Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 同一个执行计划 少部分Coprocessor 请求数量偏大 导致部分sql超时
To improve efficiency, please provide the following information. A clear problem description will help resolve the issue faster:
【TiDB Usage Environment】
AWS EC2 deployment using TiUP
【Overview】 Scenario + Problem Overview
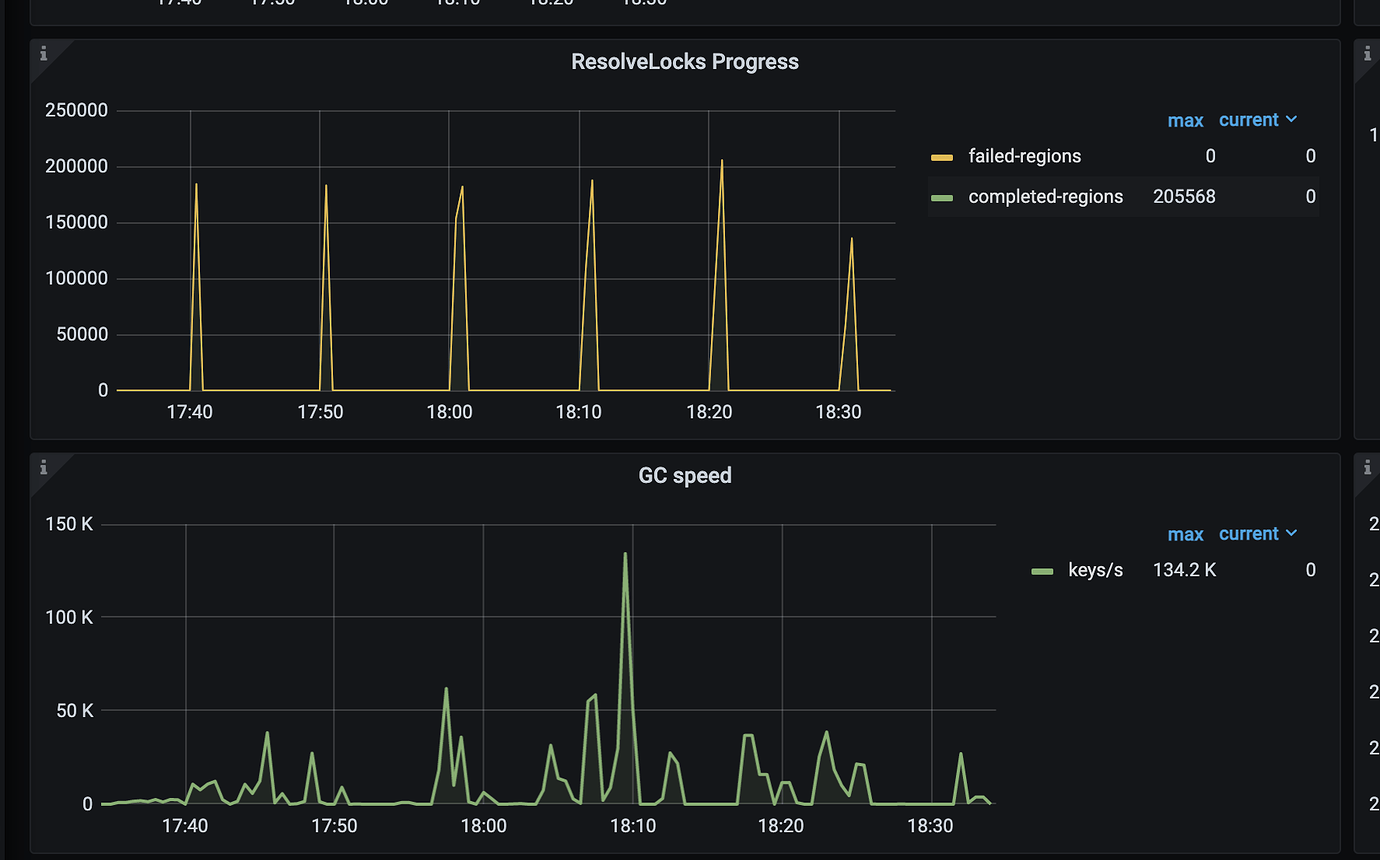
Low data resource utilization, not a hardware resource bottleneck
【Background】 Actions taken
【Phenomenon】 Business and database phenomena
There is a highly concurrent SQL query with an average query time of around 50ms, but a small portion of queries take more than 1 second. Comparing slow queries with average queries, the execution plan is consistent, but the number of Coprocessor requests and visible versions for slow queries is a hundred times higher than the average.
【Problem】 Current issue encountered
SQL timeout
【Business Impact】
Causes some SQL queries to time out in the business system.
【TiDB Version】
5.2.1
【Application Software and Version】
Spring Boot
【Attachments】 Relevant logs and configuration information
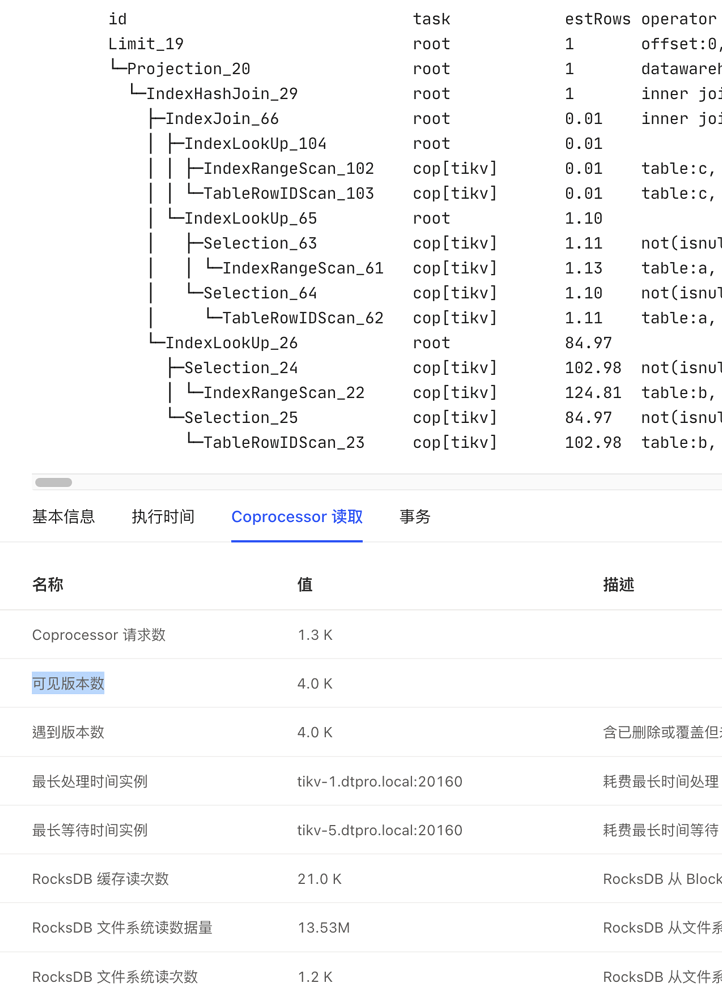
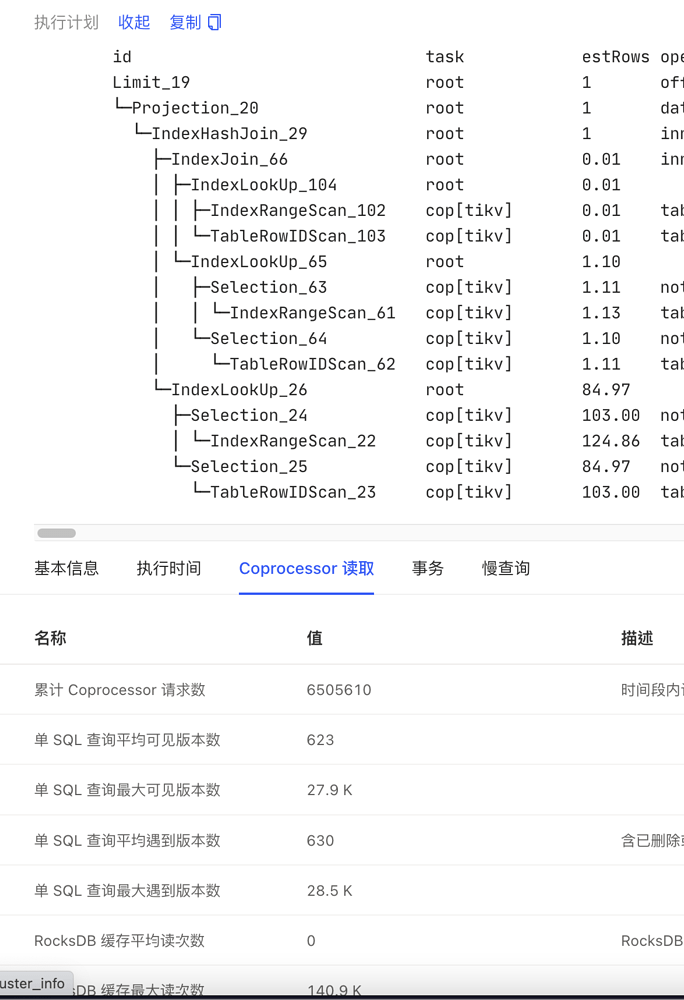
- TiUP Cluster Display information
- TiUP Cluster Edit config information
Monitoring (https://metricstool.pingcap.com/)
- TiDB-Overview Grafana monitoring
- TiDB Grafana monitoring
- TiKV Grafana monitoring
- PD Grafana monitoring
- Corresponding module logs (including logs 1 hour before and after the issue)
For questions related to performance optimization or troubleshooting, please download and run the script. Please select all and copy-paste the terminal output results for upload.