Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 断电后tidb启动不了
The power outage caused the issue, and my ability is limited. I can’t identify the problem from the logs.
Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 断电后tidb启动不了
The power outage caused the issue, and my ability is limited. I can’t identify the problem from the logs.
Check the log contents under /tidb-deploy/tikv-20161/log on 192.168.1.202.
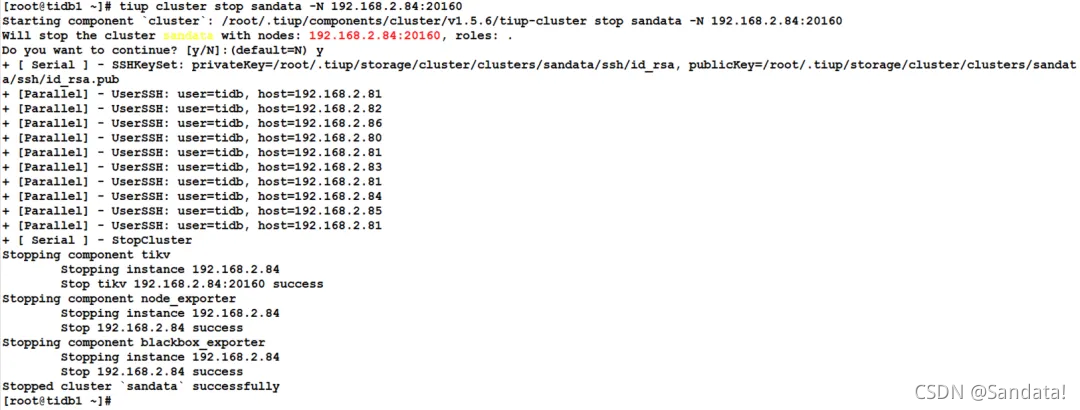
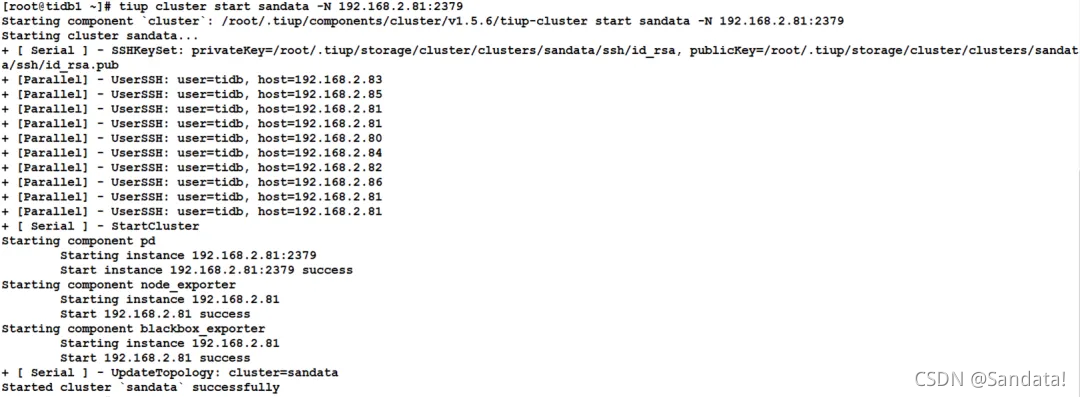
tiup cluster start sandata -N 192.168.2.84:2379
Normally, PD will be called up, and TiKV will start subsequently.
If you deploy all tasks on a single machine, it is recommended to increase the machine’s memory to around 64GB, as there might be OOM issues during startup.
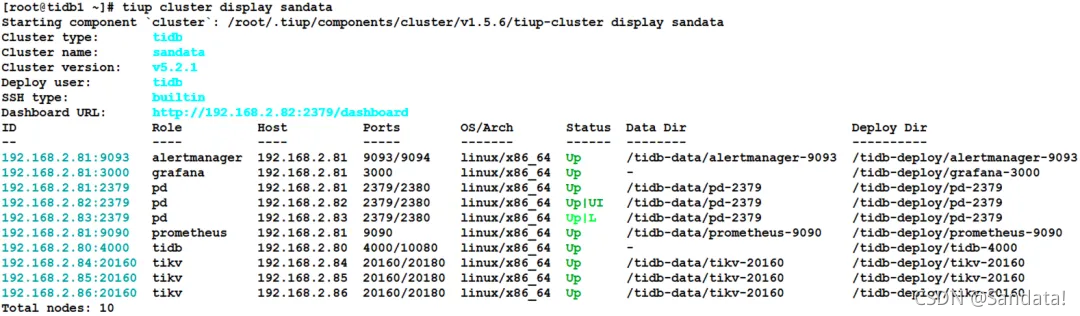
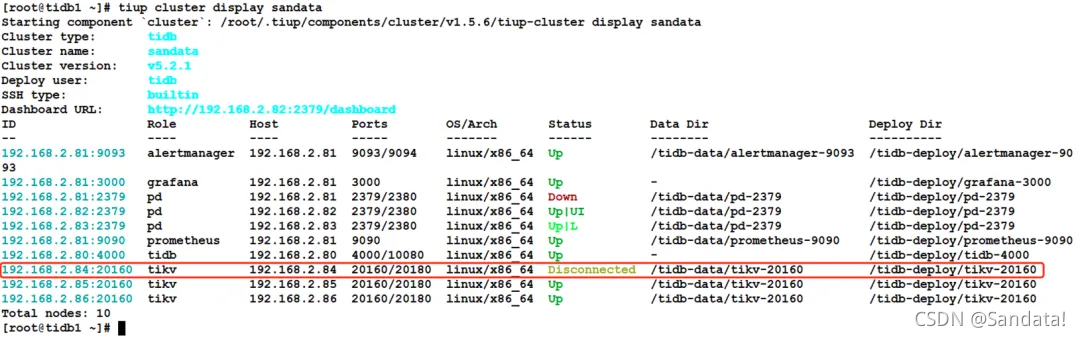
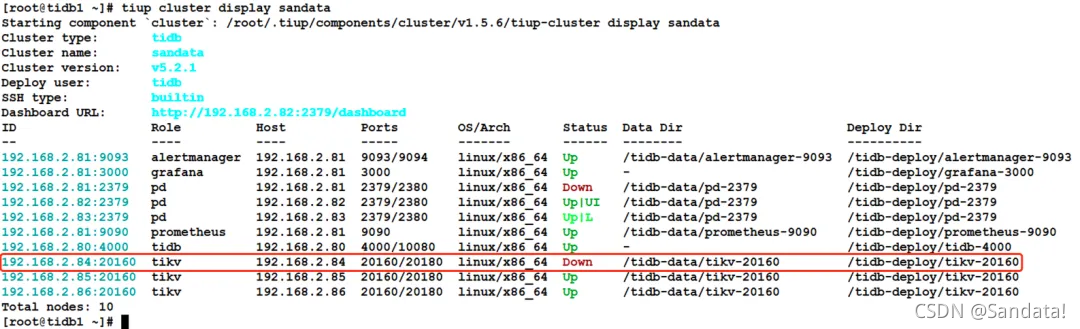
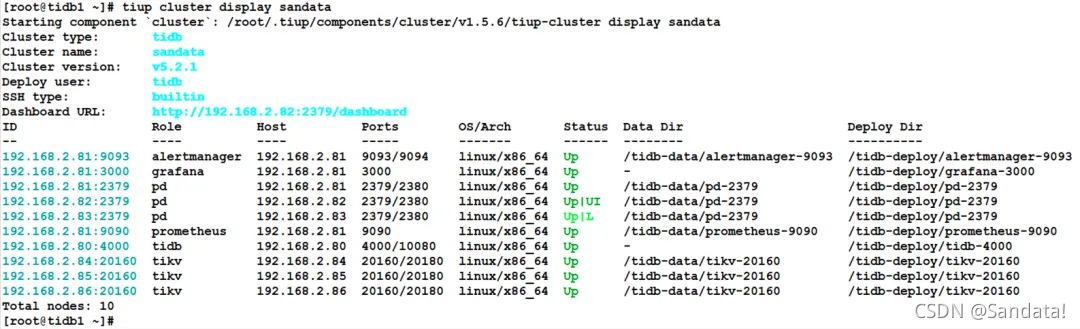
First, use the “tiup cluster display” command to view the TiDB cluster information. The IP:PORT shown in the ID column can be used as the node name. The process is as follows:
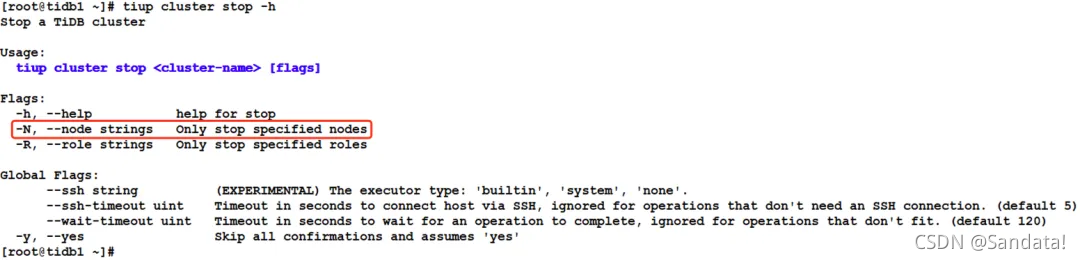
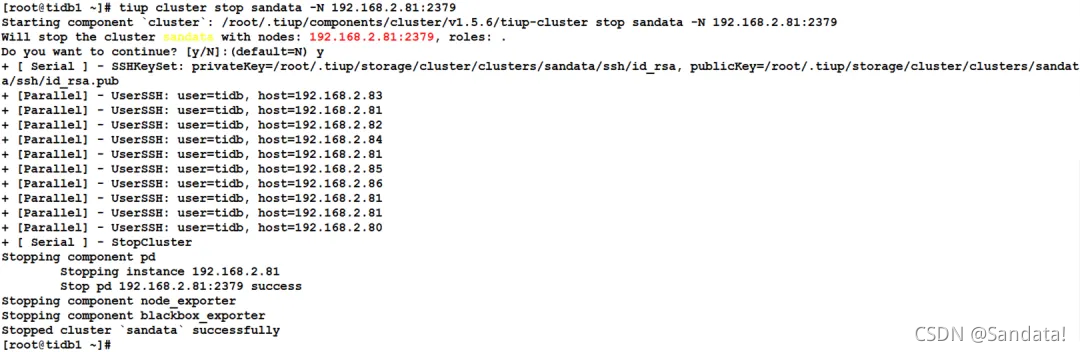
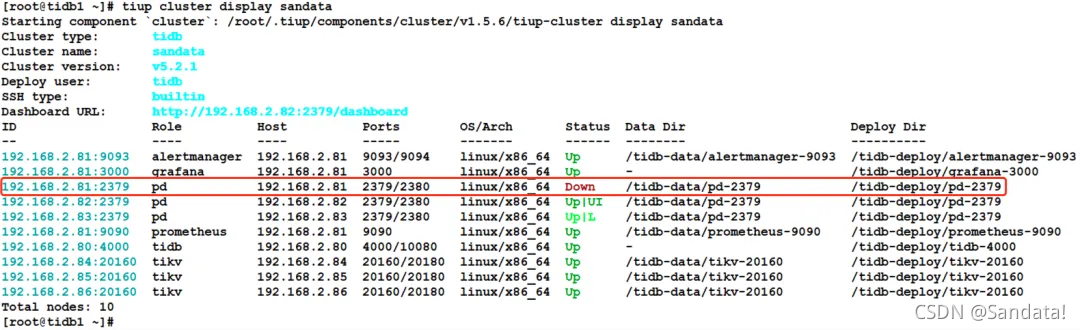
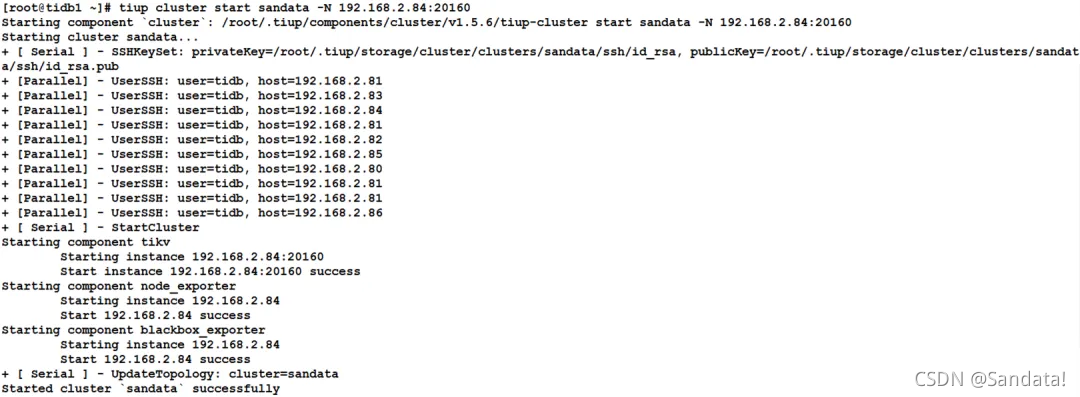
Next, we will restore the stopped nodes one by one. First, use the “tiup cluster start sandata -N 192.168.2.84:20160” command to start the TiKV node. The process is as follows:
Through this article, we can use TiUP to start and stop nodes in the TiDB cluster. This process does not affect the normal operation of other nodes and demonstrates the convenience and ease of use of TiUP.
What time was the power cut off, and what time was it restarted?
The tikv.log shows a system error, unable to connect to the host.
In the pd.log, this segment indicates that the file cannot be found.
The tikv shows that it cannot connect to the host, and at the same time, pd cannot connect to kv. The pd log shows that the file cannot be found, which may be related to system resources and needs further investigation.
Is this a test environment?
In a typical production environment configuration, TiKV and PD are usually placed on different hosts, and there are three or more TiKV instances to avoid data loss and cluster startup failure in case of anomalies.
Somewhere between testing and production, the new data center doesn’t have a UPS and frequently experiences power outages. Additionally, there’s no air conditioning, so overheating might also cause shutdowns.
In this WeChat group, I had a detailed conversation with him. It was the leveldb database of the PD component that got corrupted due to an unexpected power outage on the EXSi, which caused incomplete data saving. Currently, the other party has only one PD server, which has already been rebuilt. They have added the PD nodes to three servers to enhance the fault tolerance of the PD nodes.
The server room has no air conditioning… the servers have overheated and passed out ![]()
I haven’t encountered a similar situation so far. The only similar instance was due to enabling the RAID card cache, but because the RAID card didn’t have a battery, a power outage caused the cache to be lost, which in turn caused TiDB to fail to start.
What a coincidence, I also experienced a power outage last time and wrote an article about it on the forum. However, I couldn’t fix it either and ended up rebuilding it.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.