Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: TiDB 快速起步——课程笔记
Course Title: TiDB Quick Start
1. History of Databases, Big Data, and TiDB
1.1. History and Trends of Databases and Big Data
-
Database Development History:
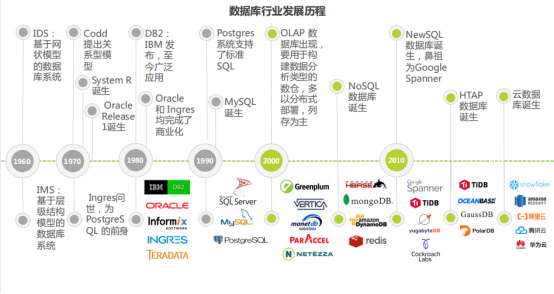
-
Intrinsic Drivers of Database Technology Development:
-
Business Development: Continuous explosion of data volume—data storage capacity, throughput, read/write QPS, etc.
-
Scenario Innovation: Interaction efficiency and diversity of data models—query languages, computation models, data models, read/write latency, etc.
-
Hardware and Cloud Computing Development: Evolution of data architecture—read/write separation, integrated machines, cloud-native, etc.
- Data Volume Drives Data Architecture Evolution:
Single-node local disk
Vertical scaling (Scale up), network storage (ShareDisk)
Horizontal scaling (Scale out), distributed (Share Nothing)
- Evolution of Data Models and Interaction Efficiency:
| Database Type | Reason for Emergence |
| --------------- | ---------------------------------- |
| RDBMS Single-node Database | Supports transactions and mostly uses structured storage |
| NoSQL | Demand for key-value, text, graph, time-series data, geographic information, etc. |
| OLTP | Most NoSQL databases do not support transactions |
| NewSQL | Supports both OLTP and multiple data models | - Trade-offs in Data Architecture for Different Business Scenarios:
Data models, data structures, storage algorithms, replication protocols, operators, computation models, hardware
1.2. Development of Distributed Relational Databases
- Intrinsic Reasons for Distribution:
In 1965, Gordon Moore proposed Moore’s Law.
Core Idea: The number of transistors on an integrated circuit doubles approximately every 18 months. In other words, processor performance doubles every two years.
Implicit Meaning: If the growth rate of the computational load your system needs to handle exceeds the prediction of Moore’s Law, a centralized system will not be able to handle the required computational load.
- Definition of Distributed Systems
Distribution essentially involves the separation of data storage and computation.
Due to potential machine failures, distributed systems increase the failure rate, necessitating multiple replicas for high availability.
- History of Distributed Systems
In 2006, Google’s Three Pillars:
| GFS (Google File System) | Solves distributed file system issues |
| Google Bigtable | Solves distributed KV storage issues |
| Google MapReduce | Solves distributed computation and analysis on distributed file systems and KV storage |
- Main Challenges of Distributed Technology:
- Maximizing separation of concerns
- Achieving global consistency, including serialization and global clocks
- Fault tolerance and handling partial failures
- Dealing with unreliable networks and network partitions
- CAP Theorem
| Consistency | All nodes have the same data at the same time |
| Availability | Service is always available within normal response time |
| Partition Tolerance | The system continues to operate despite network partitions or node failures |
- ACID Properties
Essence of Transactions: A unit of concurrency control, defined by the user as a sequence of operations. Either all operations are executed, or none are, forming an indivisible unit of work.
| Atomicity | All operations within a transaction are an indivisible whole; either all are executed, or none are. |
| Consistency | Data remains consistent before and after the transaction, without violating consistency checks. |
| Isolation | The degree to which transactions affect each other, mainly regulating access to the same data resource by multiple transactions. Different isolation levels address phenomena like dirty reads, non-repeatable reads, and phantom reads. |
| Durability | Once a transaction is completed, changes to the data are recorded. |
CAP and ACID both have consistency, but the consistency in CAP (replica consistency) and ACID (transaction consistency) describe different scenarios.
- NewSQL
NewSQL = Distributed System + SQL + Transactions
A native distributed relational database.
1.3. Evolution of TiDB Product and Open Source Community
Two important foundations of distributed systems: Google Spanner, Raft
Characteristics of open source: Open source code, open attitude, open source community governance
TiDB is an architecture with separated computation and storage, with the storage engine called TiKV.
In May 2015, the project was created on GitHub.
2. Overview of TiDB
2.1. What Kind of Database Do We Need?
- Essential Features for Redesigning a Database:
(1) Scalability
-
From an elasticity perspective, the finer the granularity, the better.
-
Database write resources are expensive, requiring a linear scalability mechanism for write capabilities.
(2) Strong Consistency and High Availability
-
Strong consistency refers to the consistency in CAP. Commonly enforced by writing to two node replicas.
-
RPO (Recovery Point Objective): The target point for data recovery.
-
RTO (Recovery Time Objective): The target time for recovery.
-
Strong consistency equivalence: RPO=0, RTO is sufficiently small, usually within seconds.
(3) Support for Standard SQL and Transactions (ACID)
-
SQL usability
-
Complete OLTP transactions
(4) Cloud-native Database
(5) HTAP
-
Supports massive data
-
Hybrid row-column storage, complete resource isolation
-
Open, compatible with database and big data ecosystems
-
Unified data query service
(6) Compatibility with Mainstream Ecosystems and Protocols
- Reduces usage barriers and costs
- Basic Data Technology Elements
| No. | Element | Description |
|---|---|---|
| 1 | Data Model | Relational model, document model, key-value model, etc. |
| 2 | Data Storage and Retrieval Structure | Data structures, index structures, common B-tree, LSM-tree, etc. |
| 3 | Data Format | Relational and non-relational |
| 4 | Storage Engine | Responsible for data access and persistent storage, such as Innodb/Rockdb, etc. |
| 5 | Replication Protocol | Ensures data availability, replication protocols and algorithms, common ones include Raft, Paxos, etc. |
| 6 | Distributed Transaction Model | Concurrency control methods for transaction processing to ensure serializability. Common models include SZ, TCC, Percolator, etc. |
| 7 | Data Architecture | Generally refers to multiple computation engines sharing one data set, or each computation engine having its own data set. Common architectures include Share-Nothing, Share-Disk, etc. |
| 8 | Optimizer Algorithm | Generates the lowest-cost execution plan based on data distribution, data volume, and statistics. |
| 9 | Execution Engine | Examples include volcano model, vectorization, massive parallel processing, etc. |
| 10 | Computation Engine | Responsible for SQL statement interfaces, parsing to generate execution plans and sending them to the storage engine for execution. Most computation engines also have data caching capabilities. |
- Separation of Computation and Storage
Disadvantages of Coupling Computation and Storage:
(1) Strong binding of computation and storage means there is always some resource wastage.
(2) When selecting servers, there is a dilemma between computation and storage types, increasing complexity and reducing generality.
(3) In cloud computing scenarios, the granularity of elasticity is the machine, which cannot achieve true resource elasticity.
In the cloud era, based on high-performance network block storage (EBS), the coupling of storage and computation is even more unreasonable.
- Highly Layered Architecture of TiDB
(1) Supports standard SQL computation, engine TiDB-Server
(2) Distributed storage engine TiKV
(3) Metadata management and scheduling engine, Placement Driver
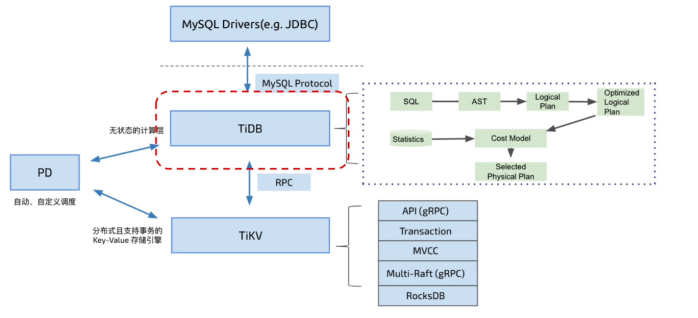
2.2. How to Build a Distributed Storage System
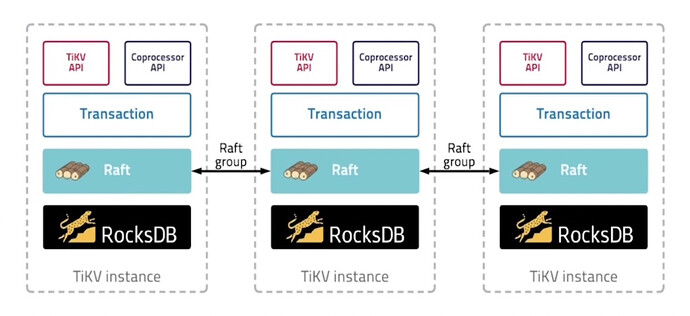
- What Kind of Storage Engine Do We Need:
(1) Finer-grained elastic scaling
(2) High concurrent read/write
(3) No data loss or corruption
(4) Multiple replicas to ensure consistency and high availability
(5) Support for distributed transactions
- How to Build a Complete Distributed Storage System
(1) Choose Data Structure
-
Key-value data model
-
Index structure LSM-tree (uses sequential writes, persisting to a static file after reaching a certain threshold, and merging static files as they grow larger. Essentially, it trades space for write latency, replacing random writes with sequential writes.)
(2) Choose Data Replication—Raft
(3) How to Achieve Scaling
-
Sharding using range algorithm
-
Region: Segments of key-value space. Currently defaults to 96MB.
(4) How to Achieve Separation and Scaling
-
Split and merge based on region size. When a region exceeds a certain limit (default 144MB), TiKV splits it into two or more regions. When a region becomes too small due to deletions, TiKV merges adjacent regions.
-
A component records the distribution of regions across nodes.
-
Raft replicates three copies.
(5) Flexible Scheduling Mechanism
- List entries
PD component ensures regions are evenly distributed, achieving horizontal scaling of storage capacity and load balancing.
(6) Multi-Version Control (MVCC)
(7) Distributed Transaction Model
-
Uses Google’s Percolator transaction model, optimized and improved. Overcomes the performance bottleneck of the “two-phase” commit transaction manager:
-
Uses a “decentralized” two-phase commit algorithm. Column clusters, globally unique timestamps (TSO);
-
Default isolation level is Snapshot Isolation (SI), close to Repeatable Read (RR), naturally avoiding phantom reads. Also supports Read Committed (RC) isolation level;
-
Supports optimistic and pessimistic locking;
-
Supports asynchronous commit in the second phase.
(8) Co-Processor
- Co-Processor.
(9) Overall Architecture of TiKV
TiKV, inspired by Google Spanner, designed a multi-raft-group replication mechanism. Data is divided into roughly equal slices (regions) based on key ranges, each with multiple replicas (usually 3), with one replica being the leader, providing read/write services. TiKV uses PD to schedule these regions and replicas, deciding which replica becomes the leader, ensuring data and read/write loads are evenly distributed across TiKV nodes. This design ensures full utilization of cluster resources and horizontal scaling with the addition of machines.
2.3. How to Build a Distributed SQL Engine
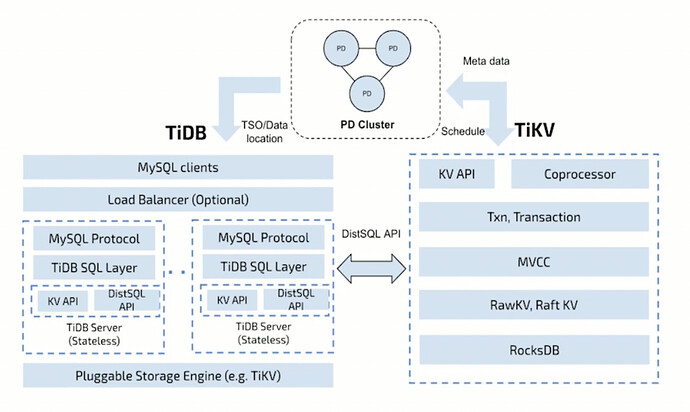
-
Implementing Logical Tables: Through a globally ordered distributed key-value engine.
-
Designing Secondary Indexes Based on KV: Also a globally ordered KV map. Key is the index column, values are the primary key of the original table.
-
SQL Engine Process
-
SQL syntax parsing, semantic parsing, protocol parsing
-
AST (Abstract Syntax Tree). Parses SQL from text to structured data.
-
SQL logical optimization. Various SQL equivalent rewrites and optimizations, such as converting subqueries to table joins, column pruning, partition pruning, etc.
-
Optimizer generates execution plans based on statistics and cost models. The most critical part: “best execution plan.”
-
Executor executes the plan.
- Cost-Based Optimizer
How does the optimizer find the best execution plan?
-
Knowing the advantages and applicable scenarios of each operator.
-
Reasonable use of CPU, memory, network resources, based on cost models.
- Main Optimization Strategies for Distributed SQL Engine
-
Executor construction: Maximizing computation pushdown.
-
Key operators distributed.
- How to Build an Online DDL Algorithm
-
No concept of sharding, Schema (table structure) is stored only once, adding columns only requires Schema operations, no need to update data.
-
DDL process is stateful (Public/Delete-only/Write-only), each state is synchronized and consistent across multiple nodes.
- How to Connect to TiDB-Server
MySQL client, SDK connection.
- From the Perspective of TiDB-Server Process
A background process.
Process: Start, listen on port 4000, communicate with Client, parse network requests, SQL parsing, get TSO from PD cluster, region routing, read/write data from TiKV.
- Foreground Functions
(1) Manage connections and account permissions
(2) MySQL protocol encoding/decoding
(3) Independent SQL execution
(4) Database and table metadata, and system variables
- Background Functions
(1) Garbage collection
(2) Execute DDL
(3) Manage statistics
(4) SQL optimizer and executor
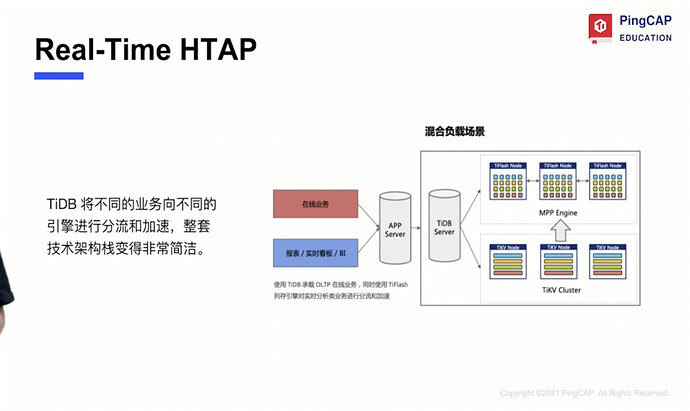
3. Next-Generation HTAP Database Selection
3.1. HTAP Database Based on Distributed Architecture
-
In 2005, Gartner proposed HTAP (Hybrid Transactional/Analytical Processing Database). Eliminates the need for ETL.
-
OLTP: Pursues high concurrency, low latency; OLAP: Pursues throughput.
-
Next Steps in HTAP Exploration
-
Unified data services
-
Iteration of embedded functions within products, completed by specific products for HTAP
-
Integration of multiple technology stacks and products, forming HTAP services through data linkage.
- Stages of Data Warehouse Evolution
-
Batch processing (ETL) offline data warehouse
-
Lambda architecture combining batch and stream processing
-
Kappa architecture focusing on stream processing
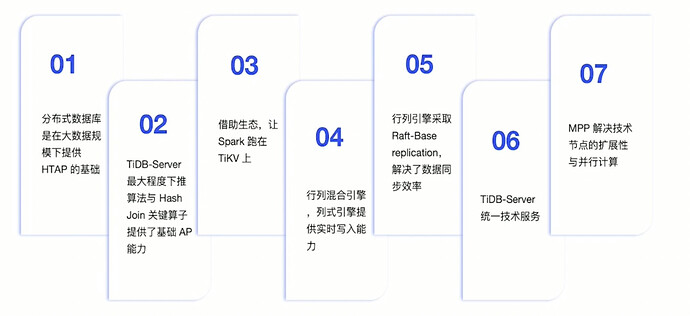
3.2. Key Technological Innovations of TiDB
- Three Distributed Systems After Trade-offs:
-
Distributed KV storage system
-
Distributed SQL computation system
-
Distributed HTAP architecture system
-
Automatic Sharding Technology as the Basis for Finer-Grained Elasticity
-
Elastic Sharding Constructs a Dynamic System
-
Multi-Raft Makes Replication Groups More Discrete
-
Linear Scaling of Writes Based on Multi-Raft
-
Multi-Raft Enables Multi-node Writes Across IDC for Single Tables
-
Decentralized Distributed Transactions
-
Local Read and Geo-partition: Local reads and multi-region active-active data distribution
-
HTAP with Large Data Volumes
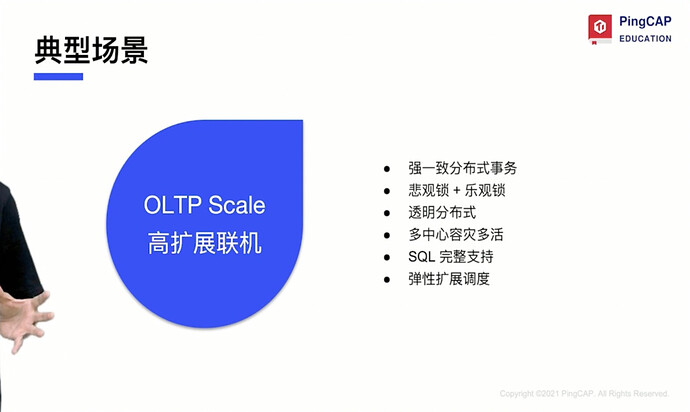
3.3. Typical Application Scenarios and User Cases of TiDB
- Design Goals of TiDB:
-
Horizontal scalability (Scale out)
-
MySQL compatibility
-
Complete transactions (ACID) + relational model
-
HTAP
- Data Architecture Selection
Ensure stability, improve efficiency, reduce costs, ensure security.
4. First Experience with TiDB
4.1. First Experience with TiDB
Use TiUP to set up a local test cluster and automatically install TiDB Dashboard and Grafana, supporting MacOS. Refer to the URL: