Note:
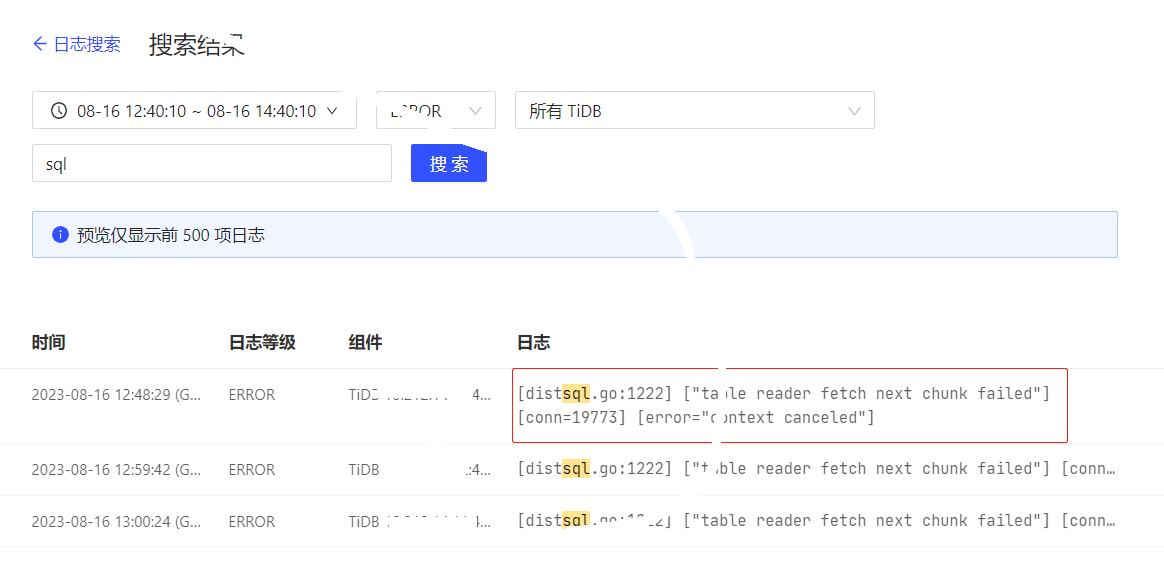
Original topic: TIdb日志报错
[TiDB Usage Environment] Production Environment / Testing / PoCEnter TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
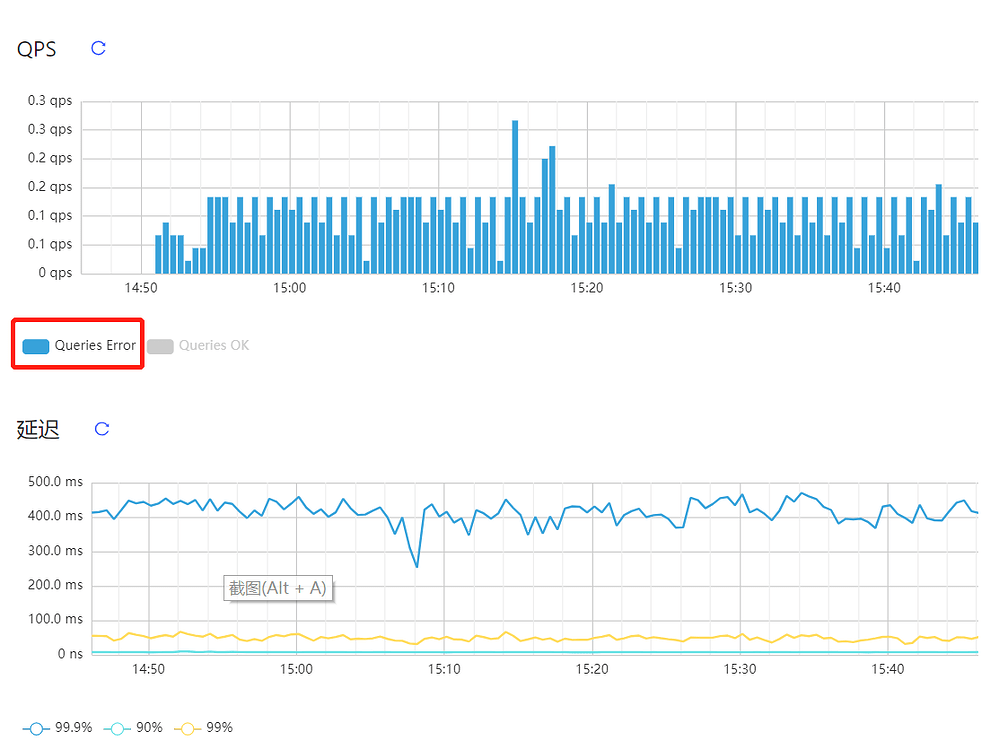
Is there any problem with the cluster now?
opened 02:18PM - 11 Jun 21 UTC
closed 08:14AM - 18 Jun 21 UTC
type/bug
severity/critical
## Bug Report
### What version of TiKV are you using?
v4.0.11, but every… version after v3.0.0 is affected.
### What operating system and CPU are you using?
Doesn't matter.
### Steps to reproduce
Produce highly conflict requests and slow down the shutdown process
### What did you expect?
It shutdown successfully, and ACID is still hold.
### What did happened?
Transaction is corrupted by either missing data from default CF or some part of transaction are rollback.
When a node is shutdown without evicting leader, then leader can't know whether a log is committed or not, so to clear callback, it will respond with a stale response to hint the client to retry. StaleCommand error doesn't mean the request will fail eventually or not, it just mean the leader can't handle the request at the moment.
But latch assumes all responses from raftstore are deterministic that if an error is returned, then the write should never be written unless retry. Hence during shutdown, if there are more than two requests in latch queue, then the first two requests will be processed one by one. If the first request is to commit a transaction and the second is to rollback, then the key can be both committed and rollback. If data is large enough to be stored in default cf, error like `DefaultNotFound` will be reported; in all conditions, ACID is broken.
`StaleCommand` can also be called when a peer is about to be destroyed. But we don't allow to remove leader eagerly, so when the error is reported, the leader should either be removed by leader at last term and it won't process any read before being destroy. If the leader is paused, and then being destroyed by a new leader, all following commands won't be committed as it's not leader anymore.
So to fix the problem, we can either make raftstore's response deterministic or make latch to handle undeterministic error.
For the former, an easy fix is to stop invoking any callbacks during shutdown, this can have the side effects raw kv may not know the requests are stopped, instead, it may timeout before next try.
For the latter, latch should not release slot when an undeterministic error is returned. I think it is also necessary after implementing timeout inside raftstore.
There is a similar discussion in #9113, which is discussing deterministic of transaction.
The cluster is fine now, just troubleshooting the error logs.
This error occurs when the network connection is unstable or interrupted.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.