【Encountered Problem】
In the TiDB database, importing 1 million records caused the file system usage to increase by 20GB, which is a significant discrepancy between the data volume and the corresponding file size. For the same data volume, the MySQL database file size is only 1.5GB.
【Reproduction Path】Operations performed that led to the problem
【Problem Phenomenon and Impact】
In the TiDB database, importing 1 million records caused the file system usage to increase by 20GB, which is a significant discrepancy between the data volume and the corresponding file size. For the same data volume, the MySQL database file size is only 1.5GB. The community version of TiDB uses the file system to store data, and the file storage density is too low, causing the file size to grow too quickly.
【Attachments】
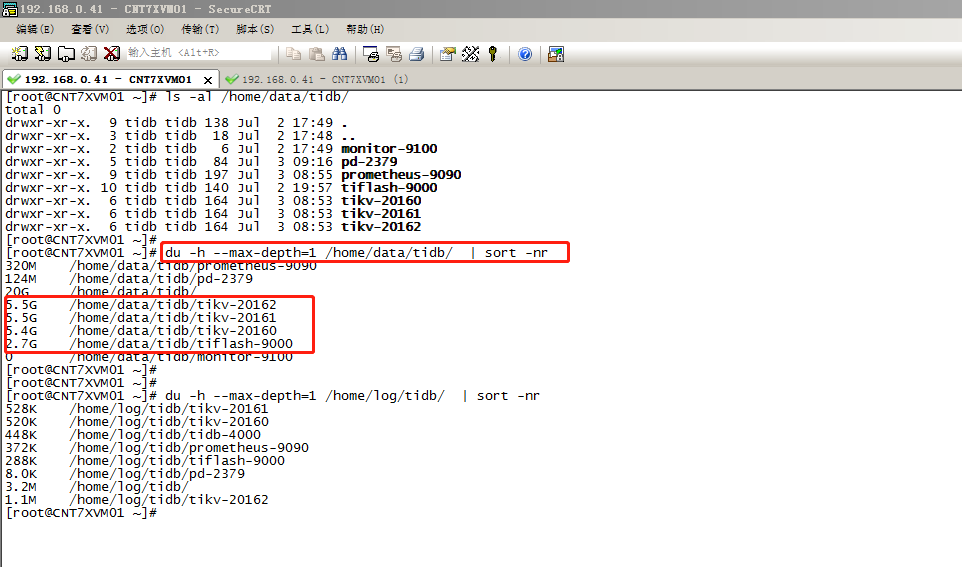
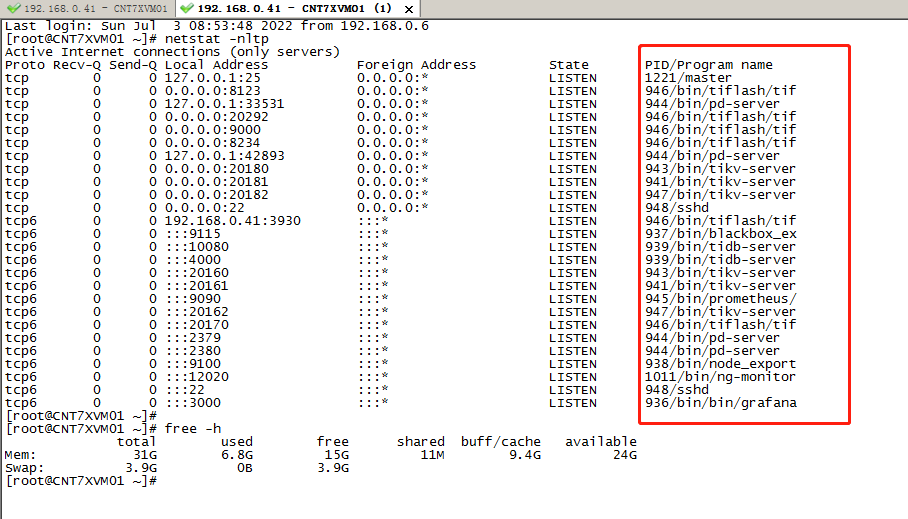
TiDB single-node pseudo-cluster, data file system usage size
First, you need to consider multiple replicas. For example, with the default of 3 replicas, you need to triple the space. Then, you need to consider MVCC (Multi-Version Concurrency Control). Unlike MySQL, which uses undo logs to implement this, in TiDB, different versions of the same row of data are stored as different KV pairs in RocksDB. These need to wait for GC (Garbage Collection) to delete old snapshot data, after which the space will decrease. Finally, you also need to consider the space amplification of RocksDB’s 7-level LSM Tree structure, which is approximately 1.12 times.
That’s just a verification. If you want to do a POC, you should refer to the configuration requirements provided by the official documentation. Additionally, the other information you mentioned is all described in detail in the official documentation, but there is a lot of it, so it will take quite a bit of time and effort to go through it all.
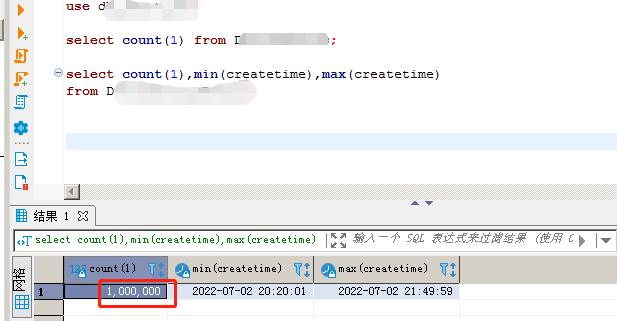
Thank you for your enthusiastic reply. I have a question. In actual production use, if TiDB data is stored in a three-replica manner, will there be a situation where 1 million rows of experimental data occupy 20GB in the TiDB database file system?
Is this a characteristic of the TiDB community version itself, or is there a configuration error on my part?
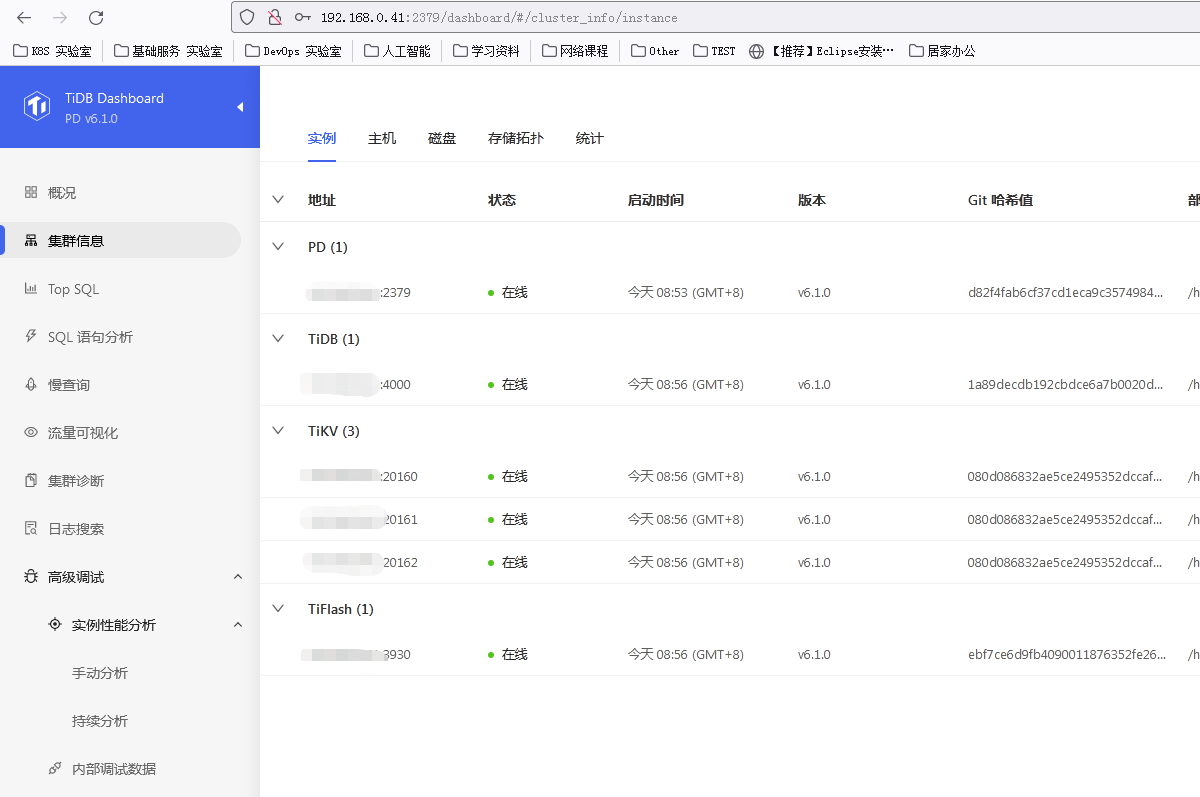
Simulating a production environment cluster on a single machine:
Note: My test environment uses a virtual machine with 8 vCPUs, 36GB of memory, and a 320GB SSD.
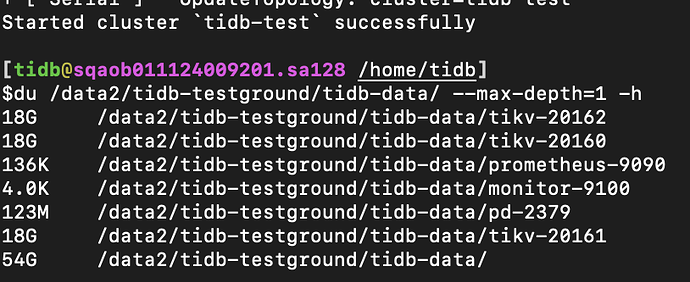
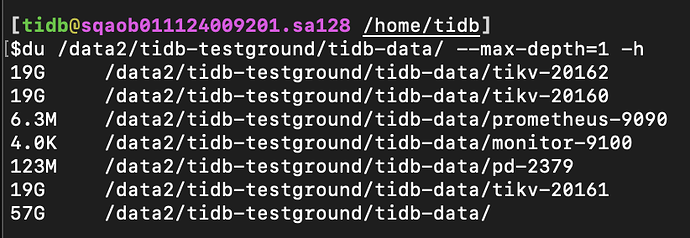
I also configured a single machine with 3 replicas of TiKV + 1 TiFlash along with other default settings. After inserting hundreds of thousands of rows of data, the total size of all regions should be around 1-2 GB, and the file size increased by approximately 3-4 GB. However, the total size of the folder naturally increased by more than 50 GB after the cluster was started.
You can see there are about 4 regions, each approximately 100 MB in size. Considering the 3 replicas, the total size should be around 1.2 GB. Now the file system usage has increased by 3 GB:
You can control the compression algorithm used by each level of RocksDB by adjusting the following parameters, but it is generally not recommended to adjust them: TiKV 配置文件描述 | PingCAP 文档中心
You can see the space amplification rate on the Size amplification graph on the PD → Statistics - Balance page in Grafana.