Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tidb集群莫名失联(疑似时间不同步引发)
【TiDB Usage Environment】Production environment
【TiDB Version】3.0.19
【Encountered Issue: Phenomenon and Impact】
Received an alert around 5 AM, indicating that all pd-servers in a cluster were collectively disconnected. Attempts to restart the cluster (failed) and restart the servers were futile.
【Resource Configuration】48c189m physical machine, 3-node pd cluster.
【Attachments: Screenshots/Logs/Monitoring】
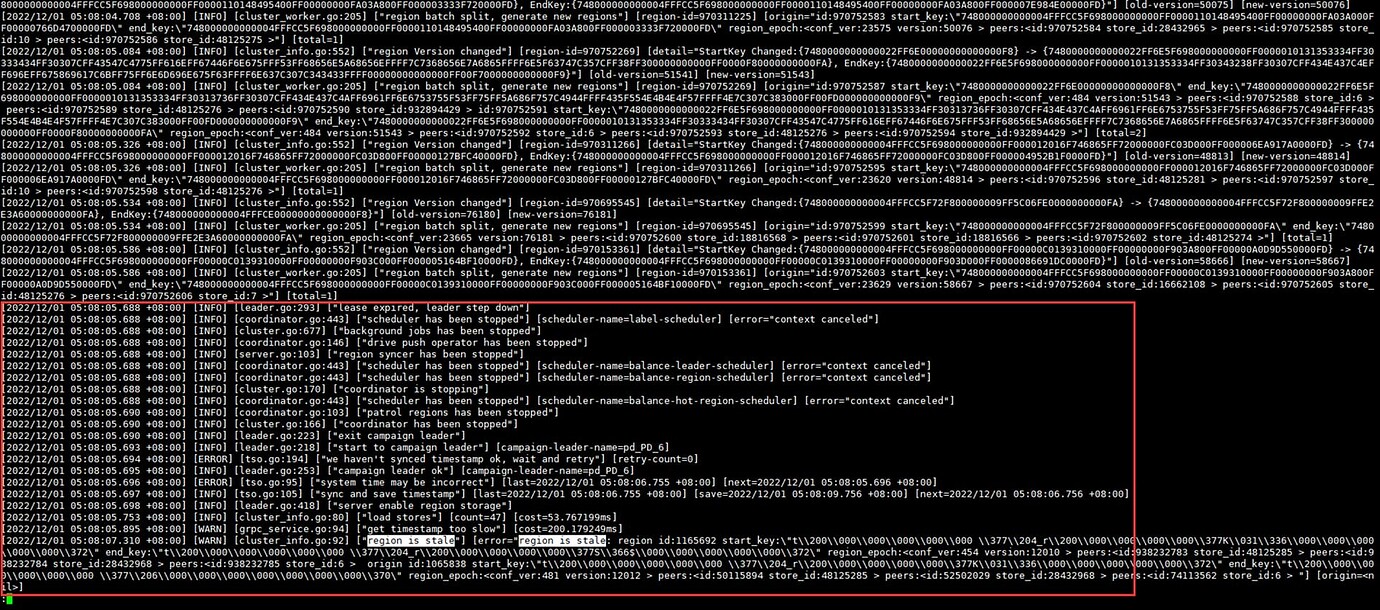
Around 5:08 AM, a leader election occurred, and pd_PD_6 remained the leader after the election:
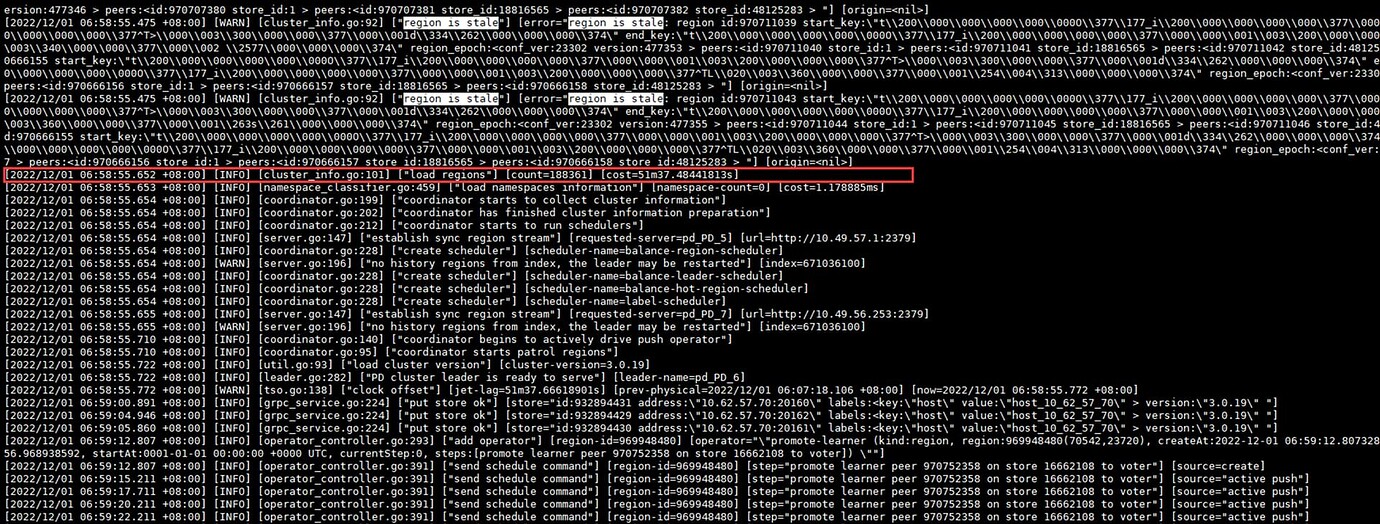
Subsequently, a load region process lasting approximately 51 minutes and 37 seconds occurred. The cluster only recovered after this process was completed (5:08-6:58 includes: incident occurrence → alert received → alert handling → final recovery, during which there were operations to restart the cluster and servers):
During the load region process, all logs were the “region is stale” error shown in the image above.
Preliminary suspicion is that the issue is caused by a time synchronization problem. Now there are three questions:
-
Was the issue caused by a time synchronization problem? If not, what other reasons could there be? What additional information is needed to investigate?
-
If it is a time synchronization issue, has it been fixed in versions after 3.0.19? (Because time synchronization issues will always occur, even if there is a time synchronization service)
-
When there are many regions, the load region process takes too long. Has this been optimized in later versions?
Subsequently, attempts to upgrade the version and restart pd still resulted in a long load region process, causing pd restart to fail. Currently, we can only wait for the load to complete before trying again, and the cluster is in an unusable state.
Question:
4. How can we achieve a smooth upgrade now? Previous upgrades from 3.0.19 did not encounter such long load times.
Try to upgrade to a higher version as much as possible. Most people no longer use the lower versions. Many issues cannot be reproduced without the same version, which will affect your efficiency in solving problems. Additionally, many issues in the lower versions have already been resolved in the higher versions. So, the answer to many of your queries might simply be: it’s a bug, and upgrading to a higher version will solve the problem.
3.0, indeed an old version. I hadn’t learned TiDB back then. 
 Just tried to upgrade, and during the startup process, the pd-leader continuously loaded regions, including some load retry operations. It took more than 3 hours without completion. After rolling back using the old pd binary file, the cluster status returned to normal, but it seems all accounts were lost… even root can’t log in
Just tried to upgrade, and during the startup process, the pd-leader continuously loaded regions, including some load retry operations. It took more than 3 hours without completion. After rolling back using the old pd binary file, the cluster status returned to normal, but it seems all accounts were lost… even root can’t log in 
Supplement:
The user loss was due to a version issue. Manually copying the tidb binary back to overwrite the failed 4.0.16 version and restarting resolved the issue.
The cluster is considered restored, but upgrading remains a major problem
Previously, I upgraded from version 3.0.19 to various 4.0 versions many times, with varying data sizes, some even larger than this one, and never encountered this load region issue. It feels like an isolated case, not a common phenomenon.
Currently, there are still 8 or 9 old 3.0 clusters running. Some are too large to upgrade easily, and some have not received any attention. We plan to schedule the upgrades in the near future.
Update:
After updating the time server of the time synchronization service chronyd to a valid value, it is now functioning normally. Initially, the time synchronization service was not modified because the time appeared to be synchronized by visual inspection.
Additionally:
Encountered an issue with the DDL job queue when upgrading to a higher version, How to force close all the ddl jobs · Issue #41099 · pingcap/tidb · GitHub, waiting for it to be addressed together.
[TiDB Version] 3.0.19, can be upgraded to v5.0 or v6.0. The versions used by everyone are similar, and some issues can be reproduced.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.