Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tidb 集群无法启动
【TiDB Environment】Production Environment
【TiDB Version】v5.2.2
【Encountered Issue】Unable to start the cluster after scaling down TiDB
【Reproduction Path】None
【Issue Phenomenon and Impact】
After scaling down TiDB, it reports that the region cannot be found, many processes are stuck, and then the cluster cannot be successfully restarted. The following logs were found, continuously searching for the already offline TiKV.
2022/10/02 01:05:42.761 +08:00] [WARN] [client_batch.go:503] [“init create streaming fail”] [target=172.16.120.9:20160] [forwardedHost=] [error=“context deadline exceeded”]
[2022/10/02 01:05:42.762 +08:00] [INFO] [region_cache.go:2251] [“[health check] check health error”] [store=172.16.120.9:20160] [error=“rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.120.9:20160: connect: connection refused"”]
[2022/10/02 01:05:42.762 +08:00] [INFO] [region_request.go:344] [“mark store’s regions need be refill”] [id=15698413] [addr=172.16.120.9:20160] [error=“context deadline exceeded”]
[2022/10/02 01:05:43.470 +08:00] [INFO] [coprocessor.go:812] [“[TIME_COP_PROCESS] resp_time:10.925106589s txnStartTS:436376416354041867 region_id:15666413 store_addr:172.16.120.9:20160 backoff_ms:1165 backoff_types:[regionScheduling,tikvRPC,tikvRPC,regionMiss,regionScheduling,tikvRPC,tikvRPC]”]
[2022/10/02 01:05:48.485 +08:00] [WARN] [client_batch.go:503] [“init create streaming fail”] [target=172.16.120.10:20161] [forwardedHost=] [error=“context deadline exceeded”]
[2022/10/02 01:05:48.486 +08:00] [INFO] [region_cache.go:2251] [“[health check] check health error”] [store=172.16.120.10:20161] [error=“rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.120.10:20161: connect: connection refused"”]
[2022/10/02 01:05:48.486 +08:00] [INFO] [region_request.go:344] [“mark store’s regions need be refill”] [id=15698410] [addr=172.16.120.10:20161] [error=“context deadline exceeded”]
[2022/10/02 01:05:54.494 +08:00] [WARN] [client_batch.go:503] [“init create streaming fail”] [target=172.16.120.9:20160] [forwardedHost=] [error=“context deadline exceeded”]
[2022/10/02 01:05:54.495 +08:00] [INFO] [region_cache.go:2251] [“[health check] check health error”] [store=172.16.120.9:20160] [error=“rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.120.9:20160: connect: connection refused"”]
[2022/10/02 01:05:54.495 +08:00] [INFO] [region_request.go:344] [“mark store’s regions need be refill”] [id=15698413] [addr=172.16.120.9:20160] [error=“context deadline exceeded”]
[2022/10/02 01:05:56.012 +08:00] [INFO] [coprocessor.go:812] [“[TIME_COP_PROCESS] resp_time:12.53678461s txnStartTS:436376416354041867 region_id:15666413 store_addr:172.16.120.9:20160 backoff_ms:3700 backoff_types:[regionScheduling,tikvRPC,tikvRPC,regionMiss,regionScheduling,tikvRPC,tikvRPC,regionMiss,regionScheduling,tikvRPC,tikvRPC]”]
[2022/10/02 01:06:01.038 +08:00] [WARN] [client_batch.go:503] [“init create streaming fail”] [target=172.16.120.10:20161] [forwardedHost=] [error=“context deadline exceeded”]
[2022/10/02 01:06:01.039 +08:00] [INFO] [region_cache.go:2251] [“[health check] check health error”] [store=172.16.120.10:20161] [error=“rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.120.10:20161: connect: connection refused"”]
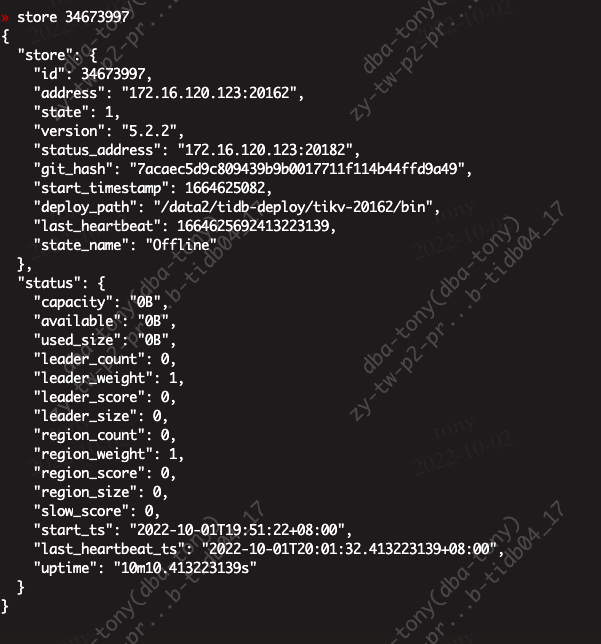
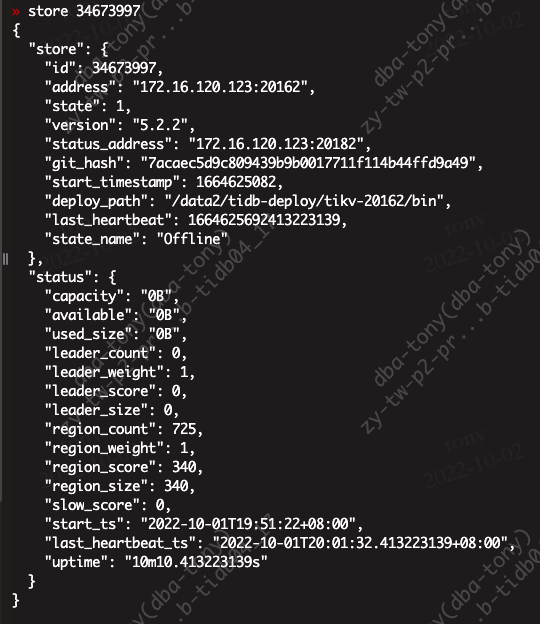
Found information in the store
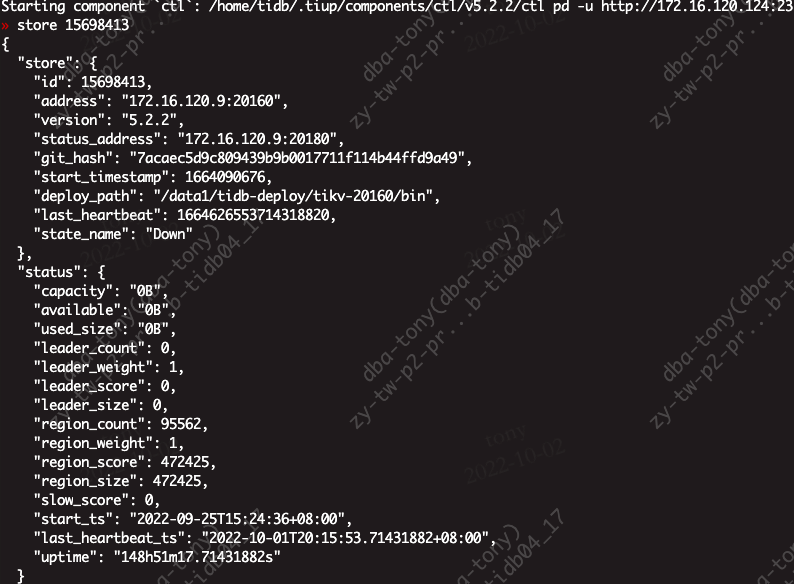
How to delete this information so that the cluster does not search for the already offline IPs when starting. I entered the pd-ctl interaction and manually executed store delete id, it showed success, but the store still contains the information. It was not deleted.