Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 有大量Empty region,且kv数据分布不均匀
【TiDB Usage Environment】
Production environment
【TiDB Version】
v4.0.12
【Encountered Problem】
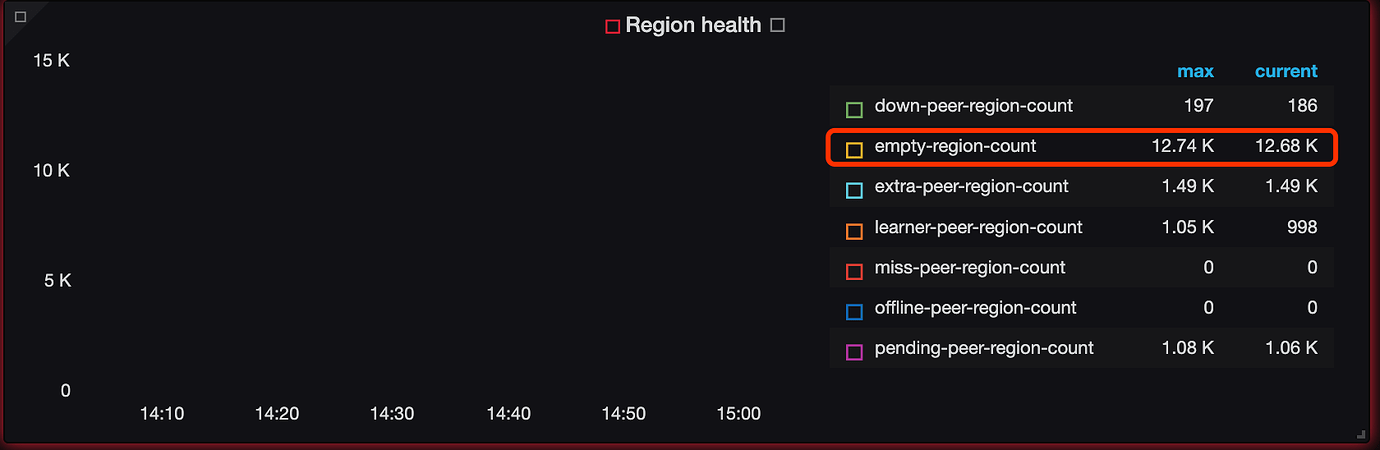
During routine maintenance, it was found that the disk usage of some KV nodes was extremely high, and a large number of Empty regions appeared in the monitoring. According to the documentation and previous posts, operations such as Store Limit, enable-cross-table-merge, max-merge-region-keys, max-merge-region-size, and region-schedule-limit were performed, but to no avail.
【Reproduction Path】
【Problem Phenomenon and Impact】
【Attachments】
Please provide the version information of each component, such as cdc/tikv, which can be obtained by executing cdc version/tikv-server --version.
hengpu-cluster-PD-1658385668172.json (217.4 KB) hengpu-cluster-PD_2022-07-21T06_58_41.869Z.json (16.0 MB)
Has cross-table region merging been enabled?
enable-cross-table-merge
- Sets whether to enable cross-table merge.
- Default value: true
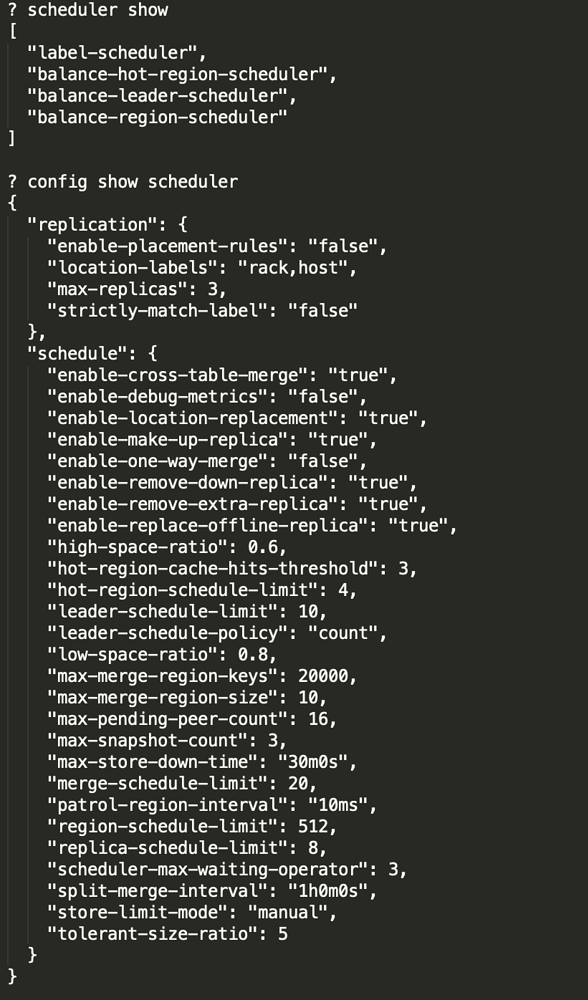
It’s open, and it’s in the picture above.
There is also this parameter that needs to be adjusted, I encountered it at that time as well.
enable-cross-table-merge Default false. If set to true, it indicates that two regions from different tables can be merged. This option is only effective when the key type is “table”.
Try reducing the patrol-region-interval as well.
The key-type in TiDB should default to table, this has never been changed.
This has already been changed from 100ms to 10ms, but it still has no effect.
Check the TiKV parameter
split-region-on-table to see if it is set to false,
restart TiKV.
If conditions permit, you can evict a TiKV leader to 0, and then restart TiKV.
By using show config, the online query shows that coprocessor.split-region-on-table is false.
I also tried the other parameters in the FAQ I posted. At that time, I also cleared the empty region according to the end of this FAQ.
Is the high usage of some disks reaching the thresholds of these two parameters?
If so, adjust these two parameters.
It seems that your parameters indicate that there will be issues when the disk usage reaches 60%.
There is a high disk usage rate on some nodes, but not on others, so it is currently suspected that empty regions are causing this. If this parameter is modified, leading to issues with node score calculation, could it potentially cause an avalanche?
A temporary solution is to manually create some operators to merge regions.
echo 'tiup ctl:v4.0.12 pd operator add merge-region '`tiup ctl:v4.0.12 pd region check empty-region --pd 10.1.48.44:2379 | jq '.regions[].id' | tail -1000 | xargs -l2`
This parameter should be set to false by default after version 4.0. It is not configured in the configuration file, and querying it shows that it is already set to false. It still doesn’t work.
You can add new nodes, adjust the parameters, and wait for the cluster to automatically balance. This is what I encountered before. An avalanche shouldn’t happen; just increase the threshold a bit.
It is still recommended to try reloading as mentioned in the FAQ.
I see you’ve tried all the operations mentioned above, but they didn’t work, right? Check the PD monitoring on Grafana to see if any region operators have been generated. I’ve encountered a similar issue before; adjusting the store limit and shortening the merge time didn’t help. In the end, I switched the PD leader, and the merge started working smoothly. You can give it a try  . It might be a quirky trick, but since you’ve tried everything else, you might as well give it a shot.
. It might be a quirky trick, but since you’ve tried everything else, you might as well give it a shot.
Here are the commands to switch the leader:
pd-ctl -i
member leader show
# Resign the leader from the current member:
>> member leader resign
# Transfer the leader to a specified member:
>> member leader transfer pd3
Empty regions are generated after GC processes drop/truncate objects. The trend for empty regions is decreasing, but the region merging is relatively slow. You can try increasing the parameters: region-schedule-limit: 2048, merge-schedule-limit=64.
Switching the leader didn’t work either…