Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 【TiDB 快速起步】学习笔记
Course address: https://learn.pingcap.com/learner/course/6
Mind Map Summary
01 History and Trends of Database and Big Data Development
- Drivers of data technology development
- Business growth leading to increased data volume
- Scenario innovation driving the need for “data interaction efficiency and data model diversity”
- Development of hardware and cloud computing
- Segmentation of data technology and integration of data services
- The essence of the data technology stack or data products: Addressing different business scenarios, making various trade-offs in data technology domain architecture based on these relatively fixed foundational data technology elements
02 Development of Distributed Relational Databases
- If the growth rate of the computational load your system needs to handle exceeds Moore’s Law, a centralized system will not be able to handle the required computational load
- Distributed is synonymous with massive data and computation
- Key challenges of distributed systems: divide and conquer, global consistency, fault amplification, partition tolerance
- Although expressing the concept of consistency, the scenarios described by CAP (replica consistency) and ACID (transaction consistency) are different
03 Evolution of TiDB Product and Open Source Community
- Raft is an important foundation in distributed systems
- The open-source model is one of the best paths to success for foundational software
- TiDB is already a top-tier international open-source project
04 What Kind of Database Do We Really Need
- Six design goals of distributed relational databases
- Horizontal scalability
- Strong consistency and high availability
- Standard SQL and transaction model
- Cloud-native
- HTAP
- Ecosystem compatibility
- The development of hardware, especially networks, has driven the architecture of compute-storage separation
- TiDB has a highly layered architecture
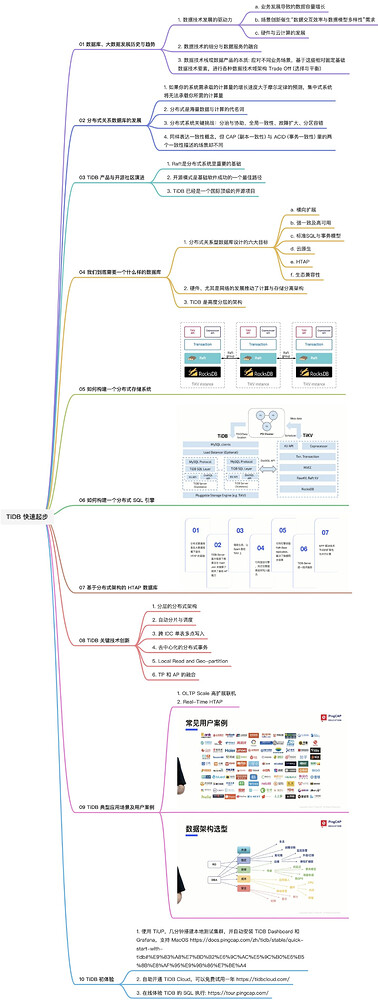
05 How to Build a Distributed Storage System
Using the highly layered TiKV transaction + storage engine as an example
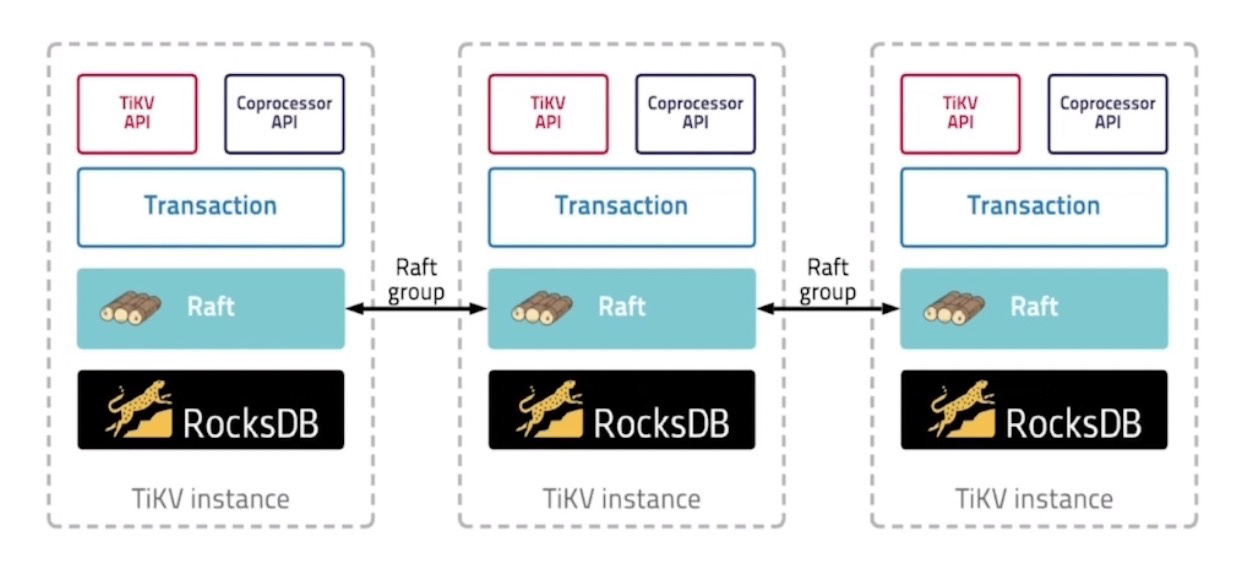
06 How to Build a Distributed SQL Engine
Using the TiDB-Server SQL engine as an example
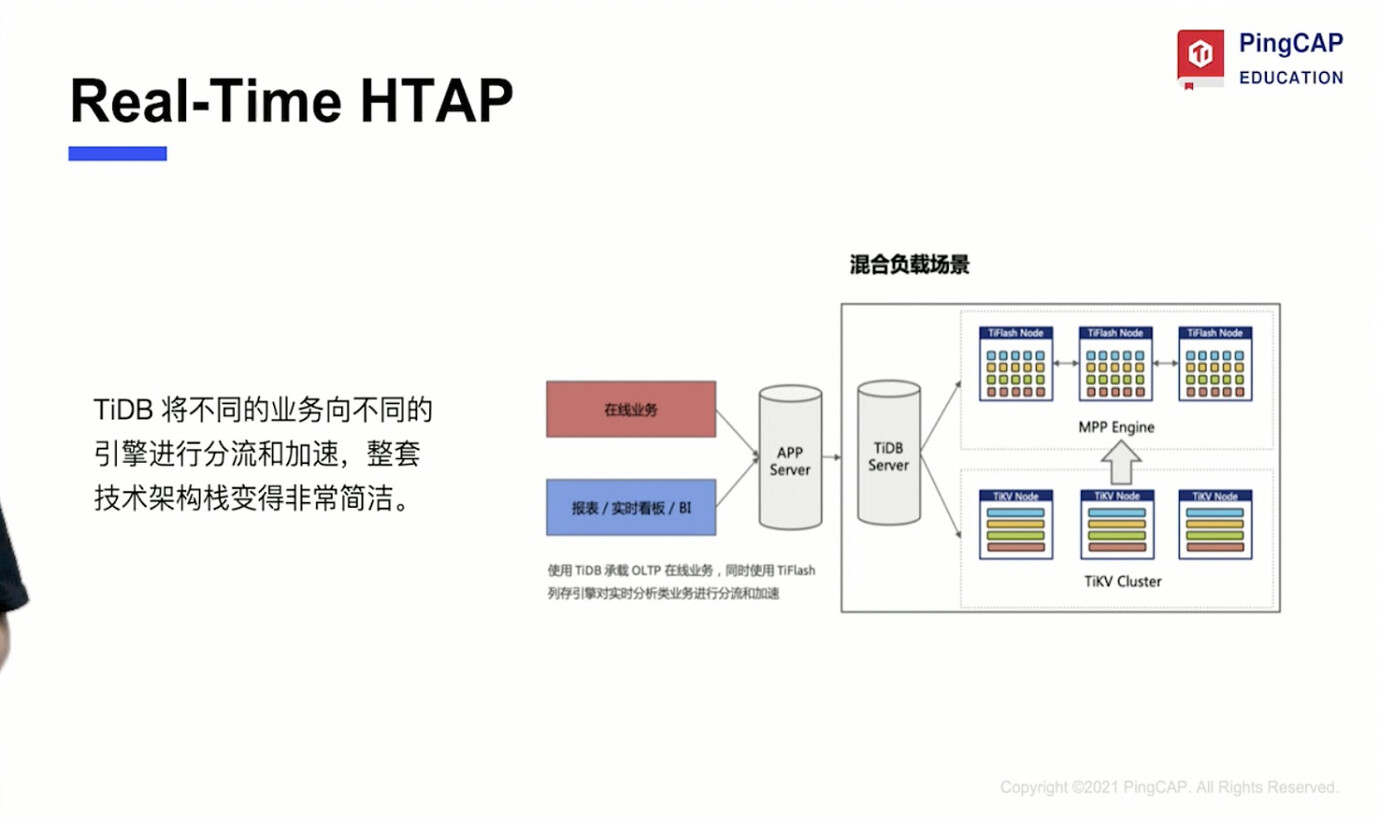
07 HTAP Database Based on Distributed Architecture
08 Key Technological Innovations of TiDB
- Layered distributed architecture
- Automatic sharding and scheduling
- Cross-IDC single-table multi-point writing
- Decentralized distributed transactions
- Local Read and Geo-partition
- Integration of TP and AP
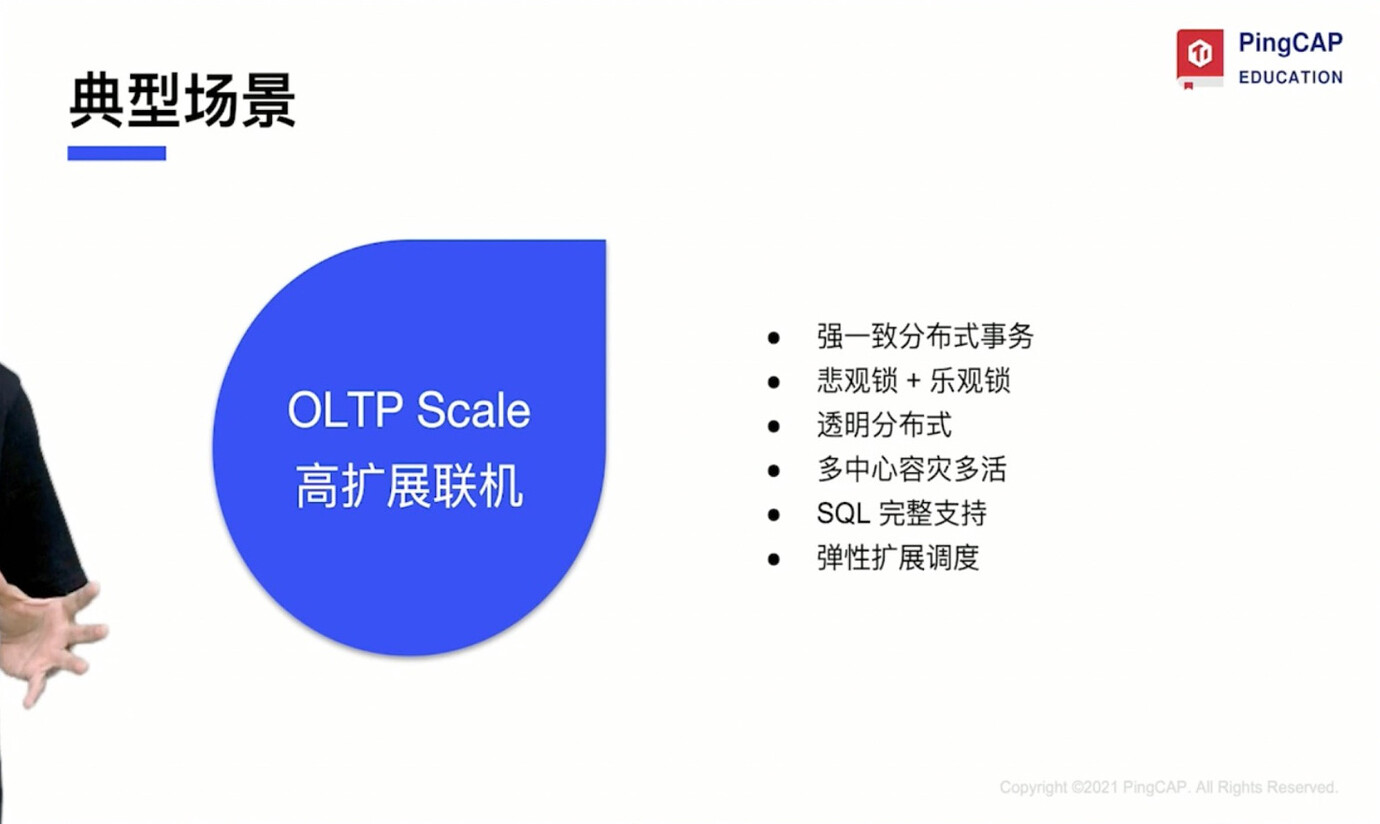
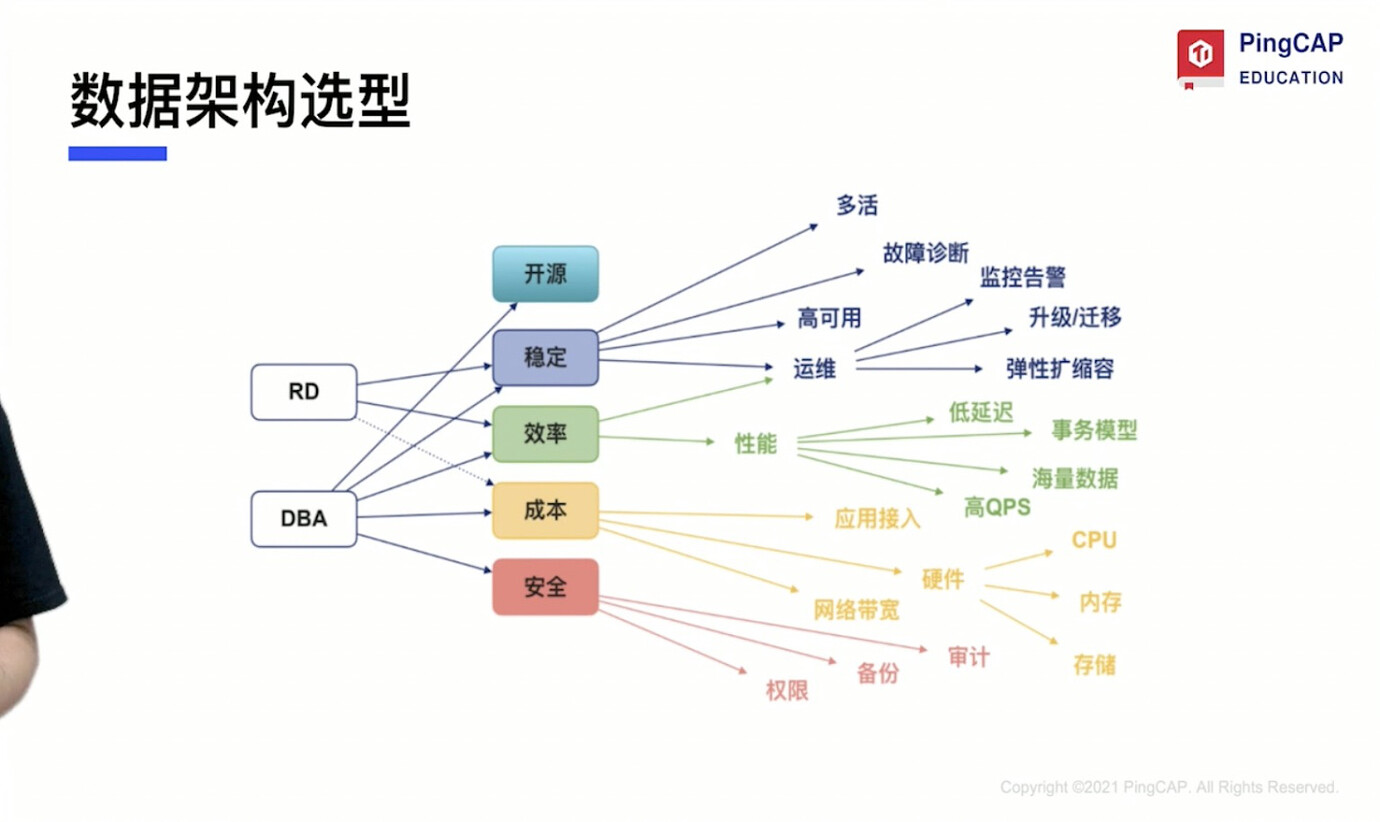
09 Typical Application Scenarios and User Cases of TiDB

10 First Experience with TiDB
- Using TiUP, set up a local test cluster in a few minutes, and automatically install TiDB Dashboard and Grafana, supporting MacOS
- Self-service activation of TiDB Cloud, free trial for one year https://tidbcloud.com/
- Online experience of TiDB’s SQL execution: https://tour.pingcap.com/