Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tidb br 恢复 报错 context deadline exceeded
【TiDB Usage Environment】Production Environment / Testing / PoC
【TiDB Version】
【Reproduction Path】What operations were performed when the issue occurred
【Encountered Issue: Issue Phenomenon and Impact】
【Resource Configuration】
【Attachments: Screenshots/Logs/Monitoring】
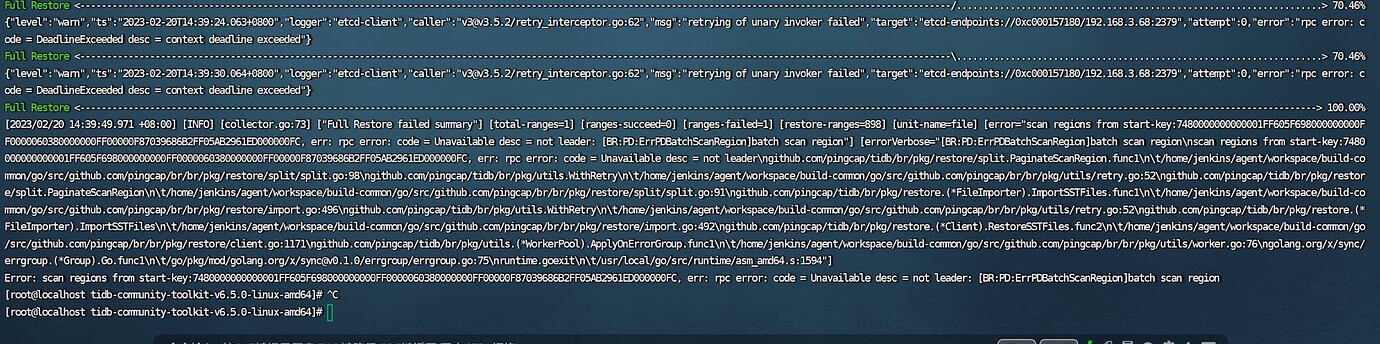
How should this be handled, experts? This error occurred during full restoration after a full backup, only the table structure and partial data were migrated.
Did the PD crash? Or is the network down?
None of them are completely normal.
Is the version of the br tool consistent with the version of the TiDB from which the data was backed up?
Consistent, I deleted the cluster data after backing it up, and it still doesn’t work when I try to restore it.
My configuration is 4 cores, 16GB, and 3 nodes.
Did it crash and restart during the recovery? I can’t see if it crashed during the recovery.
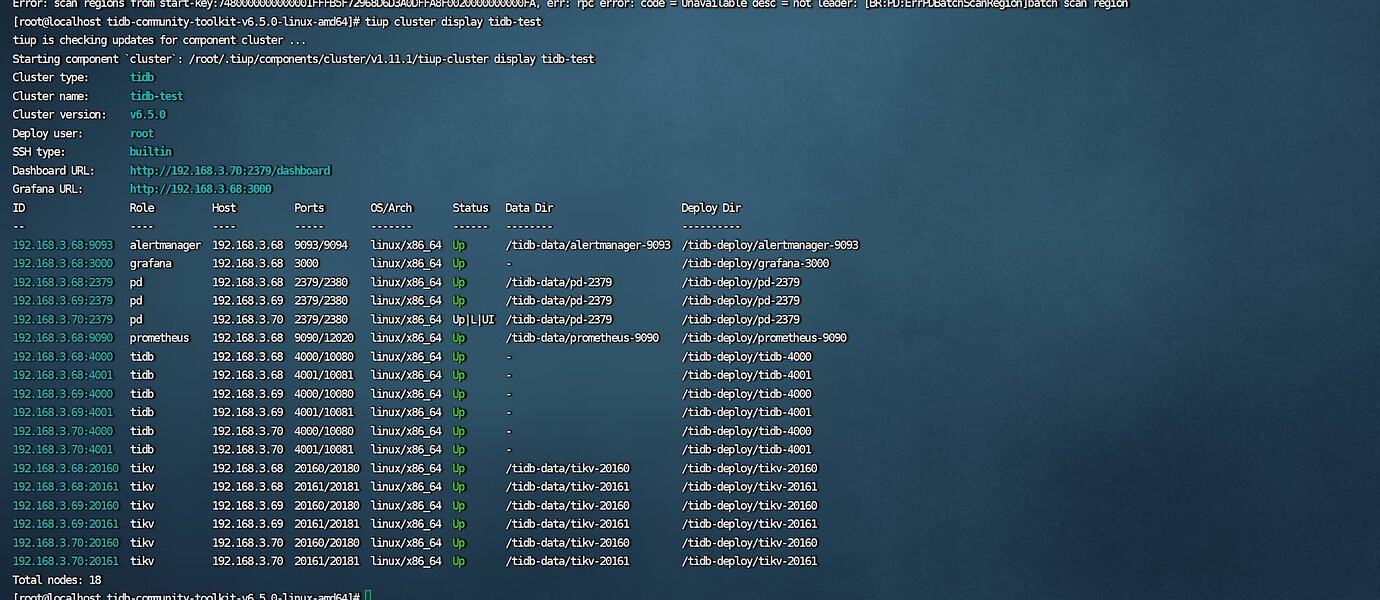
Check the cluster status.
The link you provided appears to be an image. Please provide the text content you need translated.
Restored once again, still the same.
The cluster PDs were all normal, and there were no PD failures during the recovery process.
Is there a parameter to set the timeout?
How did you delete the cluster data? It looks like there is an issue with the cluster. Try redeploying a new cluster.
I use the same configuration file for all clusters.
Deleting data means directly cleaning it out.