Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tidb节点、tikv节点oom
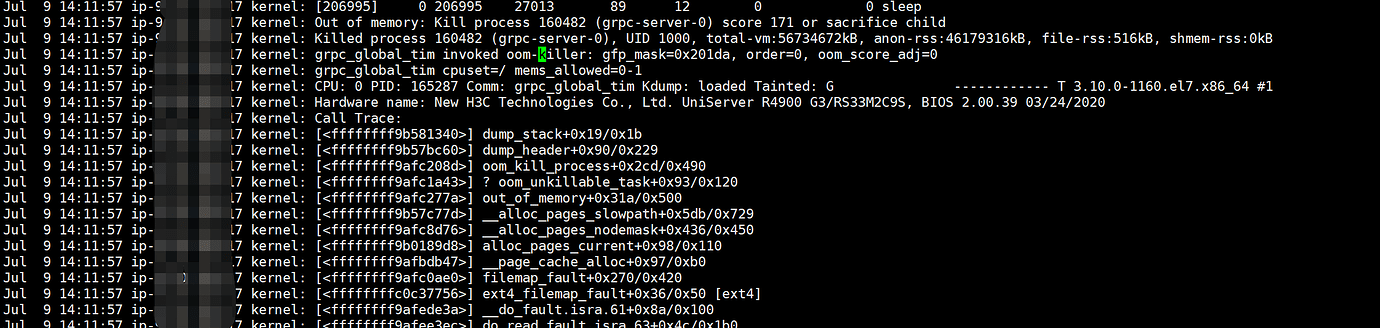
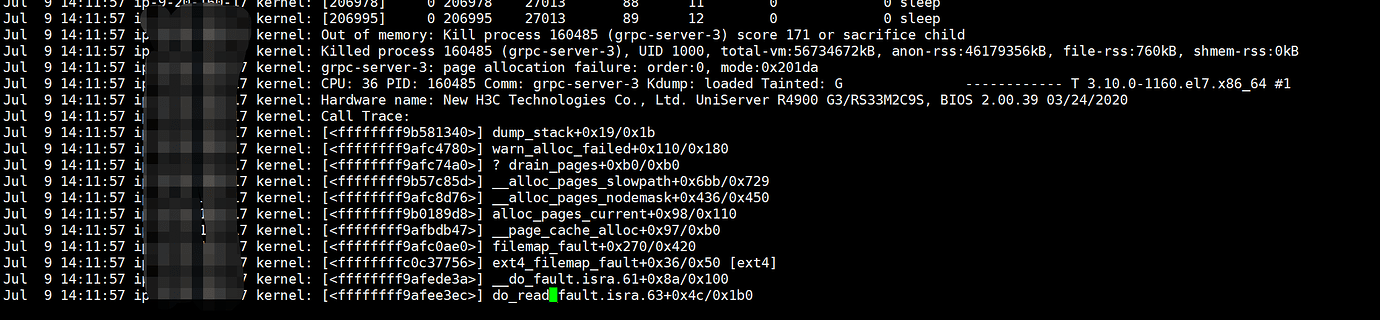
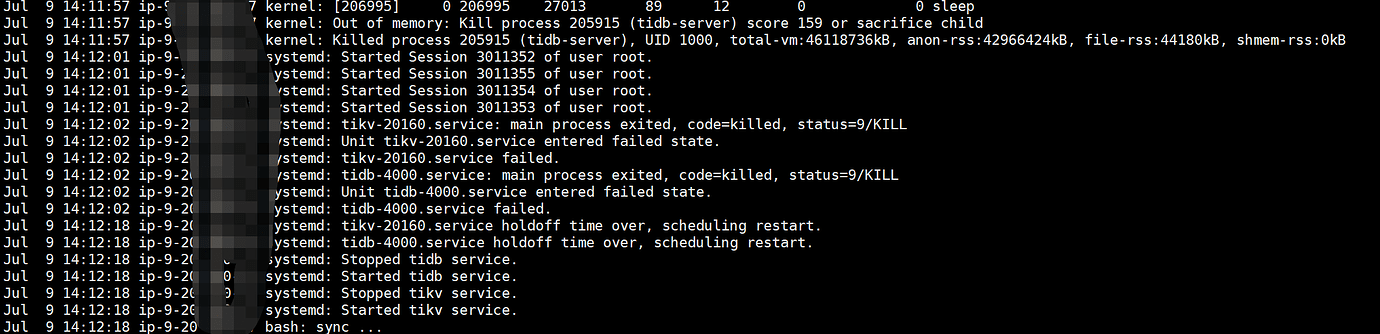
In the test environment, it was found that the TiDB nodes and TiKV nodes frequently restart. Relevant information from the system logs:
For hybrid deployments, try to set resource limits, such as manually setting and lowering the block-cache for TiKV.
This is an OOM issue. You can refer to the documentation to configure the relevant parameters.
TiDB:
TiKV:
Also consider optimizing the SQL.
TiDB and TiKV are mixed, with 2 TiKV instances and 2 TiDB instances on each server. The block-cache was changed from 128G to 50G, but there are still restart issues after the modification. Should it be reduced further? The machine configuration is 512G and 128 cores.
I checked the SQL during the restart period, and the maximum memory usage did not exceed 1GB.
Is TiKV still experiencing kill situations? Please share some monitoring graphs.
- Overview → System info → Memory Available
- TiDB → Server → Memory Usage
- TiKV-Details → Cluster → Memory
- TiDB-Runtime → OOM Nodes → Memory Usage
Also, check if NUMA is bound, and if so, how it is bound.
TiDB and TiKV nodes should preferably not be deployed together, as this can easily lead to memory pressure and cause processes with high memory usage to be killed.
Mixed deployment is also not good.
It seems like the stack overflowed.