[TiDB Usage Environment] Production Environment
[TiDB Version] 5.4.1
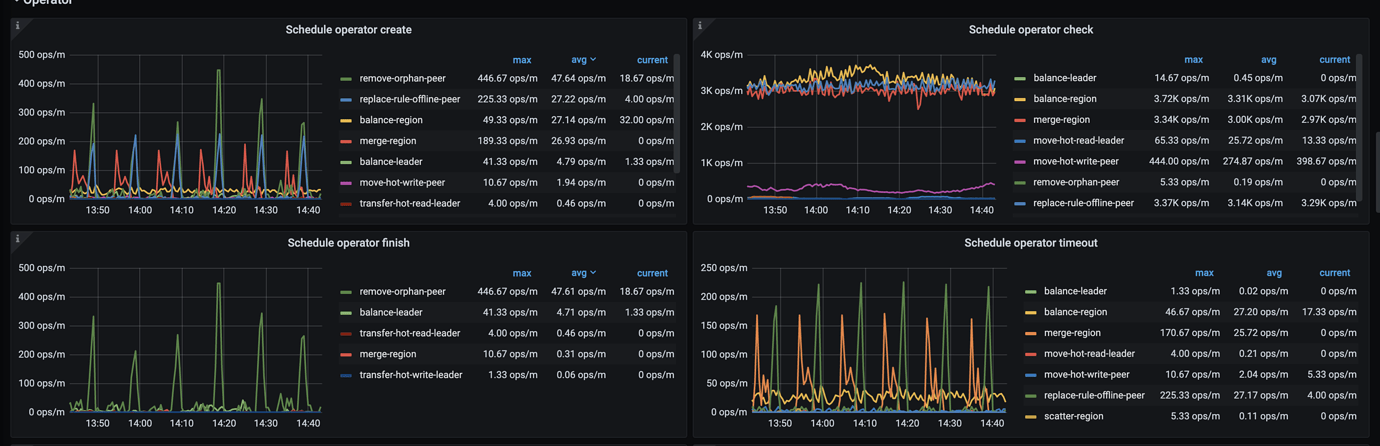
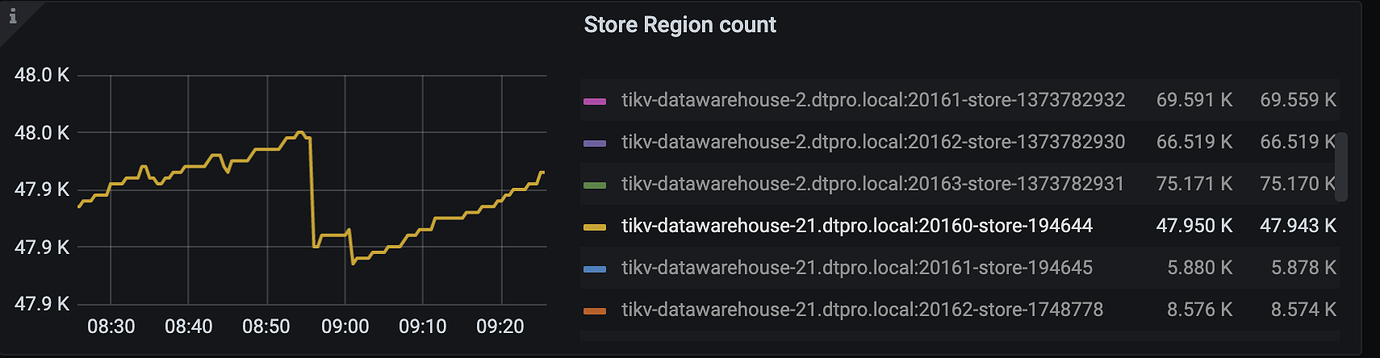
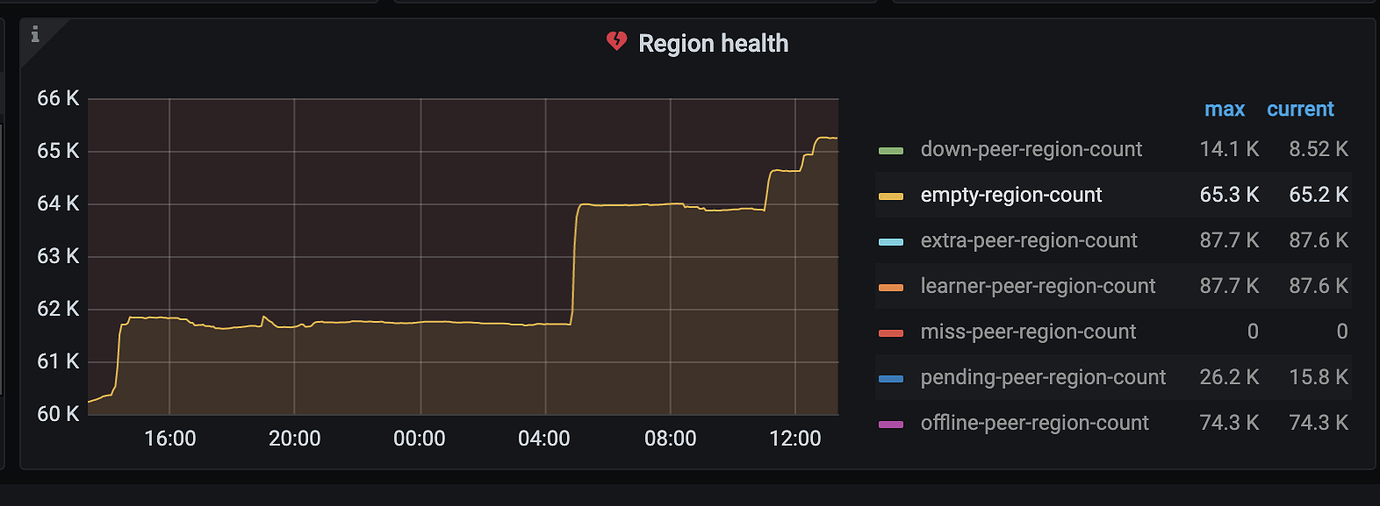
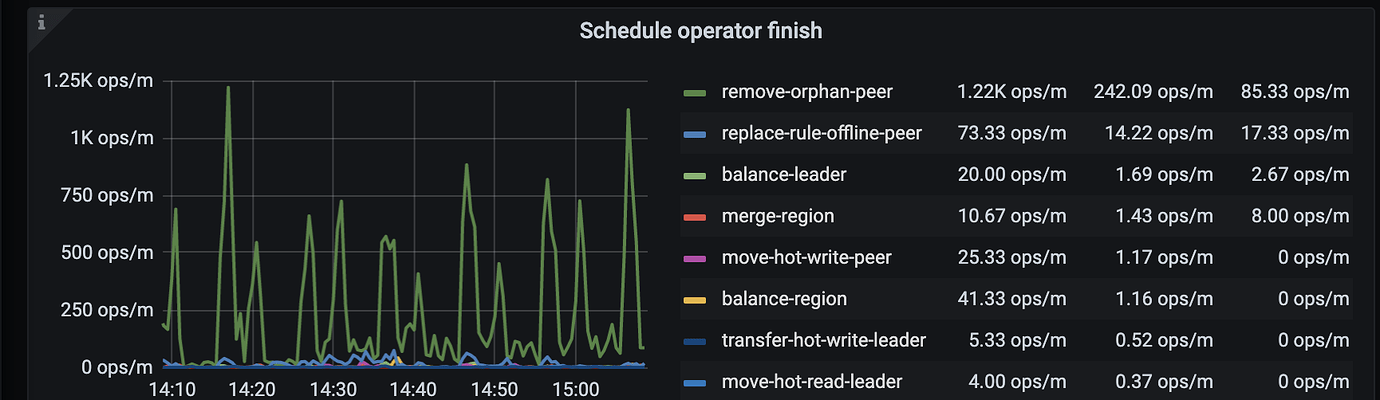
[Encountered Issue] Most of the operators created by the scheduler (merge region, replace-rule-offline-peer) have timed out. Some nodes in the cluster have been taken offline, but the regions of one node have not decreased.
[Reproduction Path]
[Issue Phenomenon and Impact] The scheduling of the offline node cannot be completed. I want to know which parameter can adjust the timeout time of the operator, so I can adjust it to complete the schedule of this node.
We have tried the configuration in this document, but the current issue is that most operators (merge region, replace-rule-offline-peer) will timeout no matter how high the limit is adjusted.
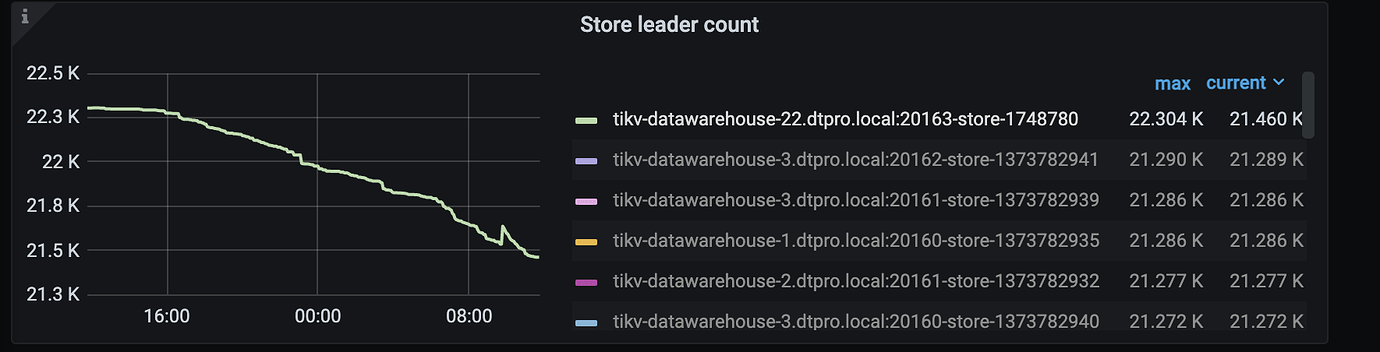
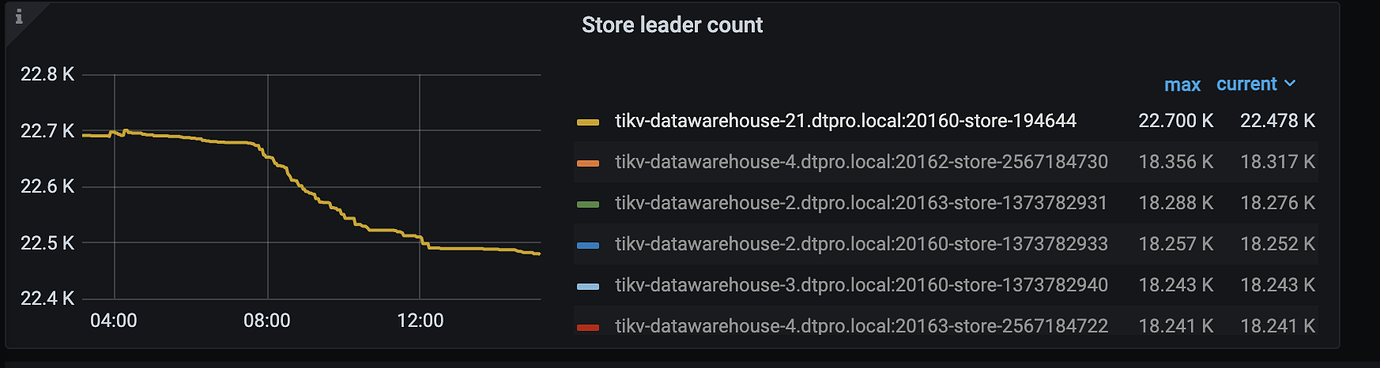
When this instance first went offline, the leader didn’t change much until we restarted it, and then the leader started to decrease. Additionally, there are a few other instances where a small number of leaders are no longer changing.
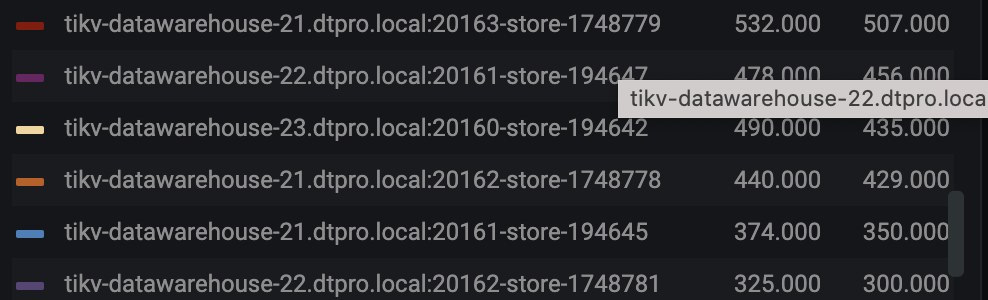
We replaced the TiKV nodes by first scaling out and then scaling in. To improve the scheduler speed, we increased some limit parameters. These values are the changes after increasing the limits.
Hello~ This might require checking the placement rule and label configuration to see if there are any incorrect label configurations causing regions to not be properly scheduled under different domains of the same label layer. For example, using the Rack layer configuration, if you configure Rack1, Rack2, and Rack3, but the offline TiKV is configured as Rack2, and there are no other TiKV instances in Rack2 available to store the region, it will result in the regions of the offline TiKV not being scheduled.
With the help of @jingyu ma, the store limit has been adjusted, and now the speed of the remove-orphan-peer operator is quite considerable. However, the replace-rule-offline-peer is only slightly faster than before and is still very slow. Specifically, the regions on some stores are dropping particularly slowly.