Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: k8s搭建的ticdc集群任务分配不均匀
[TiDB Usage Environment]
Production/Test Environment/POC
Production
[TiDB Version]
5.4.1
[Encountered Problem]
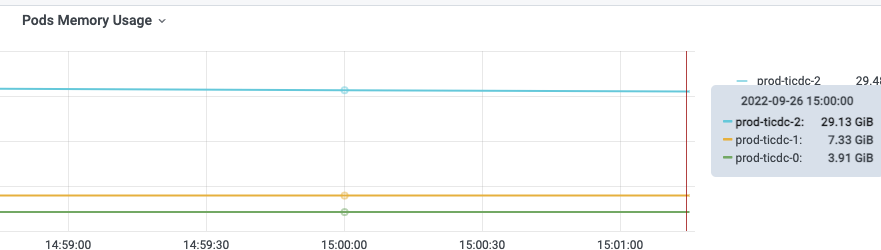
The task allocation in the ticdc cluster built on k8s is uneven. There are three nodes, each pod has a resource limit of 16c64G. Only the owner node has a very high memory pressure, occupying more than 30G, while the other two nodes have memory usage below 10G.
[Reproduction Path] What operations were performed to encounter the problem
[Problem Phenomenon and Impact]
[Attachment]
Supplement:
Currently, there are more than 120 changefeeds.
It is normal for the resource consumption of the owner node to be higher than that of other nodes.
- The owner node has two roles simultaneously: one is the owner, and the other is the processor, which also exists on other nodes.
- The owner role needs to aggregate and process all the information of the changefeed, store all the upstream schema information of the changefeed in memory, and monitor all the ddl changes and ddl heartbeats of the changefeed. When the number of changefeeds is large, it is quite normal for its CPU and memory usage to be high.
- The processor role will bear the same load as the processor on other nodes.
In summary, it is normal for the owner node to consume more resources than other nodes.
Additionally, there is another possibility: if the processor role within the owner node is assigned a table with high write traffic, it may consume more resources.
But the gap is too obvious. When the owner node is high, it’s over 40G, but the other nodes are all maintained below 10G.
How is the load balancing of tables in changefeed handled?
In which file is the balancing source code located?
Don’t let the post sink. Seeking a reply from the experts.
CDC currently performs load balancing based on the number of tables rather than the traffic of the tables. Therefore, when a high-traffic table is scheduled on the owner node, the resource consumption of the owner node may be relatively high.
Additionally, managing changefeeds and maintaining a schemaStorage for each changefeed can be quite memory-intensive.
The main logic for table scheduling in version v5.4.1 can be found here: tiflow/cdc/owner/scheduler_v1.go at v5.4.1 · pingcap/tiflow · GitHub
The logic for maintaining schemaStorage by the owner in version v5.4.1 can be found here: tiflow/cdc/owner/schema.go at v5.4.1 · pingcap/tiflow · GitHub
Could you please tell me the total number of databases and tables in the upstream TiDB cluster?
The TiDB above mainly uses one database, which contains over 1000 tables. There are a total of 120+ changefeeds for CDC synchronization, with each changefeed monitoring one table. Is the high memory usage of the owner due to the excessive number of changefeeds? Or is it more reasonable to configure multiple tables within a single changefeed?
Yes, multiple changefeeds will place a significant burden on the owner because the owner will maintain a schemaStorage for all tables upstream for each changefeed. In your scenario, this means 120 * 1000 = 120,000 tableInfos. Additionally, other resources that are normally shared between tables will also be created multiple times.
For regular tables, it is recommended to use a single changefeed to synchronize multiple tables. For tables that may generate large transactions and high traffic, use separate changefeeds for synchronization.
I tried monitoring 5 tables in one changefeed. With 3 nodes, the tables were relatively evenly distributed as 2, 2, and 1.
So if one changefeed monitors 1 table with 3 nodes, will it be preferentially assigned to the owner node?
It will be evenly distributed and not prioritized.
Hmm, I am reading about the logic from table balancing to capture.
I understand the reason for the high memory pressure on the owner node.
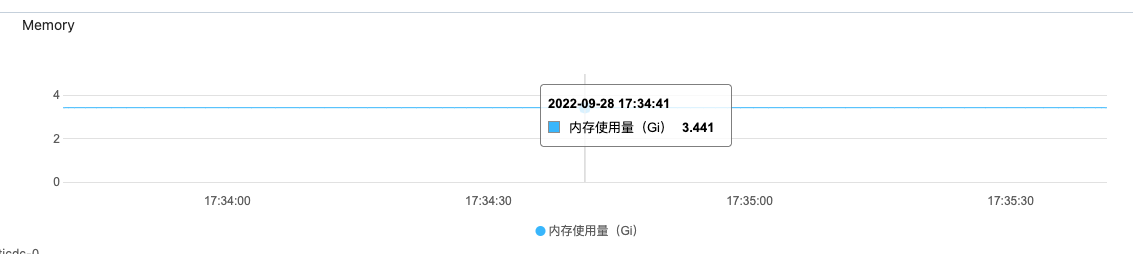
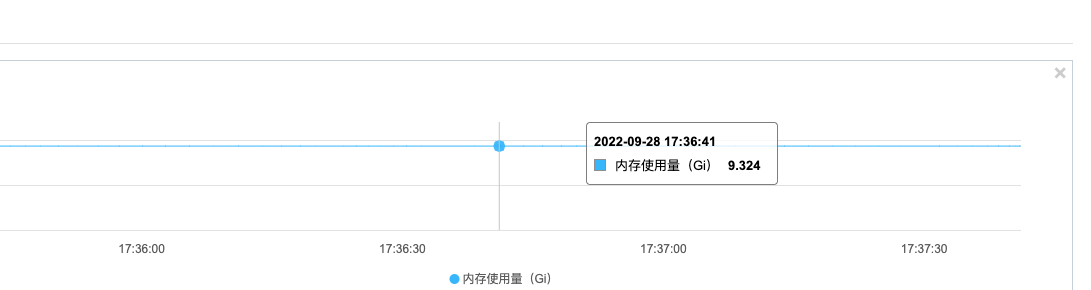
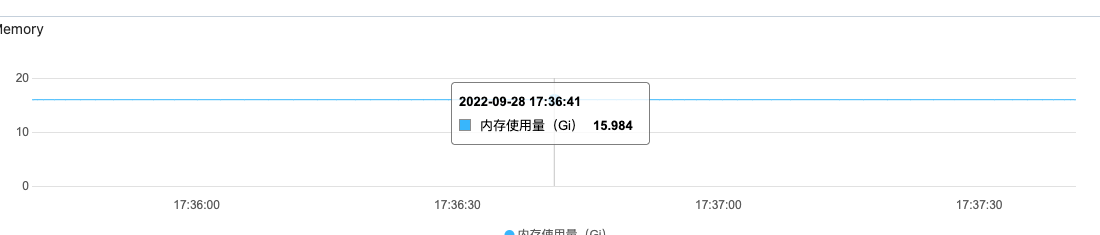
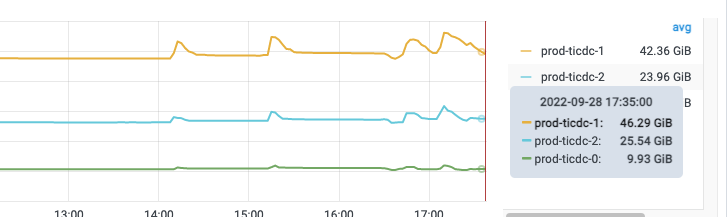
However, the memory usage on the other two nodes is also unbalanced.
As shown below, in the test environment:
In the production environment:
The resource imbalance of the other two nodes is caused by uneven table traffic. You can first check which table has higher traffic, and then use the API to schedule that table to a node with lower resource consumption: TiCDC OpenAPI | PingCAP 文档中心
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.