc_time: 1.85s, copr_cache: disabled, distsql_concurrency: 1} | data:TableFullScan_7 | 128.9 MB | N/A |
| └─TableFullScan_7 | 1500000.00 | 1500000 | cop[tikv] | table:customer | tikv_task:{proc max:173ms, min:34ms, avg: 110.3ms, p80:172ms, p95:173ms, iters:1502, tasks:8}, scan_detail: {total_process_keys: 1500000, total_process_keys_size: 305225771, total_keys: 1500008, get_snapshot_time: 6.43ms, rocksdb: {key_skipped_count: 1500000, block: {cache_hit_count: 5035}}} | keep order:false | N/A | N/A |
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+---------+
3 rows in set (7.27 sec)
It can be seen that the copTask in the tikv-client cache size is 128MB, the sorting is all done in memory, using 351MB, and the total memory usage of the statement is about 500MB.
The test situation in pg is as follows:
tpch=# explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Sort (cost=206554.90..210304.40 rows=1499799 width=167) (actual time=12918.633..13180.047 rows=1500000 loops=1)
Sort Key: c_comment DESC, c_acctbal
Sort Method: quicksort Memory: 439757kB
-> Seq Scan on customer (cost=0.00..52702.99 rows=1499799 width=167) (actual time=0.005..111.692 rows=1500000 loops=1)
Planning Time: 0.065 ms
Execution Time: 13237.138 ms
(6 rows)
Time: 13237.643 ms (00:13.238)
It can be seen that in terms of quicksort, TiDB’s performance is significantly better than pg.
(Data loading only takes 1.x seconds, so the data reading time is temporarily ignored)
pg takes 13 seconds, 430MB of memory. TiDB only takes 7.3 seconds, 350MB of memory.
2. Single-threaded disk spill sorting, observing efficiency.
From the above test, it can be seen that the copTask in the tikv-client cache size is 128MB, the sorting is all done in memory, using 351MB, and the total memory usage of the statement is about 500MB. To make it spill to disk, modify the memory to 200MB:
set tidb_distsql_scan_concurrency=1;
set tidb_mem_quota_query=209715200;
mysql> explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+----------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+----------+
| Sort_4 | 1500000.00 | 1500000 | root | | time:39.3s, loops:1466 | tpch.customer.c_comment:desc, tpch.customer.c_acctbal | 144.9 MB | 284.2 MB |
| └─TableReader_8 | 1500000.00 | 1500000 | root | | time:1.94s, loops:1471, cop_task: {num: 8, max: 470.8ms, min: 70.3ms, avg: 241.2ms, p95: 470.8ms, max_proc_keys: 297022, p95_proc_keys: 297022, tot_proc: 1.38s, tot_wait: 4ms, rpc_num: 8, rpc_time: 1.93s, copr_cache: disabled, distsql_concurrency: 1} | data:TableFullScan_7 | 128.9 MB | N/A |
| └─TableFullScan_7 | 1500000.00 | 1500000 | cop[tikv] | table:customer | tikv_task:{proc max:186ms, min:34ms, avg: 112.4ms, p80:174ms, p95:186ms, iters:1502, tasks:8}, scan_detail: {total_process_keys: 1500000, total_process_keys_size: 305225771, total_keys: 1500008, get_snapshot_time: 7.08ms, rocksdb: {key_skipped_count: 1500000, block: {cache_hit_count: 5035}}} | keep order:false | N/A | N/A |
+-------------------------+------------+---------+-----------+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+----------+----------+
3 rows in set (39.30 sec)
It can be seen that external sorting takes 39.3 seconds.
The test situation in pg is as follows:
Turn off pg parallelism, set the sort area memory size to 50MB (less than the memory used by TiDB sorting):
tpch=# set work_mem=51200;
tpch=# set max_parallel_workers_per_gather=1;
SET
Time: 0.397 ms
tpch=# explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=207024.61..308481.63 rows=882235 width=167) (actual time=4737.983..7385.264 rows=1500000 loops=1)
Workers Planned: 1
Workers Launched: 1
-> Sort (cost=206024.60..208230.19 rows=882235 width=167) (actual time=4507.940..5643.202 rows=750000 loops=2)
Sort Key: c_comment DESC, c_acctbal
Sort Method: external merge Disk: 143792kB
Worker 0: Sort Method: external merge Disk: 123336kB
-> Parallel Seq Scan on customer (cost=0.00..46527.35 rows=882235 width=167) (actual time=0.008..61.661 rows=750000 loops=2)
Planning Time: 0.066 ms
Execution Time: 7468.150 ms
(10 rows)
It can be seen that pg external sorting takes 7.4 seconds, which is nearly twice as fast as full in-memory quicksort.
It can be seen that in terms of external sorting that spills to disk, pg’s performance is significantly better than TiDB.
pg takes 7.5 seconds, TiDB takes 39.3 seconds.
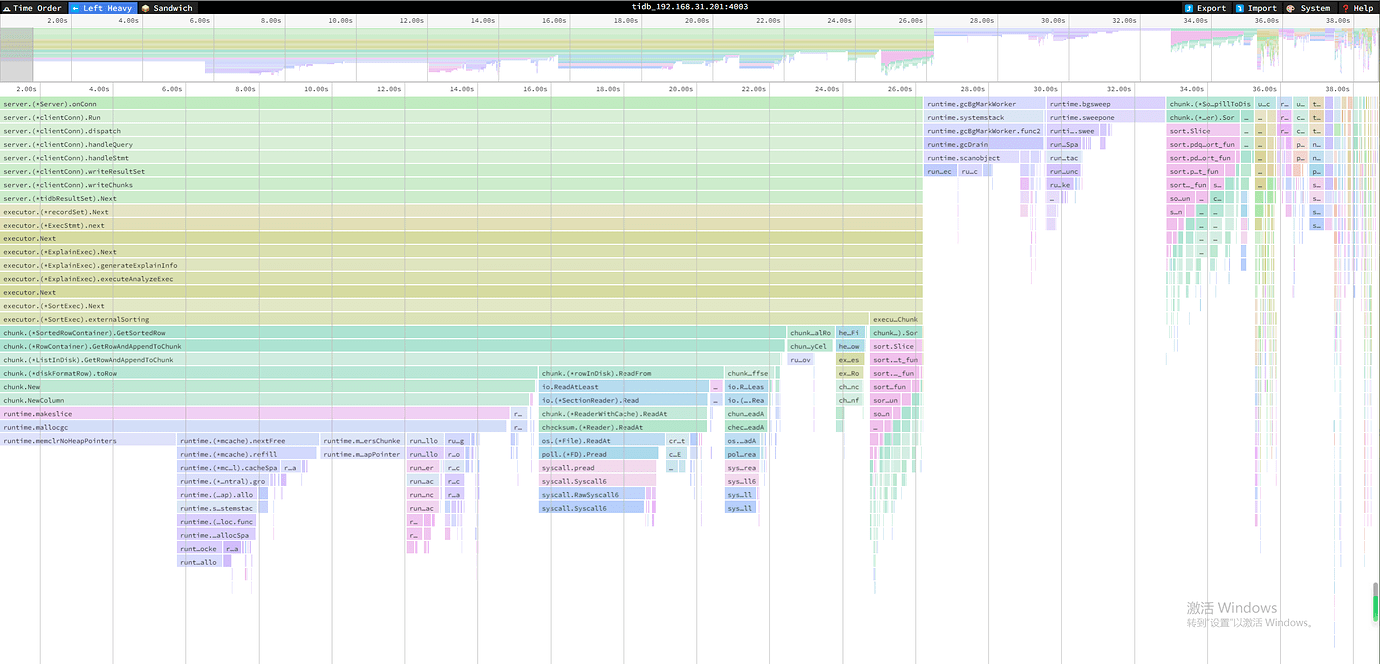
TiDB’s main time consumption is spent on disk wait-related processing:
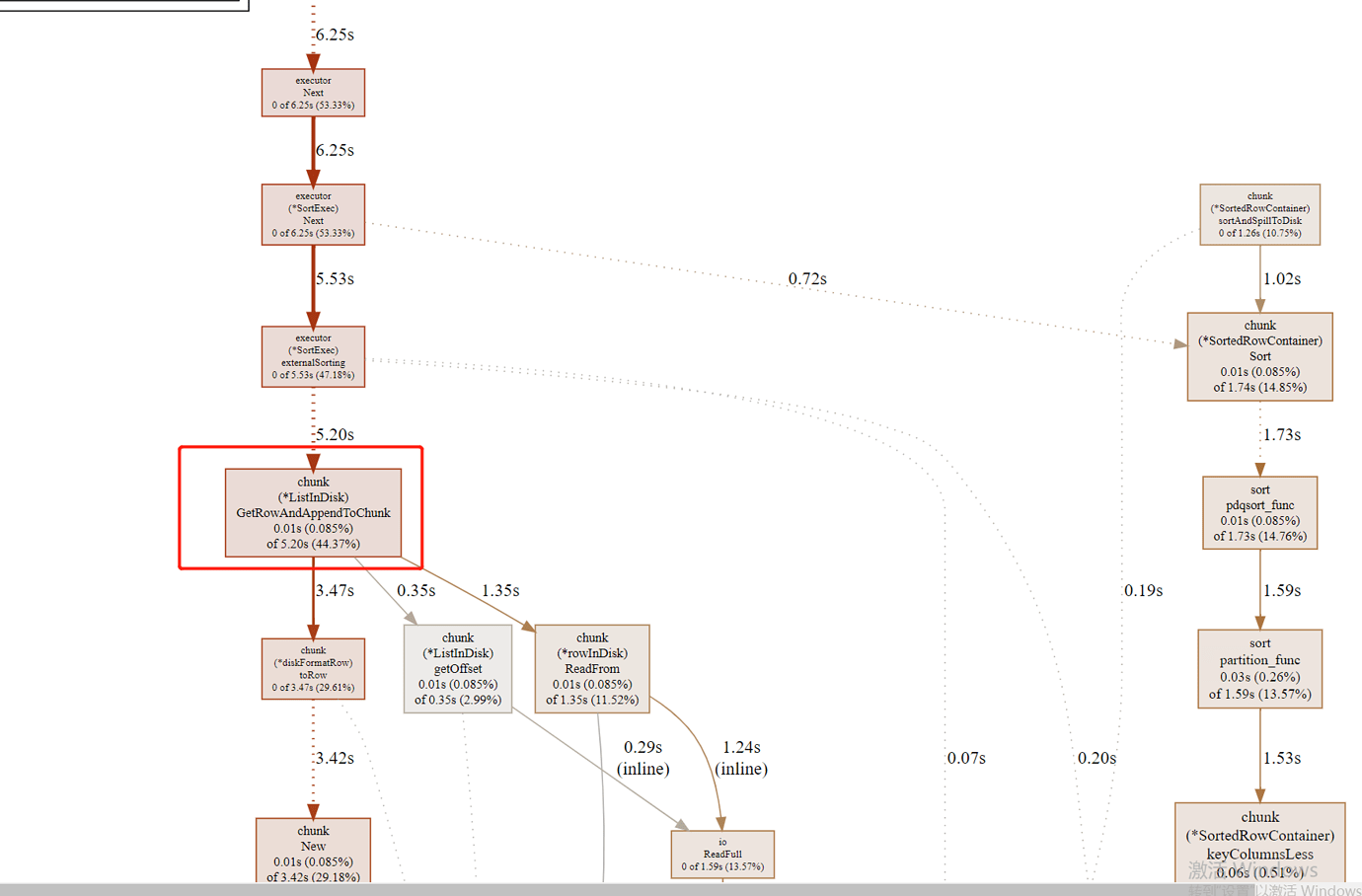
3. pg multi-threaded disk spill sorting, observing efficiency
# Enable parallelism:
set max_parallel_workers_per_gather=4;
# Set the sort work area to 50MB. (Smaller than the memory available for TiDB's sort operator)
set work_mem=51200;
tpch=# explain analyze select * from customer order by C_COMMENT desc, C_ACCTBAL asc;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=107926.06..287503.96 rows=1499799 width=167) (actual time=2829.578..6503.408 rows=1500000 loops=1)
Workers Planned: 4
Workers Launched: 4
-> Sort (cost=106926.00..107863.38 rows=374950 width=167) (actual time=2618.420..2836.848 rows=300000 loops=5)
Sort Key: c_comment DESC, c_acctbal
Sort Method: external merge Disk: 62128kB
Worker 0: Sort Method: external merge Disk: 79400kB
Worker 1: Sort Method: external merge Disk: 31752kB
Worker 2: Sort Method: external merge Disk: 62128kB
Worker 3: Sort Method: external merge Disk: 31744kB
-> Parallel Seq Scan on customer (cost=0.00..41454.50 rows=374950 width=167) (actual time=0.010..57.328 rows=300000 loops=5)
Planning Time: 0.148 ms
Execution Time: 6571.564 ms
(13 rows)
It can be seen that in terms of parallelism, pg’s external sorting does not have much performance improvement (but by observing, the CPU consumption has increased several times).
Overall conclusion: TiDB’s external sorting is several times slower than pg.
Therefore, it is hoped that TiDB’s external sorting can be further optimized, such as making the disk spill behavior asynchronous to reduce the time consumption unrelated to sorting, thereby increasing the overall sorting efficiency.