Hi Team,
I am using TiDB version 6.5.1 and I created a table which contains two indexes let’s say KEY msisdn_idx (msisdn),KEY s_date_idx (s_date) and when I am trying to query the table with s_date=? it’s showing full table scan in query plan, it’s not using index. I am attaching the DDL of table and query plan output, So please suggest.
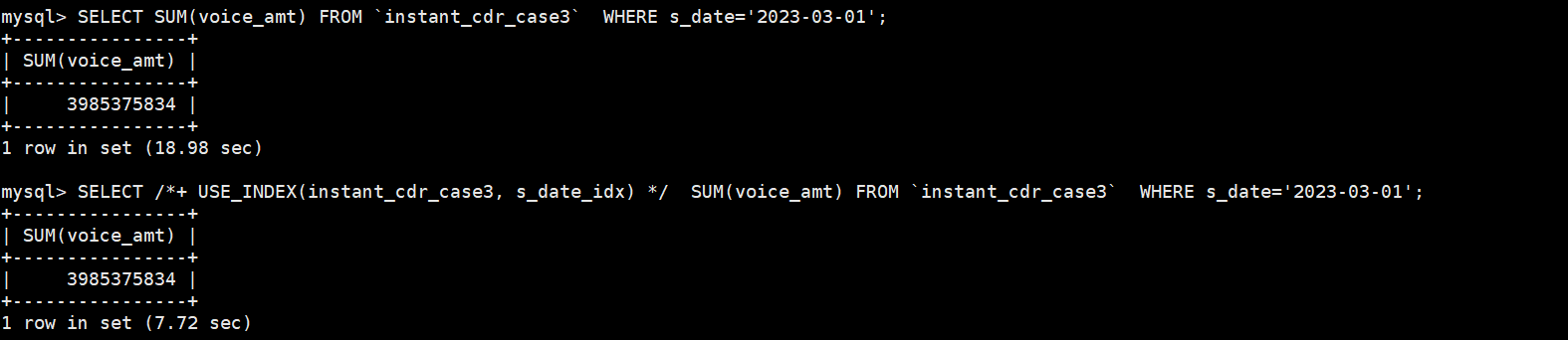
The query of SELECT SUM(voice_amt) FROM instant_cdr_case3 WHERE s_date='2023-03-01'; doesn’t use index s_date_idx(s_date) cause by the index s_date_idx selectivity too bad.
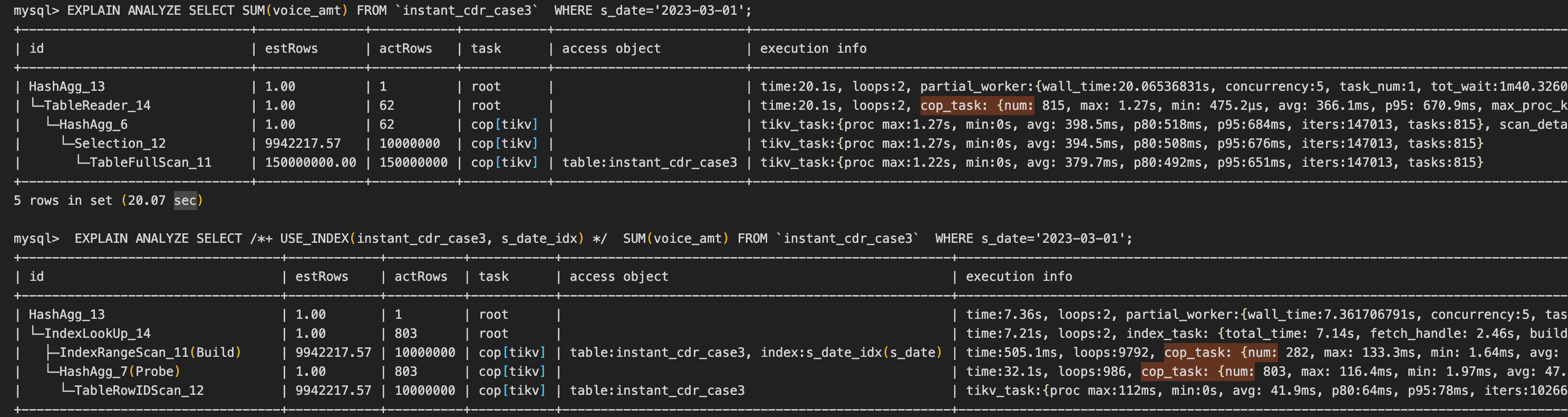
From the query plan, table instant_cdr_case3 has 150000000 rows, and there are 10000000 rows meet the condition s_date='2023-03-01', then the cost-based optimizer thinks the cost of the full-table scan is lower than the index-lookup scan.
here comparatively index was taking less time and queried data is around 6% of total data, why CBO is doing full table scan instead of index scan, is there any rules CBO follows, so that can use in table design for data.
Nice catch. I also noticed that querying using an index is actually faster. But index-lookup scan faster doesn’t indicate its cost is lower than full-table scan. Such as, index-lookup scan use 282 IndexRangeScan cop RPC requests and 803 TableRowIDScan cop RPC requests, but full-table scan only use 815 cop RPC requests, which is lower than index-lookup scan.
But the CBO cost model is very complicated, and it may be adjusted with version changes. When we do table design or query design, recommend prioritizing the following best practices:
Then in that case data size increases in particular index it will execute more tasks so it causes full table scan when query the index?
And I can use indexes only for point lookups or range scan which return few records?
In my case I have to store daily 10 million transaction for the last 90 days and when query where contains only transaction_date, so I have only option to create index for transaction_date, in this case how tidb deal?
Index is certainly useful. Index-scan definitely faster than full-table-scan. But IndexLookUp may not necessarily be faster than full-table-scan.
To some extent, what you said is correct. But TiDB will always use index if the index contains all data the query need, since index-scan definitely faster than full-table-scan.
To optimize the query SELECT SUM(voice_amt) FROM instant_cdr_case3 WHERE s_date='2023-03-01';, you can create a index on (s_date,voice_amt), TiDB will use the index-scan and executes much faster.
Then in that case data size increases in particular index it will execute more tasks so it causes full table scan when query the index?
And I can use indexes only for point lookups or range scan which return few records?
Sorry, I’ll try to answer it.
For question-1, I don’t understand what data size increases in particular index means. Everything is relative, in this situation, there are 10000000 rows meets the condition s_date='2023-03-01', but the total rows is 150000000 rows, so the TiDB planner think the full-table scan cost may lower than index-lookup scan. But if the total of rows increases by 1000 times(150000000*1000), but the index rows of the condition s_date='2023-03-01' is still 10000000. Then I think tidb planer will chose index-lookup-scan instead of full-table scan.
For question-2, I almost agree with you. An index is useful when it has good selectivity. Or if I only need to query the index column data, then full-index scan is also better than full-table scan.
And you can use the following SQL to check the plan cost:
explain format=verbose select /*+ IGNORE_INDEX(t, idx0) */ count(*) from t;
explain format=verbose select /*+ USE_INDEX(t, idx0) */ count(*) from t;
And the result is like this, The estCost columns indicate the plan cost. You can compare the estCost in different plans.
BTW, I think Partitioning table | PingCAP Docs is probably in your situation. Partition by s_date and query/delete/truncate partitions data would be more efficiently.
@Ajay_Babu Hi, Could you provide the PLAN REPLAYER information to help us improve the optimizer CBO model? This will be very useful for us to improve the optimizer. The relevant steps are:
Dump information into file:
PLAN REPLAYER DUMP EXPLAIN ANALYZE SELECT SUM(voice_amt) FROM `instant_cdr_case3` WHERE s_date='2023-03-01';
Based on sql-statement, TiDB sorts out and exports the following on-site information:
TiDB version
TiDB configuration
TiDB session variables
TiDB SQL bindings
The table schema in sql-statement
The statistics of the table in sql-statement
The result of EXPLAIN ANALYZE sql-statement
use the TiDB HTTP interface and the file identifier to download the file: