Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: (毕设相关,大佬求救)TiDB水平伸缩容问题
[Test Environment for TiDB]
[TiDB Version]
[Reproduction Path] What operations were performed to encounter the issue
[Encountered Issue: Phenomenon and Impact]
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
Background: I used the operation command “kubectl patch -n tidb-cluster tc basic --type merge --patch '{“spec”:{“tidb”:{“replicas”:3}}}” to change the number of TiDB nodes.
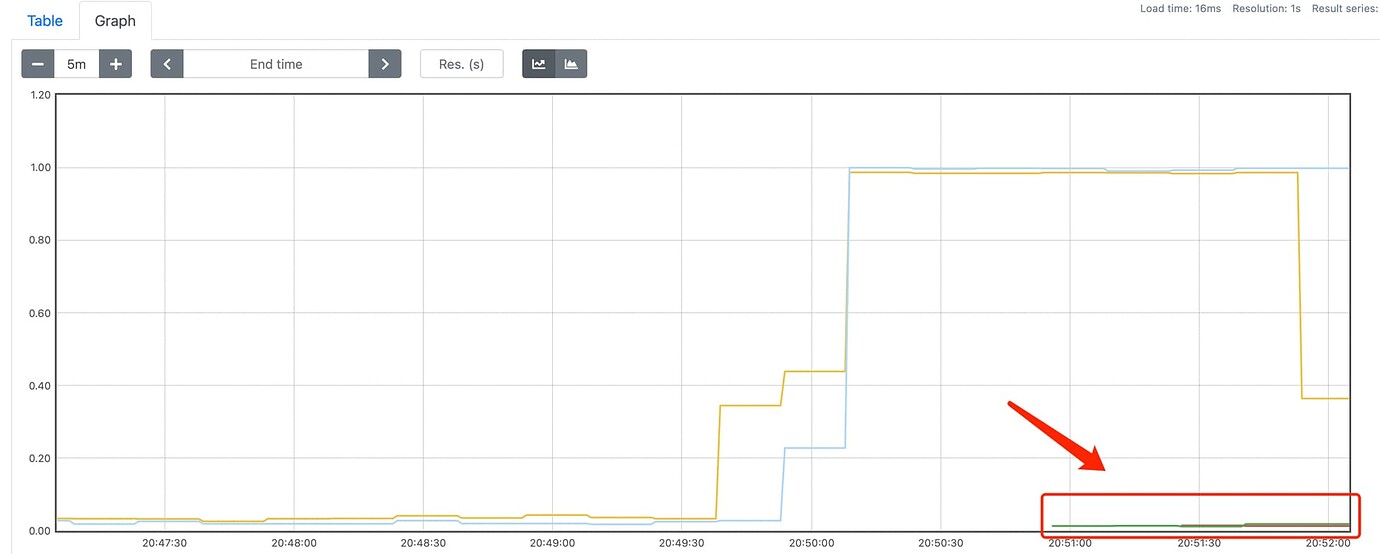
After starting a stress testing program, when I scaled out from 2 tidbPods to 4 tidbPods, I found that the CPU usage of the newly added TiDB nodes was almost 0 (i.e., no stress testing tasks were assigned) as shown in the image below:
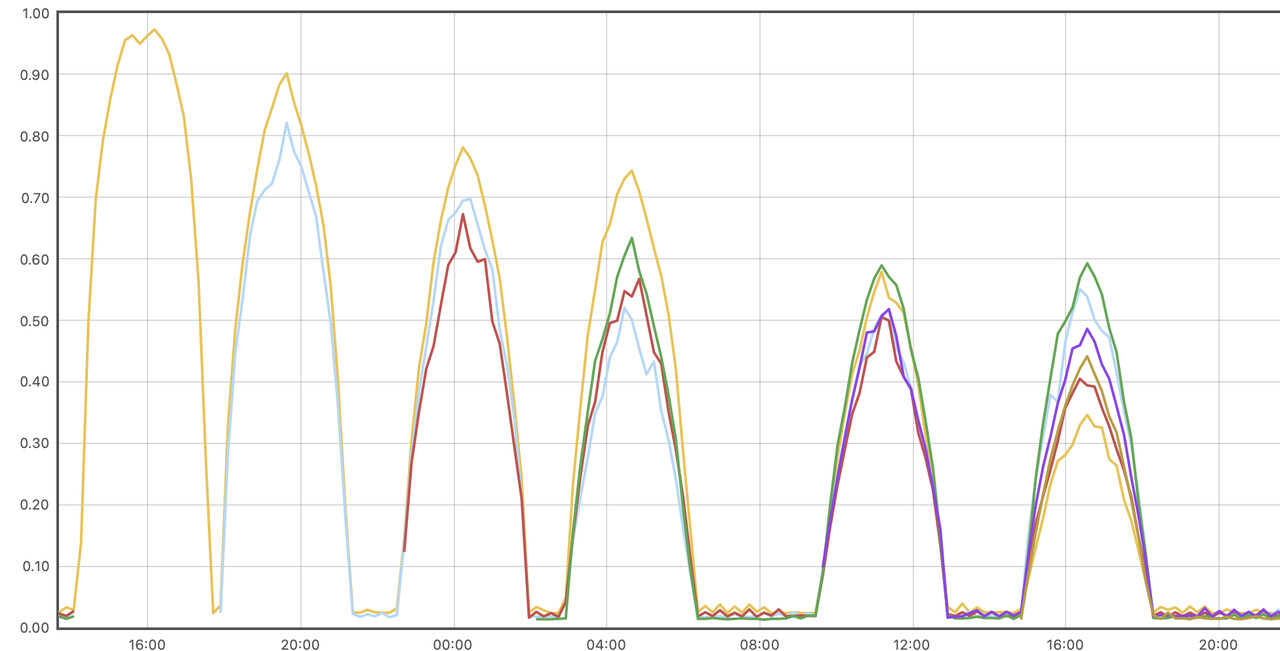
When I scaled down from 4 pods to 1 pod, the stress testing program unexpectedly terminated with the following error:
How can I perform scaling operations on TiDB under the same stress testing program and obtain the desired test results? I want to measure the CPU changes in the cluster during scaling operations under a certain workload. Specifically, after scaling out, the CPU usage of each tidbPod should not be 0; after scaling down, the stress testing program should continue running without interruption.
Help, please!
TiDB still needs a proxy in front to help balance the TiDB connectors…
The official recommendation is to set up HAProxy, which will suffice.
Alternatively, you can use the MySQL JDBC connector with multiple IPs and ports for automatic balancing.
But my TiDB is using the ClusterIP mode. Do I still need to configure the HAProxy proxy?
Is the stress testing service also running inside K8S?
Confirm whether the clusterIp mode can achieve the balance you want…
For example, I set a domain name in DNS and bind multiple IPs to it. When I ping this domain name, each ping will switch to a different IP (but the same request, regardless of the amount of content requested, will only go to one IP…).
sybench? Specify the following two parameters:
–mysql-ignore-errors=ALL
–oltp-reconnect-mode=STRING
Skip errors, and choose the reconnect mode to reconnect each time.
The stress testing program needs to have a reconnection mechanism. Otherwise, when scaling down, the original connections will be disconnected, leading to errors. There might be no pressure on the new nodes during scaling up because your stress testing program uses long connections, continuously using the original connections.
Hello, I think your solution is feasible. During the implementation, sysbench raised a warning:
I added parameters in the configuration file sysbench.config in advance

What could be the reason for this? I just blogged for a while but couldn’t find the answer I wanted.
Your version of sysbench no longer supports this parameter, right? You should directly use the existing oltp-type lua files for benchmarking.
I modified the code of the original benchmarking tool (CMU-Bench) that I used from the beginning, and it became
Thanks for the guidance 
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.