[Overview] Scenario + Problem Overview
TiDB & PD mixed deployment with 3 nodes, TiCDC with 2 nodes, TiKV with 11 nodes.
In the afternoon, the 3 TiDB nodes in the cluster experienced OOM, causing many TiCDC tasks to stall. The background continuously logs:
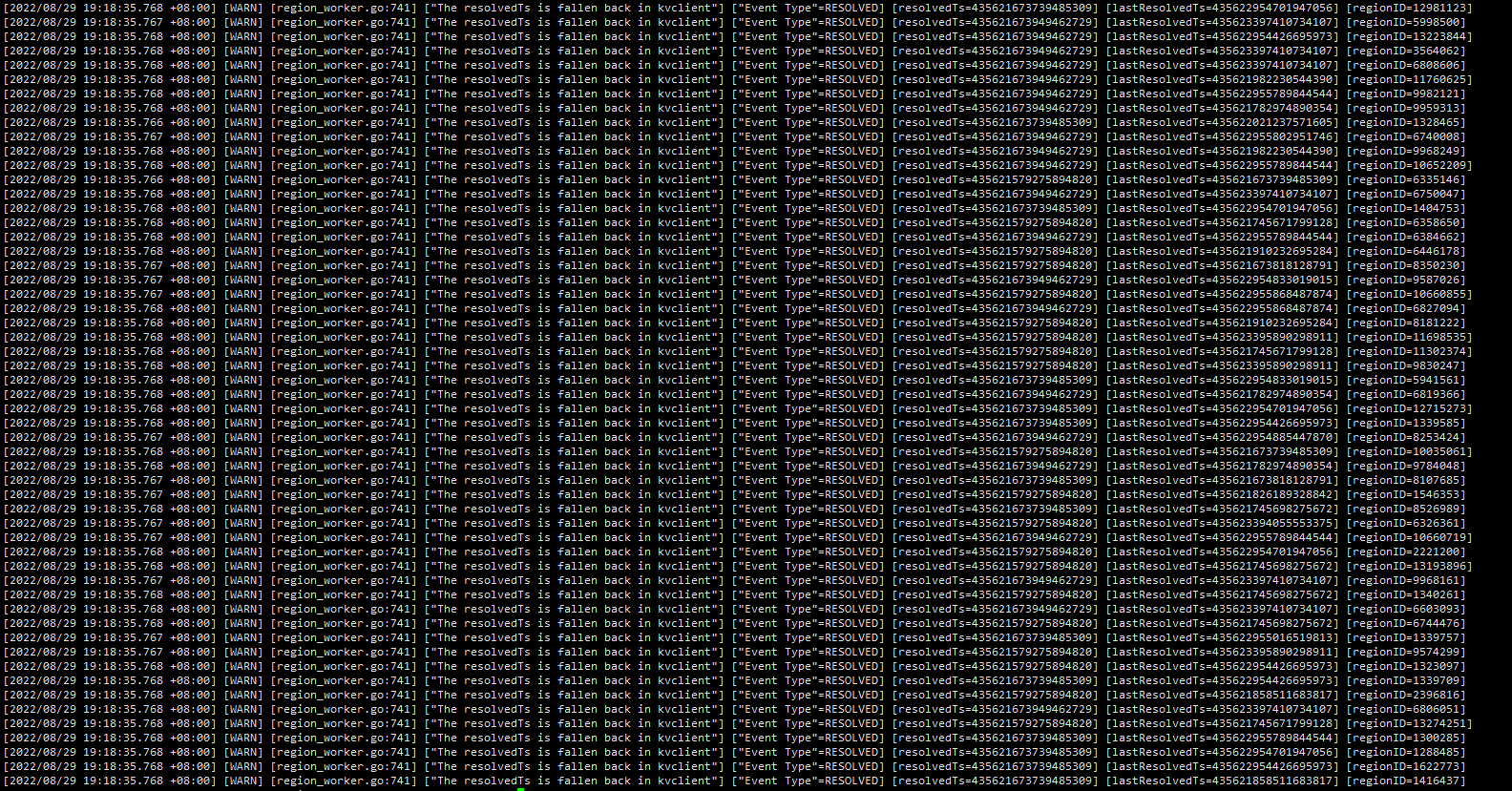
The resolvedTs is fallen back in kvclient
Issue occurred in versions: v4.0.9, v4.0.13, v5.1.2
After the Tidb server experienced an OOM, the ticdc checkpointTs did not advance. Attempting to pause the changefeed did not resolve the issue, and restarting the cdc component using tiup also did not help.
The ticdc logs showed numerous warning messages:
[2022/01/30 11:17:55.761 +08:00] [WARN] [region_worker.go:377] [“region not receiving resolved event from tikv or resolved ts is not pushing for too long time, try to resolve lock”] [regionID=40982339] [span=“[7480000000000016ffa05f72f000000019ff3a9b7b0000000000fa, 7480000000000016ffa05f72f000000019ff7319ad0000000000fa)”] [duration=17m21.65s] [lastEvent=93.273628ms] [resolvedTs=430836713476849684]
[2022/01/30 11:17:55.771 +08:00] [WARN] [region_worker.go:743] [“The resolvedTs is fallen back in kvclient”] [“Event Type”=RESOLVED] [resolvedTs=430836713699672811] [lastResolvedTs=430836984350245604] [regionID=31134532]
TiDB server OOM monitoring
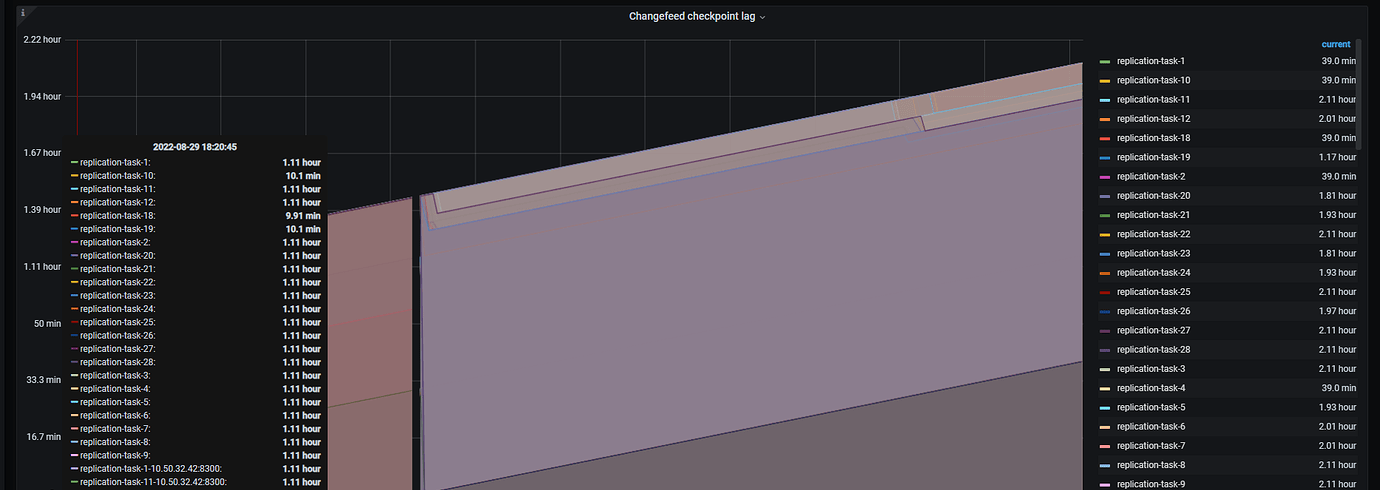
Tidb cdc monitoring
Issue Investigation
Investigation of TiDB server OOM cause
From the related slow queries
The preliminary investigation result is that the R&D team querying the dashboard slow query page caused the tidb server to OOM.
The dashboard’s slow query page causing OOM has occurred multiple times from version 4.0 to 5.1.2, and the issue still exists in the current version. It will be fixed in future versions.
Current mitigation measures:
Minimize the number of slow-log files, such as regularly archiving and deleting slow logs or setting log.file.max-days, and increasing the slow query threshold log.slow-threshold.
When querying, select a smaller time range, such as within one hour, and try to avoid concurrent slow query searches by multiple users.
Avoid using the order by sorting function when querying.
Currently, tidb provides an OOM tracker tool for analyzing OOM issues, which can record the top memory SQL and heap statistics in the tmp directory of the tidb server for analysis. Compared to previous versions, troubleshooting is relatively simpler and easier.
Investigation of TiCDC issue
From the monitoring, it can be seen that after the tidb server OOM, the resolved-lag in some tikv nodes increased.
According to the cdc R&D personnel, tidb locks the related tables with optimistic or pessimistic locks during transactions. When the tidb server OOMs, the related locks are not released properly, and region merge will block the resolveLock function, causing the locks to not be released.
This issue has been fixed in the latest version 5.1.4.
Issue Handling
Versions 5.1.4 and later
The issue of the cdc process checkpointTs not advancing after the tidb server OOM can be resolved without special handling.
Versions before 5.1.4 require manual handling
Workaround:
In a previous similar issue, using select count(*) from tb_name to perform a count operation on the table released the related locks.
However, there may be cases where the count operation does not resolve the issue.
If it is a pessimistic lock, select count cannot unlock it, and the lock may exist on the index. In this case, use index needs to be used, i.e., count each index once.
How to determine if the lock is released after the count
If after the count(*) operation, starting the changefeed process and seeing a large number of “The resolvedTs is fallen back in kvclient” logs in the cdc log, it indicates that the lock has not been released. It is recommended to pause the problematic link before releasing the lock, as the problematic link can cause the checkpointTs of the normal link to not advance.
Issue fix: The kv client has a problem with the logic of triggering resolved lock, which cannot be triggered in time. For details, see:
Minimize your configuration as much as possible, such as the number of TiCDC nodes, the number of synchronized tables, synchronization configuration parameters, etc., and then observe the situation.