Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: TiDB 7.5 LTS 高性能数据批处理方案
Introduction
In the past, TiDB had some limitations due to its lack of support for stored procedures and large transactions, making complex batch data processing on TiDB somewhat complicated.
TiDB’s capabilities for handling such ultra-large-scale data batch processing scenarios have been continuously evolving, and its complexity has been significantly reduced:
- Starting from TiDB 5.0, TiFlash supports MPP parallel computing capabilities, greatly enhancing the performance of aggregation and join queries on large volumes of data.
- By TiDB 6.1, the BATCH DML feature was introduced, which can automatically split a large transaction into multiple batches for processing, significantly improving efficiency for large-scale updates, deletions, and inserts on a single table while avoiding some of the impacts of large transactions.
- In the 7.1 LTS version, the TiFlash query result materialization feature was officially GA, allowing complex select operations in insert/replace into … select … to leverage TiFlash MPP parallel processing capabilities, significantly improving performance.
- Recently, the 7.5 LTS version officially GA’d the IMPORT INTO feature, integrating the physical import capabilities of tidb-lightning into TiDB compute nodes, allowing large-scale data imports with a single SQL statement, greatly simplifying the complexity of ultra-large-scale data writes.
Previous Batch Processing Solutions on TiDB
1. INSERT INTO … SELECT for query and write
- Current status: Suitable for small batch data processing with high performance.
- Challenge: Large batch data writes can result in large transactions, consuming high memory.
- Note: For write + single table query scenarios, the BATCH DML feature can be used to automatically split batches.
2. Using batch interfaces for INSERT INTO/INSERT INTO … ON DUPLICATE …/REPLACE INTO SQL to reduce interactions between applications and the database, improving performance during batch writes
- Current status: High processing performance with appropriate batch splitting and table structure design.
- Challenge: Poor coding or table structure design can lead to hotspot issues, resulting in poor performance.
3. Using ETL and scheduling platforms to provide data read and write capabilities for large-scale data processing
- Current status: Mainstream ETL platforms like datax, spark, kettle, etc., have high performance with reasonable table structure design.
- Challenge: Difficult to multi-thread; multi-threaded parallel writes may also encounter hotspot issues.
4. Using LOAD DATA to write batch data from upstream CSV files, improving performance during batch writes
- Current status: High processing performance after splitting files and multi-threading.
- Challenge: LOAD DATA for a large file results in a large transaction, leading to poor performance; multi-threaded processing may also encounter hotspot issues, leading to poor performance.
We conducted a test on the above batch processing solutions and the newly introduced IMPORT INTO feature to explore which batch processing solution is the most efficient, consumes the least resources, and is the simplest to use.
Testing Different Batch Processing Solutions in TiDB
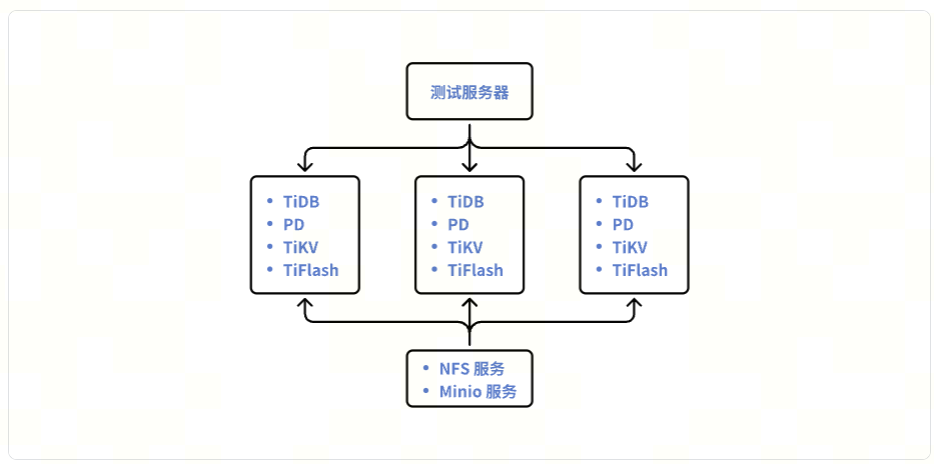
Test Environment
- TiDB resources: 3 virtual machines with 16VC/64GB + 500GB SSD cloud disk (3500 IOPS + 250MB/S read/write bandwidth)
- TiDB version: TiDB V7.5.0 LTS
- TiDB components: TiDB/PD/TiKV/TiFlash (mixed deployment)
- Storage resources: 8C/64GB virtual machine + 500GB SSD cloud disk (3500 IOPS + 250MB/S read/write bandwidth)
- Storage service: NFS service, Minio object storage
- Test resources: 8C/64GB virtual machine + 500GB SSD cloud disk (3500 IOPS + 250MB/S read/write bandwidth)
- datax + Dolphin scheduling/java program/dumpling, tidb-lightning tools, and MySQL client
Test Scenario
Quickly write large query results into the target table, testing both query performance and batch write performance.
Query Part: Multi-table Join + Aggregation
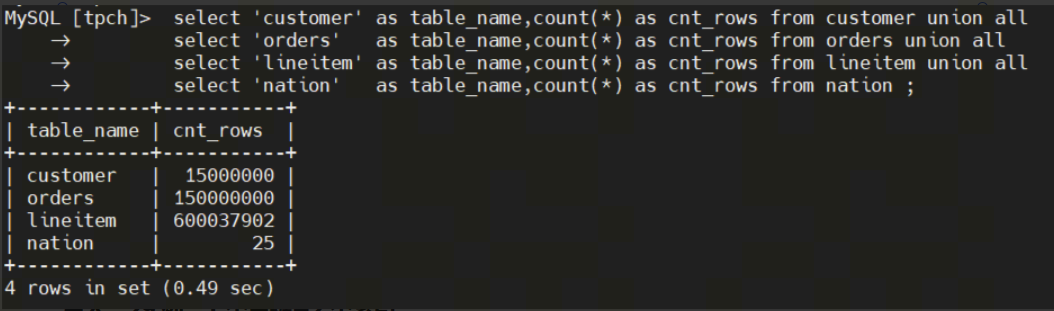
Based on TPCH 100GB data, extending the fields and query range in Q10 query, returning 8,344,700 rows of data.
select c_custkey,c_name,sum(l_extendedprice * (1 - l_discount)) as revenue,
c_acctbal,n_name,c_address,c_phone,c_comment,min(C_MKTSEGMENT),min(L_PARTKEY),
min(L_SUPPKEY,min(L_LINENUMBER),min(L_QUANTITY), max(L_TAX), max(L_LINESTATUS),
min(L_SHIPDATE), min(L_COMMITDATE), min(L_RECEIPTDATE), min(L_SHIPINSTRUCT),
max(L_SHIPMODE), max(O_ORDERSTATUS), min(O_TOTALPRICE), min(O_ORDERDATE),
max(O_ORDERPRIORITY), min(O_CLERK), max(O_SHIPPRIORITY),
@@hostname as etl_host,current_user() as etl_user,current_date() as etl_date
from
tpch.customer,tpch.orders,tpch.lineitem,tpch.nation
where
c_custkey = o_custkey and l_orderkey = o_orderkey
and o_orderdate >= date '1993-10-01' and o_orderdate < date '1994-10-01'
and l_returnflag = 'R' and c_nationkey = n_nationkey
group by
c_custkey,c_name,c_acctbal,c_phone,n_name,c_address,c_comment
order by c_custkey;
Source Table Data Volume
Write: 29 Columns, 1 Primary Key + 2 Indexes
CREATE TABLE `tpch_q10` (
`c_custkey` bigint(20) NOT NULL,
`c_name` varchar(25) DEFAULT NULL,
`revenue` decimal(15,4) DEFAULT NULL,
...
`etl_host` varchar(64) DEFAULT NULL,
`etl_user` varchar(64) DEFAULT NULL,
`etl_date` date DEFAULT NULL,
PRIMARY KEY (`c_custkey`) /*T![clustered_index] CLUSTERED */,
KEY `idx_orderdate` (`o_orderdate`),
KEY `idx_phone` (`c_phone`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
Test Results
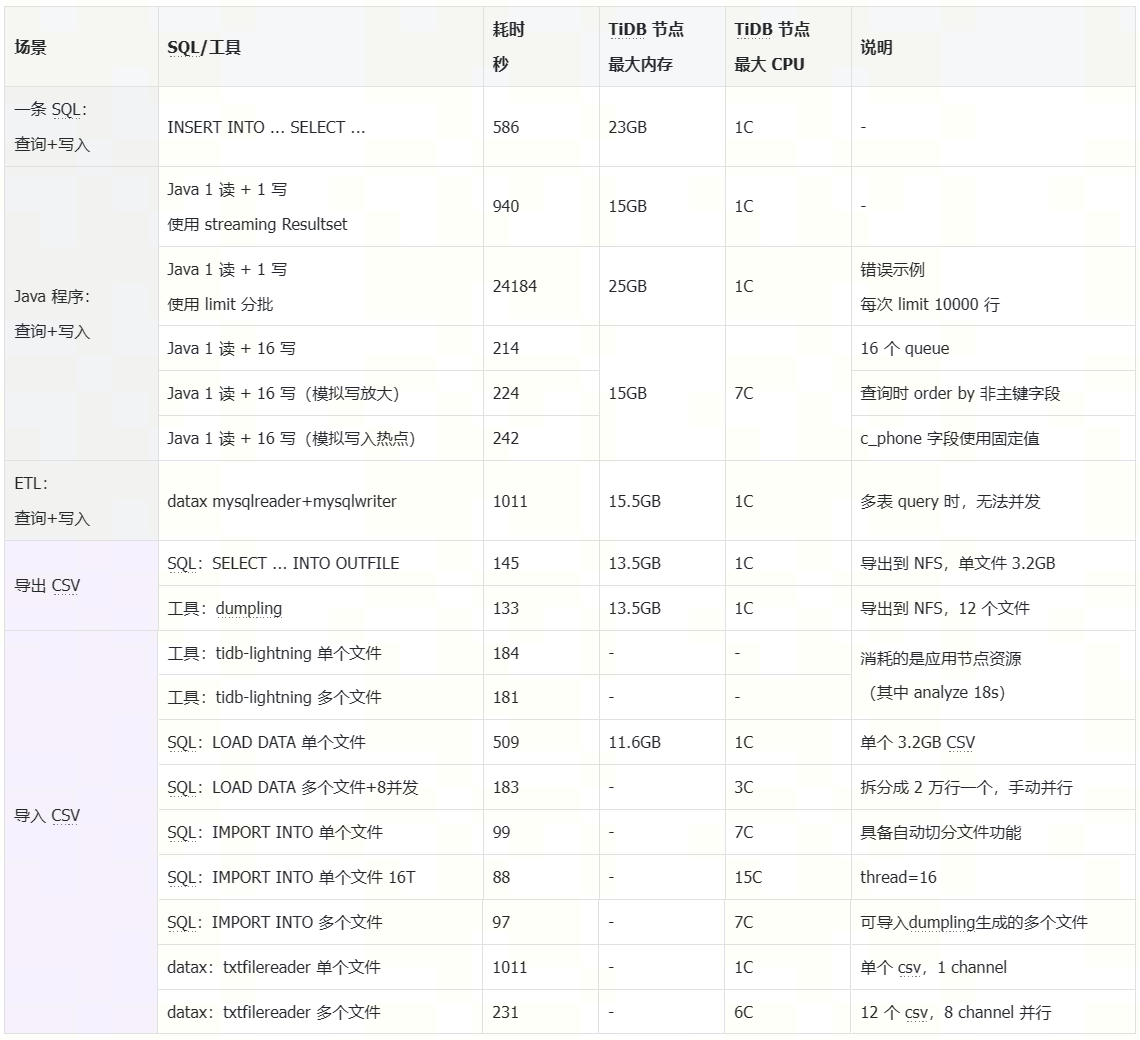
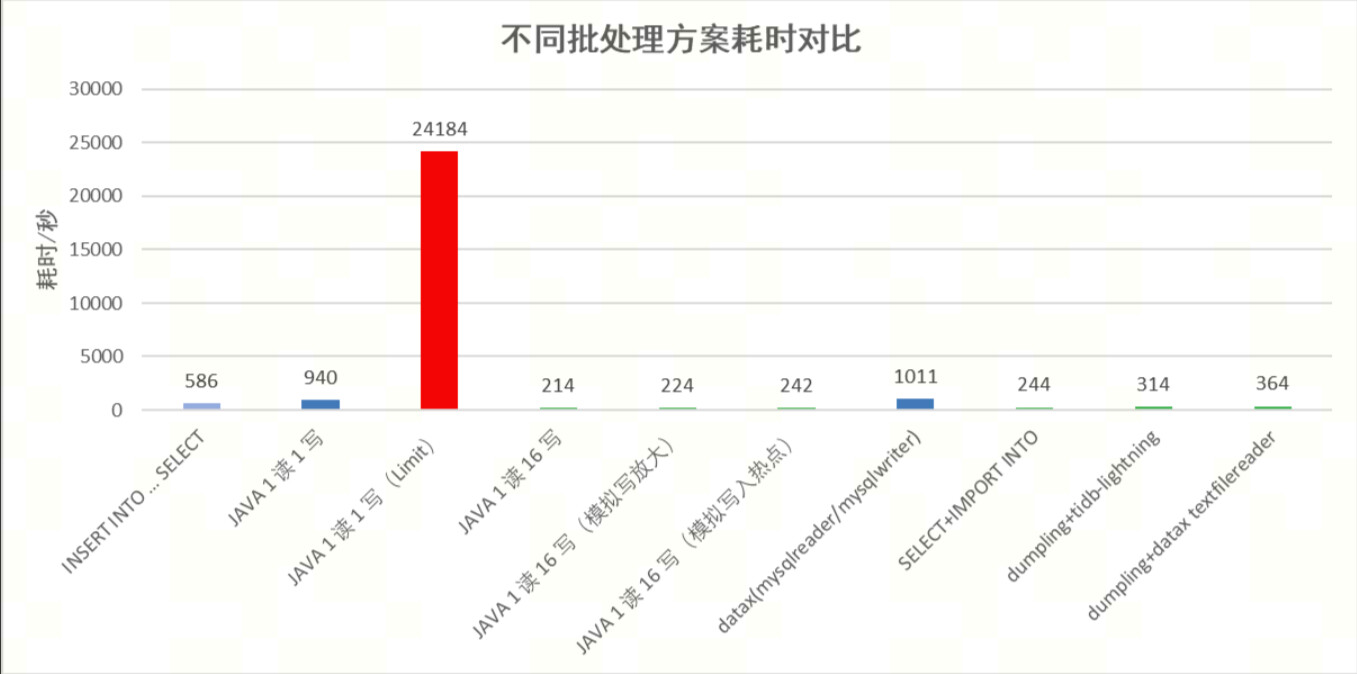
Test Analysis
-
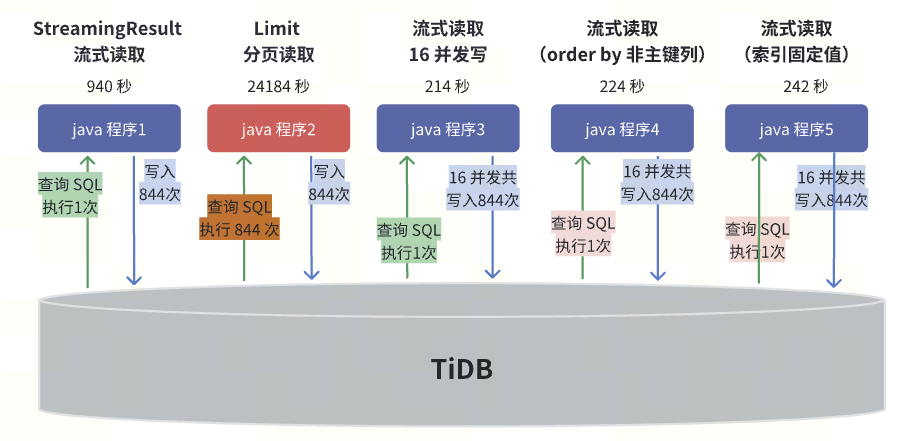
JAVA Program Using SQL for Batch Processing
-
When using JAVA, StreamingResult streaming read + multi-threaded write can achieve very good performance. Strongly discourage using limit pagination for batch splitting, as this logic will execute 844 query SQLs, with extremely low efficiency and high resource consumption. StreamingResult streaming read can also be used for data export scenarios, with higher efficiency compared to limit pagination processing.
-
In program 4, changing the order by c_custkey in the original query SQL to order by revenue desc had some impact on performance, mainly due to the significant increase in RPC overhead during multi-threaded writes.
-
In program 5, changing c_phone in the original query SQL to ‘132-0399-0111’ as c_phone simulated an index hotspot.
-
-
LOAD DATA Method
-
To achieve high performance with LOAD DATA, it is recommended to split a single file, and the order of the CSV file should match the primary key order of the target table. For example, storing 20,000 rows in a CSV file and then writing in parallel with multiple threads can achieve high write performance.
-
If only a single large file is imported with LOAD DATA, the performance is low, and memory consumption is high.
-
-
ETL + Scheduling Platform Method
-
Job Type: datax (mysqlreader + mysqlwriter), simple, average efficiency
- Scheduling platform executes datax job: When using mysqlreader to read, it defaults to streaming read, but for multi-table query queries, it cannot write concurrently.
-
Job Type: shell + datax (txtfileread + mysqlwriter), more complex, high efficiency
- Scheduling platform executes shell: Using dumpling to export into multiple CSV files.
- Then scheduling datax job: Using txtfilereader + mysqlwriter, allowing multi-threaded concurrent writes, with high efficiency.
-
Job Type: SQL, simple and efficient
- Scheduling platform executes SQL: select … into outfile.
- Scheduling platform executes SQL: import into.
-
SELECT … INTO OUTFILE to Export Query Results (currently only supports export to file system)
This feature may be less commonly used, but it is very valuable. It can efficiently export data in batches, and the data is in a completely consistent state, which can be used for:
- Batch data processing: JAVA programs can directly execute this SQL to complete the export of results.
- In simple data export scenarios, using export CSV to replace the original limit processing logic, the application exports the query results to a shared NFS/S3 object storage, then reads the CSV from NFS/S3 object storage for result processing, greatly reducing database pressure and achieving higher performance compared to limit batch processing.
-
IMPORT INTO to Import CSV (currently supports S3 protocol object storage and file system)
This feature introduced in 7.5.0 greatly simplifies data import complexity. JAVA programs can directly execute this SQL to complete CSV data import. During batch processing, application nodes almost do not consume CPU/memory resources. Here is an example of usage:
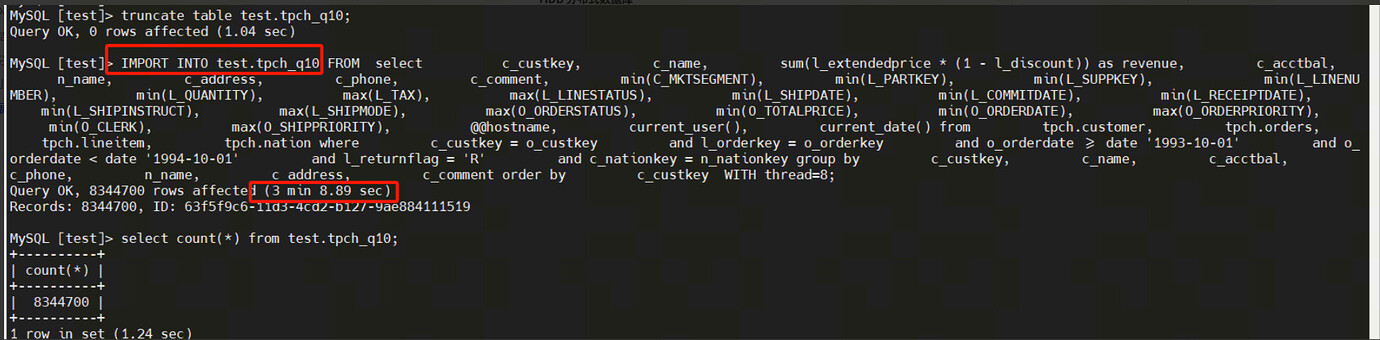
IMPORT INTO test.tpch_q10 FROM '/mnt/nfs/test.tpch_q10.csv' with FIELDS_TERMINATED_BY='\t',split_file,thread=8;Note: IMPORT INTO does not generate logs during the import process, so this solution is not suitable for scenarios requiring CDC synchronization or Kafka distribution.
Test Summary
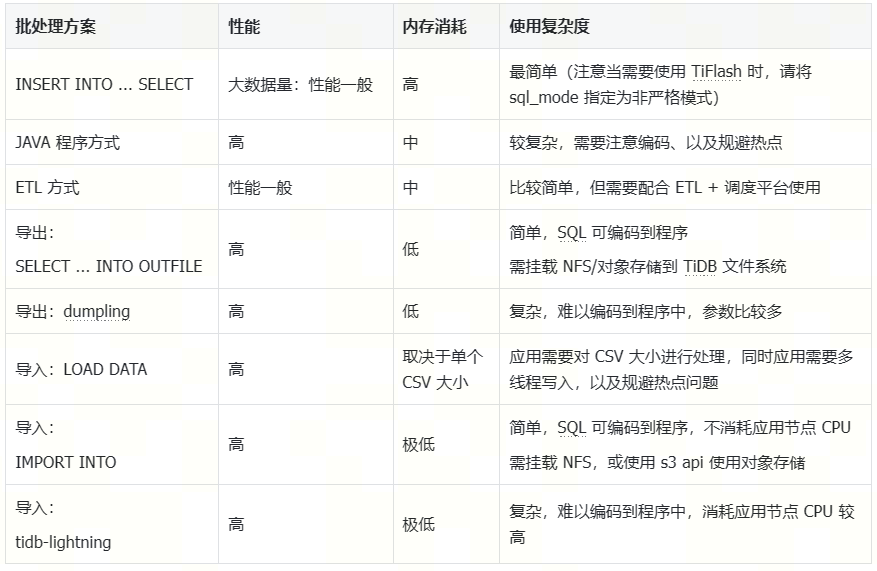
Some test code examples: GitHub - Bowen-Tang/batch-samples
Summary and Outlook
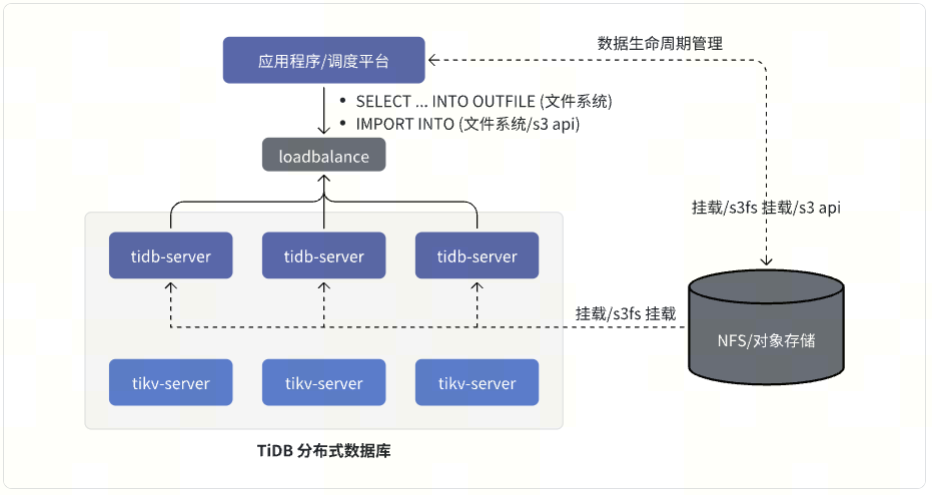
The IMPORT INTO feature introduced in TiDB 7.5.0, combined with SELECT … INTO OUTFILE and NFS/object storage, adds a simpler and highly efficient batch processing solution to TiDB. JAVA application processing becomes simpler, and ETL scheduling is also simplified.
Below is an architecture example of using IMPORT INTO and SELECT … INTO OUTFILE in TiDB:
Currently, the IMPORT INTO feature only supports CSV import. In future TiDB 8.x versions, IMPORT INTO will directly integrate IMPORT INTO … SELECT … functionality, further simplifying batch processing operations and improving performance (187 seconds). Stay tuned: