Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: ticdc [CDC:ErrMySQLTxnError]MySQL txn error: context deadline exceeded
[TiDB Usage Environment] Production Environment
[TiDB Version]
v6.5.2
[Reproduction Path] Operations performed that led to the issue
Upgraded from v6.5.1 to v6.5.2
[Encountered Issue: Problem Phenomenon and Impact]
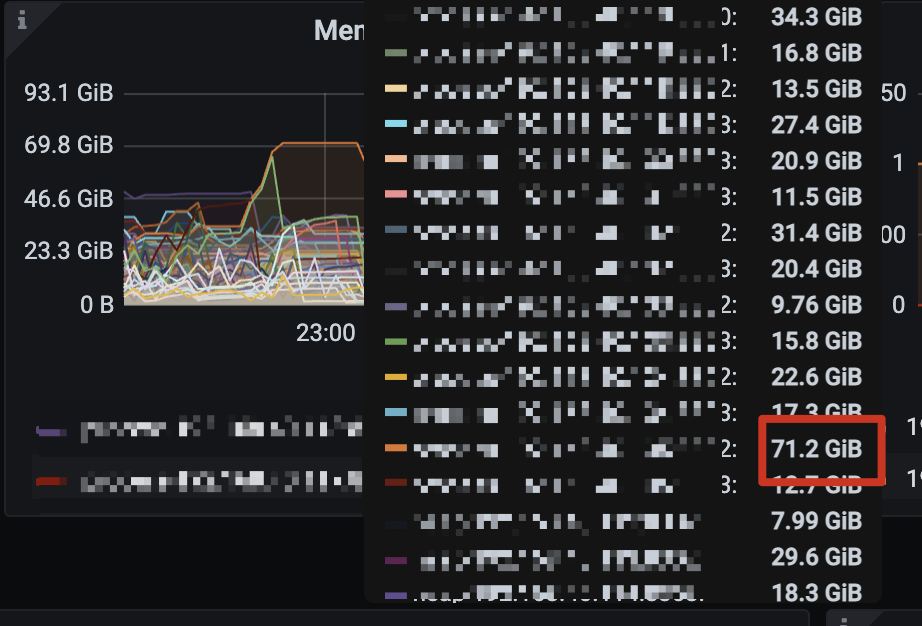
CDC consumes a lot of memory and is always killed by OOM. This issue did not occur in v6.5.1, where memory consumption was not as high as in this version.
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
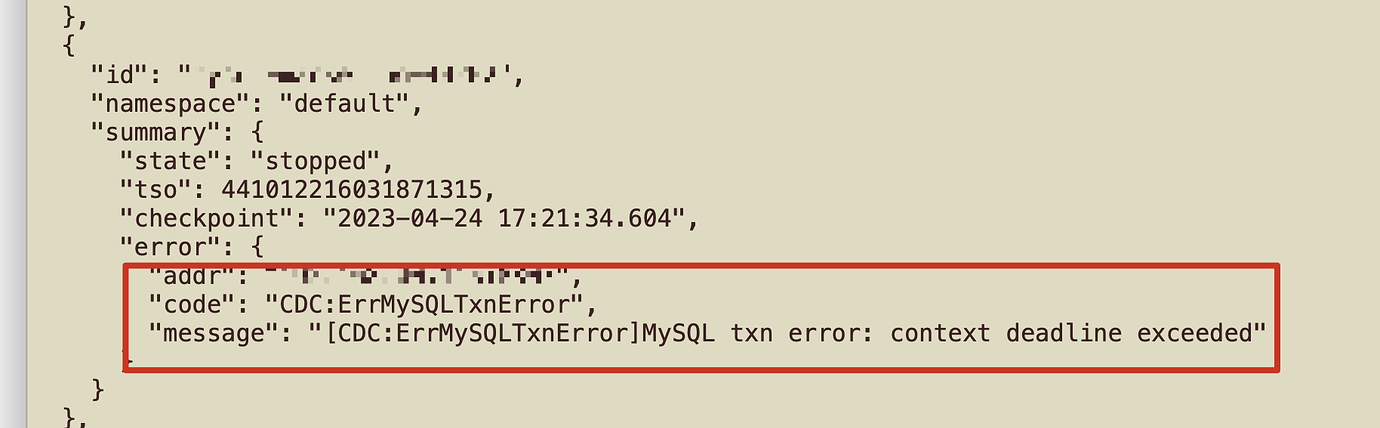
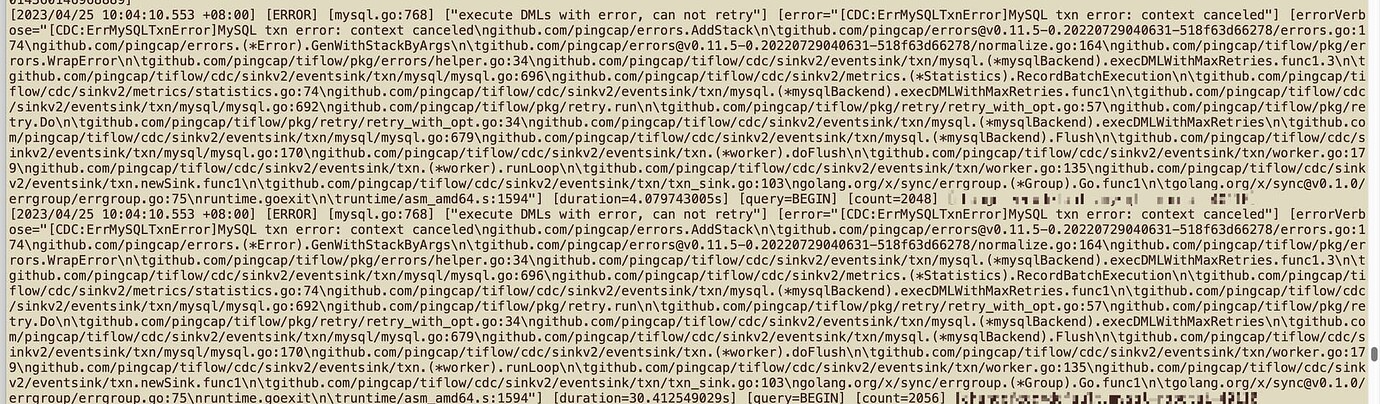
– CDC logs report this error
This error seems to be caused by the downstream scenario not being supported.
Does TiDB have any settings for splitting large transactions? This is to ensure that MySQL won’t encounter issues due to excessively large transactions when receiving them…
The default is empty, which means it is split by default. The downstream remains unchanged as MySQL, and the upstream is upgraded from 6.5.1 to 6.5.2.
Check if the downstream MySQL is functioning normally, look at the logs, and compare if the events occurred at the same time.
Also, check if there are any errors on the MySQL side.
Changing max-txn-row from 5000 to 100 solved the problem.
However, the memory usage of each CDC server is still very high and prone to OOM. Which parameter can control the memory usage of the CDC server?
Then we need to analyze whether the matching between changefeed and resources is sufficient.
-
Check if there is a significant synchronization delay causing data to accumulate in memory.
TiCDC 详细监控指标 | PingCAP 文档中心
-
Check which tasks are causing abnormal accumulation.
TiCDC 详细监控指标 | PingCAP 文档中心
-
If resources are indeed insufficient, then we can only consider scaling up.
There is indeed a delay now, more than a day, but I remember that the memory usage in the previous version v.6.5.1 was not this high. Previously, it also took more than a day to recover from the delay.
Solving the latency issue will also resolve the memory issue 
This parameter causes an error when placed in the YAML file.
The parameter to control memory is: set memory-quota=xxx in the config of changefeed. Its default value is now 1G. How many changefeeds do you have? You can adjust it to be smaller.
Four changefeeds shouldn’t occupy more than 80GB.
How to configure this parameter
This parameter causes an error when placed in the yaml file
Use the parameter I mentioned above for the changefeed configuration, not the server configuration: memory-quota=xxx.
Is the lag significant after the upgrade?
Memory usage is much higher than 6.5.1, previously it didn’t reach over 80GB. Let’s wait until it catches up and then check the latency, it should be similar.
I know, but now the cdc_server has this parameter per-table-memory-quota, and I don’t know how to use it.
The parameter 6.5.2 is no longer effective. Sorry, the documentation is outdated. I’ll make the changes.
What is the configuration of your machine, and how many nodes have you deployed?