Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: TiDB节点挂点,拉不起来
【TiDB Usage Environment】Production Environment
【TiDB Version】v5.2.1
【Encountered Problem】All TiDB nodes are down and cannot be brought up
【Reproduction Path】tiup cluster prune txidc_saas_tidb
【Problem Phenomenon and Impact】
Previously, there were 6 TiKV nodes, and later two were decommissioned with the status Tombstone, and the servers were taken offline. Later, when trying to upgrade the servers, it was found that the upgrade could not proceed because two nodes could not communicate, which were the nodes decommissioned last time. So, the command tiup cluster prune txidc_saas_tidb was executed, but it had no effect. The reload command was also executed later, but it didn’t work either. Then it was left unattended. However, this morning, the business suddenly alerted, and upon checking, it was found that all TiDB nodes in the cluster were down, while other nodes appeared to be normal. Attempts to bring up the TiDB nodes failed.
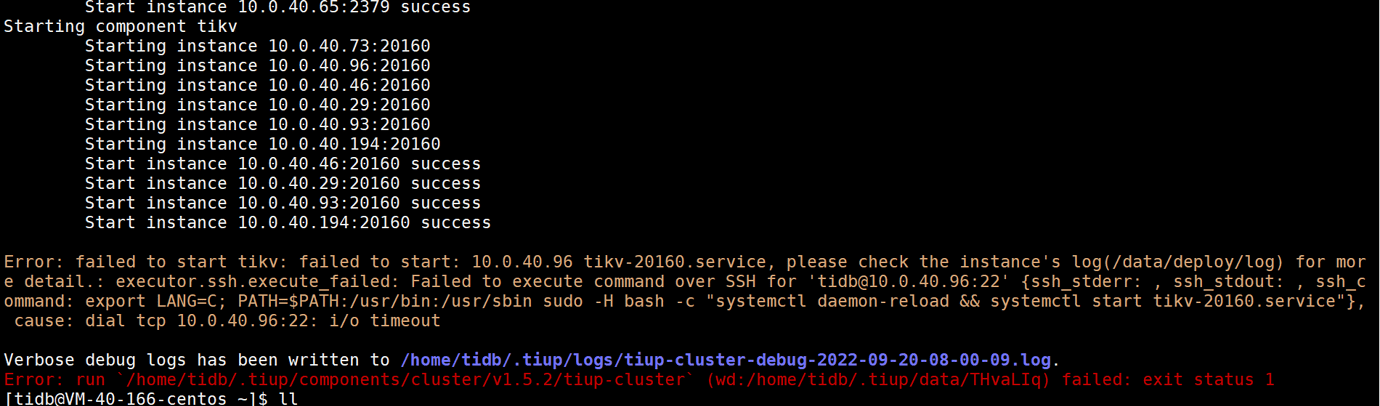
【Attachment】
Cluster type: tidb
Cluster name: txidc_saas_tidb
Cluster version: v5.2.1
Deploy user: tidb
SSH type: builtin
Dashboard URL: http://10.0.40.149:2379/dashboard
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
10.0.40.65:9093 alertmanager 10.0.40.65 9093/9094 linux/x86_64 Up /data/deploy/alertmanager/data /data/deploy/alertmanager
10.0.40.65:3000 grafana 10.0.40.65 3000 linux/x86_64 Up - /data/deploy/grafana
10.0.40.149:2379 pd 10.0.40.149 2379/2380 linux/x86_64 Up|UI /data/deploy/data /data/deploy
10.0.40.20:2379 pd 10.0.40.20 2379/2380 linux/x86_64 Up|L /data/deploy/data /data/deploy
10.0.40.65:2379 pd 10.0.40.65 2379/2380 linux/x86_64 Up /data/deploy/data /data/deploy
10.0.40.65:9090 prometheus 10.0.40.65 9090 linux/x86_64 Up /data/deploy/prometheus/data /data/deploy/prometheus
10.0.40.166:4000 tidb 10.0.40.166 4000/10080 linux/x86_64 Down - /data/deploy
10.0.40.25:4000 tidb 10.0.40.25 4000/10080 linux/x86_64 Down - /data/deploy
10.0.40.85:4000 tidb 10.0.40.85 4000/10080 linux/x86_64 Down - /data/deploy
10.0.40.194:20160 tikv 10.0.40.194 20160/20180 linux/x86_64 Up /data/deploy/data /data/deploy
10.0.40.29:20160 tikv 10.0.40.29 20160/20180 linux/x86_64 Up /data/deploy/data /data/deploy
10.0.40.46:20160 tikv 10.0.40.46 20160/20180 linux/x86_64 Up /data/deploy/data /data/deploy
10.0.40.73:20160 tikv 10.0.40.73 20160/20180 linux/x86_64 Tombstone /data/deploy/data /data/deploy
10.0.40.93:20160 tikv 10.0.40.93 20160/20180 linux/x86_64 Up /data/deploy/data /data/deploy
10.0.40.96:20160 tikv 10.0.40.96 20160/20180 linux/x86_64 Tombstone /data/deploy/data /data/deploy
Total nodes: 15