Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiCDC同步进度停滞,sorter文件剧增
【TiDB Usage Environment】Production Environment
【TiDB Version】v5.3.0
【Encountered Problem】
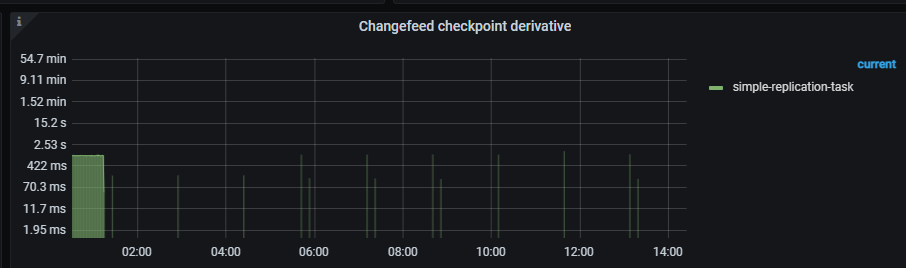
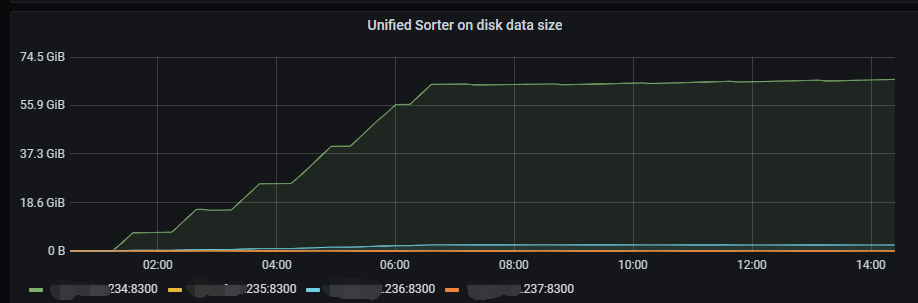
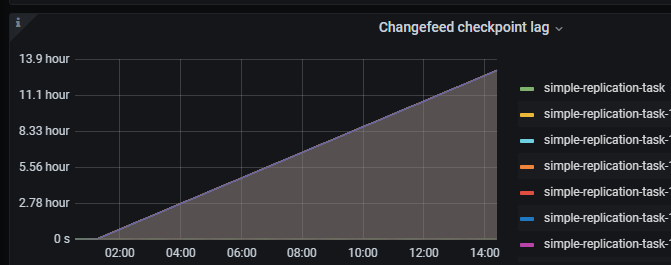
When using CDC for incremental synchronization, the checkpoint occasionally stalls and sometimes suddenly catches up. This issue occurred again yesterday, with the checkpoint remaining unchanged and the checkpoint lag reaching 13 hours. Additionally, the sorter of two CDCs increased significantly.
【Reproduction Path】
Operations performed that led to the issue
【Problem Phenomenon and Impact】
【Attachments】
- Relevant logs, configuration files, Grafana monitoring (https://metricstool.pingcap.com/)
- TiUP Cluster Display information
- TiUP Cluster Edit config information
- TiDB-Overview monitoring
- Corresponding module Grafana monitoring (if any, such as BR, TiDB-binlog, TiCDC, etc.)
- Corresponding module logs (including logs from 1 hour before and after the issue)
For questions related to performance optimization and fault troubleshooting, please download and run the script. Please select all and copy-paste the terminal output results for upload.
Check the cdc.log log, use cdc cli changefeed query -c xxx to query the status of the changefeed.
Yesterday’s query status was normal, and cdc.log kept showing “Unified Sorter: trying to create file backEnd.” Now the changefeed has failed, reporting this:
“message”: “[CDC:ErrGCTTLExceeded]the checkpoint-ts(436308863790350610) lag of the changefeed(simple-replication-task) has exceeded the GC TTL”
Because there was a period when a table had 8 million rows of data deleted, it caused one CDC node to have a high load, and the speed of flushing to the downstream couldn’t keep up. Then the checkpointTs of that node didn’t change and there were no errors reported. Is there any way to optimize this? Additionally, the network bandwidth from upstream to downstream is only 100M.
The v5.3.0 version of CDC does not support large transactions. It is recommended that when using CDC for synchronization, the transaction size should not exceed 100MB; otherwise, it will severely slow down the synchronization process and may eventually lead to synchronization failure. If possible, consider using the v6.1.1 version of CDC and enable the large transaction splitting feature, which can effectively solve the above problem.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.