Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: TiCDC双Sink同步增量备份到S3速度慢
[TiDB Usage Environment]
Production / Testing / Poc
[TiDB Version]
-
TiDB cluster version v5.4.0
-
TiCDC version is v5.3.0 (v5.4.0 does not support writing to S3, so we reverted to the old version v5.3.0)
/cdc version
Release Version: v5.3.0
Git Commit Hash: 8b816c9717a6d18430f93a6b212f3685c88d4607
Git Branch: HEAD
UTC Build Time: 2022-08-10 04:27:19
Go Version: go version go1.16.13 linux/amd64
Failpoint Build: false
[Reproduction Path] Operations performed that led to the issue
[Encountered Issue: Problem Phenomenon and Impact]
- Initially, a master-slave cluster synchronization was deployed in a cluster. After tuning TiCDC, the sink TiDB QPS was optimized from 5k to a maximum of around 45k, with no bottleneck in TiDB cluster master-slave synchronization.
- Subsequently, in the same cluster, a new changefeed was started to achieve incremental backup to S3 to meet different backup needs.
A new TiCDC incremental synchronization task to S3 was created, but the synchronization QPS of this task was only around 4.5k, whereas the master-slave synchronization of the same database table could reach 27k.
From the task configuration, the upstream tables are exactly the same. The puller, sorter, and mounter of these two tasks are the same, with the difference being in the cdc sink.
The official documentation states that starting from TiDB v6.5.0, TiCDC supports saving row change events to storage services like S3.
Based on practical use, TiCDC in version v5.4.0 does not support writing to S3, so we use the old version v5.3.0 which does support it. Currently, the actual synchronization QPS to S3 is between 4k-5k.
Optimization attempts:
- Network optimization confirmed that the write latency between TiCDC nodes and S3 is below 100ms, so high network latency should not be an issue.
- Referencing [s3://bucket/prefix?worker-count=128&flush-interval=1m30s&file-size=33554432], adjusting parameters like worker-count did not improve the synchronization speed to S3.
- Expanding TiCDC nodes did not significantly improve synchronization speed.
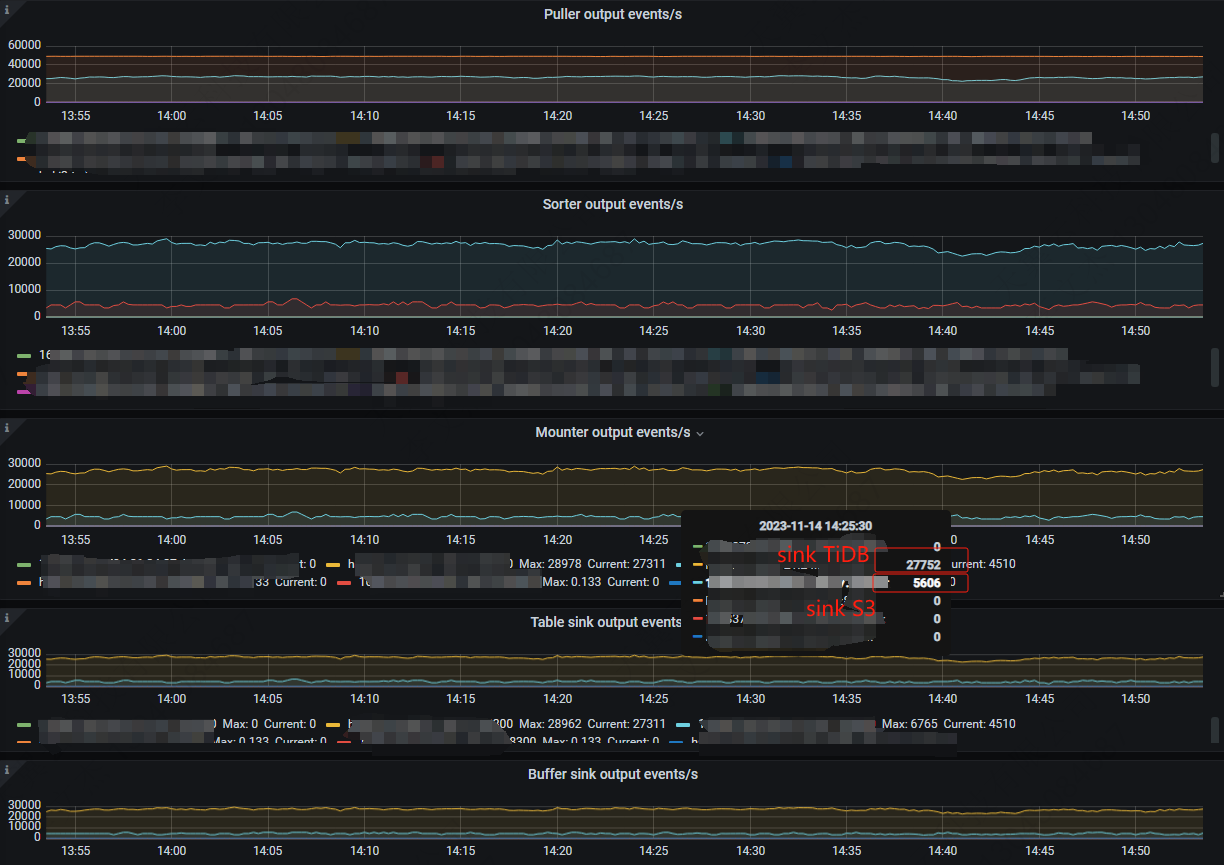
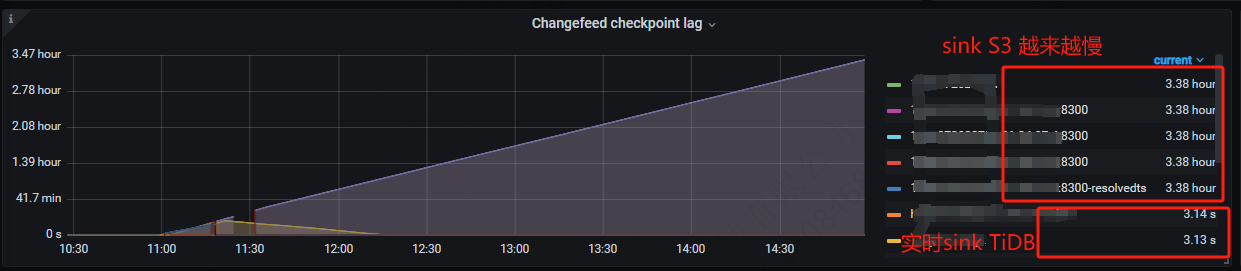
During operation, the cluster does not have memory, CPU, or IO performance bottlenecks. I would like to know if there are any other ways to improve the efficiency of writing to S3 in this version.
For example, when synchronizing lagging data, a set of comparison data can be seen:
For master-slave synchronization Sink TiDB: puller (xxx:8300-resolved 48k, xxx:8300-kv 25k) → sorter (36k) → mounter (36k) → sink (35k).
For incremental backup Sink S3: puller (xxx:8300-resolved 48k, xxx:8300-kv 25k) → sorter (4.5k) → mounter (4.5k) → sink (4.5k)
The suspected issue is that the sorter is relatively slow. Currently, the per-table-memory-quota is configured to 100MB.
[Resource Configuration]
Resource configuration is as follows:
CPU: amd64, 56 (112 vCore)
Memory: 512GB
Disk: 2.9TB NVME
10 Gigabit Network Card
Linux 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
Currently, TiCDC and PD are temporarily mixed. The cluster has 3 TiCDC nodes, with 2 TiKV deployed per machine. During testing and usage, machine resources were sufficient, with no resource bottlenecks.