Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tidb5.4.2系统表崩溃 SELECT * FROM INFORMATION_SCHEMA.TABLES limit 3 都卡死
【TiDB Usage Environment】Production
【TiDB Version】5.4.2
【Encountered Problem】
Backup log anomaly in the early morning, found the following error:
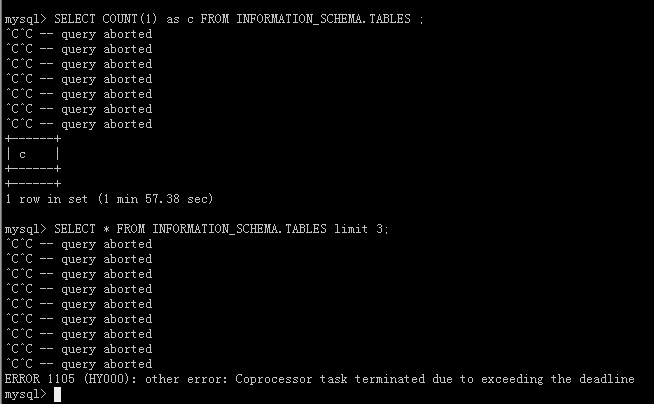
dump failed: sql: SELECT COUNT(1) as c FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=‘SEQUENCE’: invalid connection
Tried to query the table but got no response.
SELECT * FROM INFORMATION_SCHEMA.TABLES limit 3;
SELECT count(1) FROM INFORMATION_SCHEMA.TABLES;
[root@xxx-xxx223 tidblog]# grep terminated tidb.log |grep -i erro | more
[2022/09/10 10:24:09.397 +08:00] [WARN] [coprocessor.go:970] [“other error”] [conn=484791] [txnStartTS=435886730364583943] [regionID=36387611] [storeAddr=xxx.xx.xx.158:20160] [error=“other error: Coprocessor task terminated due to exceeding the deadline”]
[2022/09/10 10:24:09.398 +08:00] [INFO] [conn.go:1117] [“command dispatched failed”] [conn=484791] [connInfo=“id:484791, addr:127.0.0.1:58723 status:10, collation:utf8_general_ci, user:tidbdba”] [command=Query] [status=“inTxn:0, autocommit:1”] [sql=“SELECT * FROM INFORMATION_SCHEMA.TABLES limit 3”] [txn_mode=PESSIMISTIC] [err=“other error: Coprocessor task terminated due to exceeding the deadline
github.com/pingcap/tidb/store/copr.(*copIteratorWorker).handleCopResponse
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/store/copr/coprocessor.go:969
github.com/pingcap/tidb/store/copr.(*copIteratorWorker).handleTaskOnce
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/store/copr/coprocessor.go:784
github.com/pingcap/tidb/store/copr.(*copIteratorWorker).handleTask
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/store/copr/coprocessor.go:668
github.com/pingcap/tidb/store/copr.(*copIteratorWorker).run
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/store/copr/coprocessor.go:410
runtime.goexit
\t/usr/local/go/src/runtime/asm_amd64.s:1371”]
【Reproduction Path】What operations were done to cause the problem
【Problem Phenomenon and Impact】
System tables are unavailable, not sure what the impact will be on the production system.
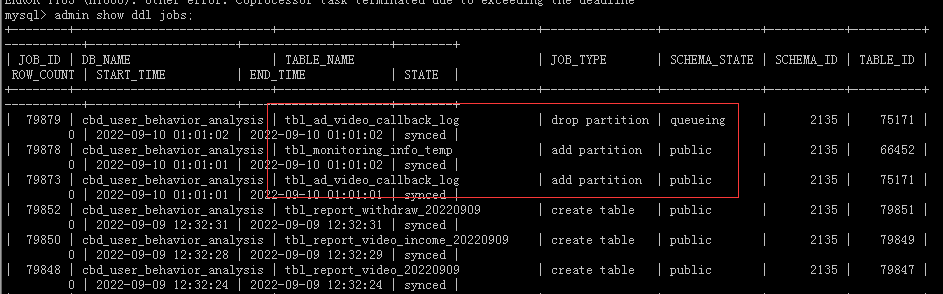
DDL was still normal at around 1 AM. Now it’s not advisable to operate DDL. There will be a batch of DDL operations at 11:30.