Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tidb 导入速度测试
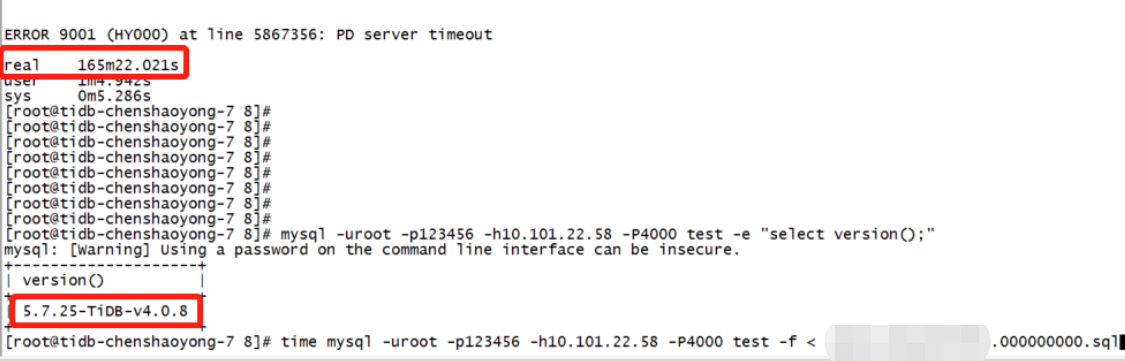
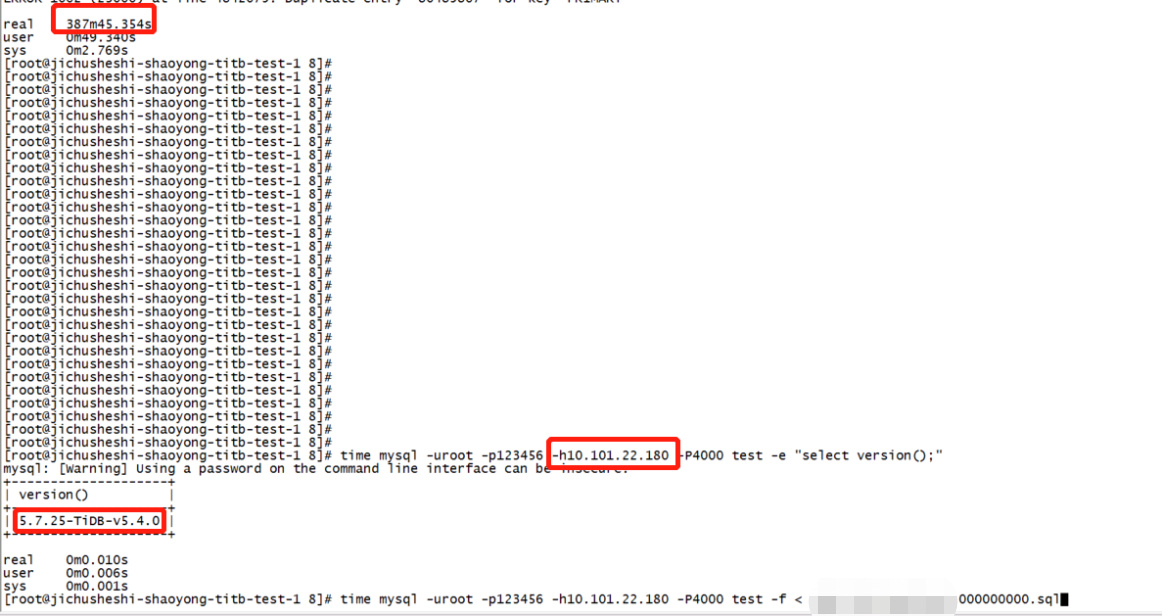
Importing a 3GB file using mysql < sql takes more than twice the time in v5.4.0 compared to v4.0.8. However, when using tidb-lightning to import the entire file, v5.4.0 is slightly faster than v4.0.8.
What is the question?
If it is about sharing testing experiences, it is best to specify the size of each file, the total number of files, whether the import is local or into TiDB, and whether the configurations of different machines are consistent. The import speed varies with different parameters and is influenced by many variables.
Why is importing a 3GB file taking so long? What is the machine configuration?
The machine configuration is 16 cores, 64GB, and the virtual machine is allocated from the same OpenStack.
My question is, with the same machine configuration, the speed of importing SQL files in v4.0.8 is more than twice as fast as in v5.4.0.
Isn’t it clear in the screenshot? The file is 3GB, with a total data volume of over 7 million.
First, you have two questions:
- Why is executing SQL faster in v5?
- Why is Lightning slower in v5?
Is there any resource contention issue with the underlying IO of the virtual machine? If so, what is the configuration file for Lightning import? What parameters are configured? If other variables are consistent across the two versions, have you checked the metrics of both clusters? Is there any issue with TiKV?
When analyzing a problem, you can’t just give an answer without known conditions. If I ask you why v4 has OOM and v5 doesn’t, can you answer directly?
Some necessary conditions need to be considered for benchmarking.