Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: TICDC 同步 kafka 异常
【TiDB Usage Environment】Production Environment
【TiDB Version】v5.0.6
【Issue Description】
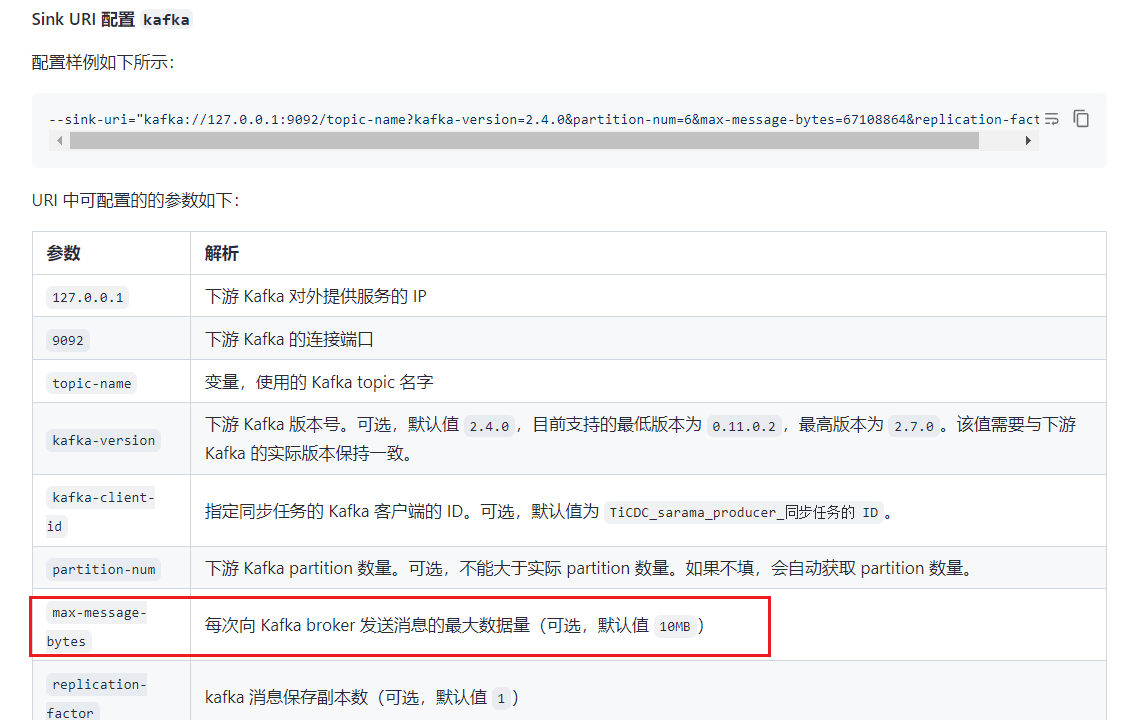
An error occurs when writing to Kafka, then modifying the Kafka parameter max-message-bytes can restore it. When the same issue occurs again, modifying the Kafka max-message-bytes parameter is needed again. Changing the max-message-bytes parameter to either larger or smaller can restore synchronization.
【Error Message】
[2024/06/03 20:59:52.366 +08:00] [WARN] [json.go:404] [“Single message too large”] [max-message-size=10485880] [length=10560460] [table=db_name.table_name]
[2024/06/03 20:59:52.443 +08:00] [ERROR] [processor.go:305] [“error on running processor”] [capture=xx.xx.xx.xx:8300] [changefeed=task-xxx-xxx-kafka-v2] [error=“[CDC:ErrJSONCodecRowTooLarge]json codec single row too large”] [errorVerbose=“[CDC:ErrJSONCodecRowTooLarge]json codec single row too large\ngithub.com/pingcap/errors.AddStack\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/errors.go:174\ngithub.com/pingcap/errors.(*Error).GenWithStackByArgs\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/normalize.go:156\ngithub.com/pingcap/tiflow/cdc/sink/codec.(*JSONEventBatchEncoder).AppendRowChangedEvent\n\tgithub.com/pingcap/tiflow@/cdc/sink/codec/json.go:406\ngithub.com/pingcap/tiflow/cdc/sink.(*mqSink).runWorker\n\tgithub.com/pingcap/tiflow@/cdc/sink/mq.go:353\ngithub.com/pingcap/tiflow/cdc/sink.(*mqSink).run.func1\n\tgithub.com/pingcap/tiflow@/cdc/sink/mq.go:282\ngolang.org/x/sync/errgroup.(*Group).Go.func1\n\tgolang.org/x/sync@v0.0.0-20201020160332-67f06af15bc9/errgroup/errgroup.go:57\nruntime.goexit\n\truntime/asm_amd64.s:1357”]
[2024/06/03 20:59:52.443 +08:00] [ERROR] [processor.go:144] [“run processor failed”] [changefeed=task-xxx-xxx-kafka-v2] [capture=xx.xx.xx.xx:8300] [error=“[CDC:ErrJSONCodecRowTooLarge]json codec single row too large”] [errorVerbose=“[CDC:ErrJSONCodecRowTooLarge]json codec single row too large\ngithub.com/pingcap/errors.AddStack\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/errors.go:174\ngithub.com/pingcap/errors.(*Error).GenWithStackByArgs\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/normalize.go:156\ngithub.com/pingcap/tiflow/cdc/sink/codec.(*JSONEventBatchEncoder).AppendRowChangedEvent\n\tgithub.com/pingcap/tiflow@/cdc/sink/codec/json.go:406\ngithub.com/pingcap/tiflow/cdc/sink.(*mqSink).runWorker\n\tgithub.com/pingcap/tiflow@/cdc/sink/mq.go:353\ngithub.com/pingcap/tiflow/cdc/sink.(*mqSink).run.func1\n\tgithub.com/pingcap/tiflow@/cdc/sink/mq.go:282\ngolang.org/x/sync/errgroup.(*Group).Go.func1\n\tgolang.org/x/sync@v0.0.0-20201020160332-67f06af15bc9/errgroup/errgroup.go:57\nruntime.goexit\n\truntime/asm_amd64.s:1357”]