Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tidb analyze table 用了3小时
tidb 5.0.3
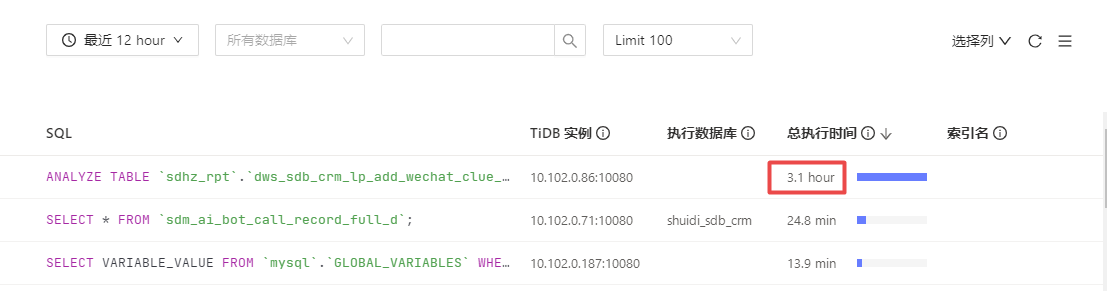
analyze table xxx; 270 million records, took 3 hours, why did it take so long?
Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tidb analyze table 用了3小时
tidb 5.0.3
analyze table xxx; 270 million records, took 3 hours, why did it take so long?
Executing the
ANALYZE TABLEstatement in TiDB takes longer than in MySQL or InnoDB. InnoDB samples only a small number of pages, but TiDB completely reconstructs a series of statistics. Scripts suitable for MySQL will mistakenly assume that executingANALYZE TABLEtakes a shorter time.
If resources are sufficient, you can adjust the concurrency of analyze.
Confirm whether this analyze is executed manually or by auto analyze. The concurrency parameters related to statistics collection for auto analyze are set to 1, so it will be slower if the data volume is large. Also, check the disk IO performance.
During off-peak hours, use the following system variables to improve analyze speed:
set @@session.tidb_distsql_scan_concurrency=60;
set @@session.tidb_index_serial_scan_concurrency=10;
set @@session.tidb_build_stats_concurrency=60;
It’s auto. Can this kind of auto be increased?
Disk IO is not high, usage is 20%.
This topic will be automatically closed 60 days after the last reply. No new replies are allowed.