Optimize Performance Jitter Caused by Incomplete Scheduling Functionality
#18005
During the scheduling process, TiDB consumes resources such as I/O, network, CPU, and memory. If the scheduling tasks are not controlled, QPS and latency may experience performance jitter due to resource contention.
Through the following optimizations, an 8-hour test showed that the standard deviation of tpm-C jitter in the TPC-C test was less than or equal to 2%.
Introduce a New Scheduling Scoring Formula to Reduce Unnecessary Scheduling and Performance Jitter
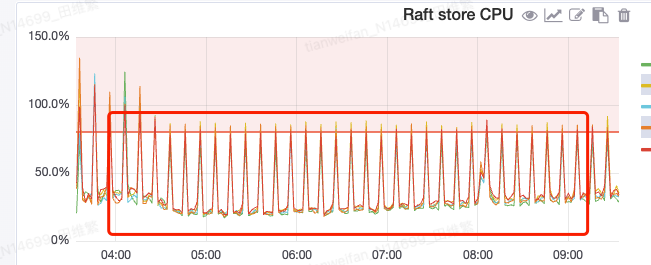
When the total capacity of a node frequently fluctuates around the system’s set watermark or the store-limit configuration is set too high, the system will frequently schedule Regions to other nodes to meet capacity load design, even scheduling back to the original node. This process consumes I/O, network, CPU, and memory resources, causing performance jitter, but such scheduling is often unnecessary.
To alleviate this issue, PD introduces a new scheduling scoring formula, enabled by default. You can switch back to the previous formula using the region-score-formula-version = v1 configuration.
Enable Cross-Table Region Merge by Default
User Documentation
Before version 5.0, TiDB disabled the cross-table Region merge feature by default. Starting from version 5.0, TiDB enables this feature by default to reduce the number of empty Regions and lower the system’s network, memory, and CPU overhead. You can disable this feature by modifying the schedule.enable-cross-table-merge configuration.
Enable Auto-Tuning of Compaction Speed by Default to Balance I/O Resource Contention Between Background Tasks and Front-End Data Reads/Writes
User Documentation
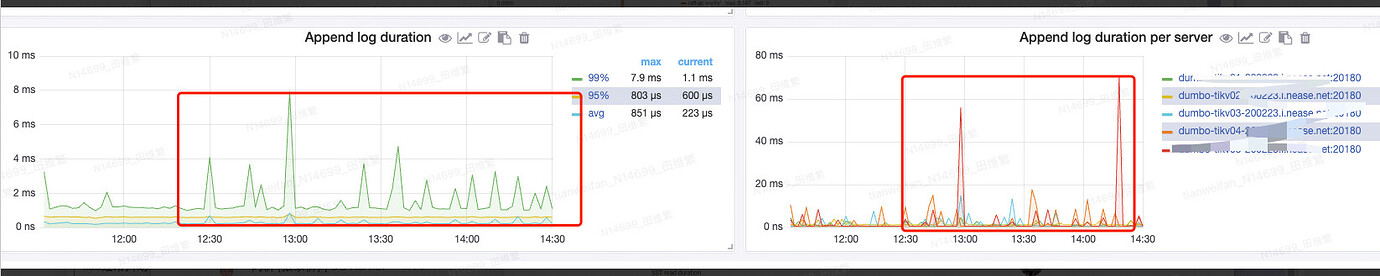
Before version 5.0, the feature to auto-tune Compaction speed to balance I/O resource contention between background tasks and front-end data reads/writes was disabled by default. Starting from version 5.0, TiDB enables this feature by default and optimizes the adjustment algorithm. Enabling this feature significantly reduces latency jitter compared to when it is disabled.
You can disable this feature by modifying the rate-limiter-auto-tuned configuration.
Enable GC in Compaction Filter by Default to Reduce CPU and I/O Resource Usage by GC
User Documentation, #18009
During garbage collection and data Compaction, TiDB partitions consume CPU and I/O resources, and there is data overlap during these tasks.
The GC Compaction Filter feature combines these two tasks into one, reducing CPU and I/O resource usage. This feature is enabled by default, but you can disable it by setting gc.enable-compaction-filter = false.
TiFlash Limits I/O Resource Usage for Compression or Data Organization (Experimental Feature)
This feature alleviates I/O resource contention between background tasks and front-end data reads/writes.
This feature is disabled by default. You can enable it by configuring bg_task_io_rate_limit to limit I/O resource usage for compression or data organization.
Enhance Performance of Scheduling Constraint Checks to Improve Performance of Repairing Unhealthy Regions in Large Clusters