Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiDb-Server 突然掉线然后几秒后恢复正常
[TiDB Usage Environment] Production Environment
[TiDB Version] v7.5.1
[Encountered Issue: Symptoms and Impact]
The tidb-server disconnects suddenly 5-6 times a day and then returns to normal after a few seconds. How should we troubleshoot this kind of issue?
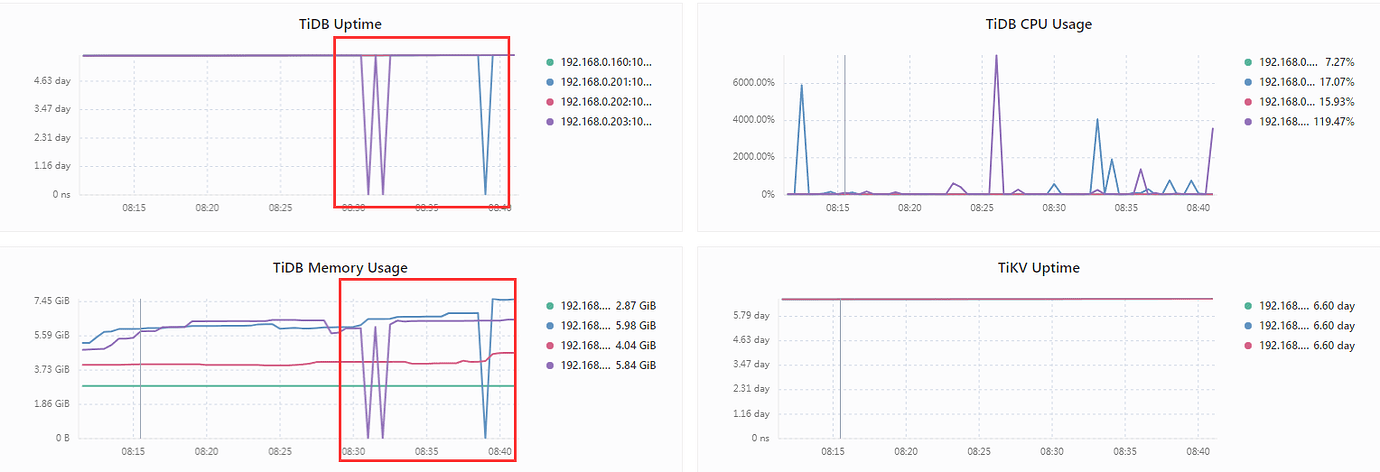
Below is the CPU and memory usage of tidb-server during the disconnection.
How is your cluster configured? Also, check the tidb-server logs to see what errors are reported.
It probably ran out of memory (OOM).
Refer to this link to troubleshoot the issue: TiDB OOM 故障排查 | PingCAP 文档中心
There must be error logs, right?
Looking at the uptime, it hasn’t restarted. Is the network down?
This is the cluster configuration.
Which TiDB instance on the 203 needs to be restarted, one of the two 64C? The CPU usage can reach over 6000%…
Here is the log information printed in tidb.log today:
[2024/03/15 00:12:31.194 +00:00] [ERROR] [tso_dispatcher.go:202] [“[tso] tso request is canceled due to timeout”] [dc-location=global] [error=“[PD:client:ErrClientGetTSOTimeout]get TSO timeout”]
[2024/03/15 00:12:31.204 +00:00] [ERROR] [tso_dispatcher.go:498] [“[tso] getTS error after processing requests”] [dc-location=global] [stream-addr=http://192.168.0.160:2379] [error=“[PD:client:ErrClientGetTSO]get TSO failed, %v: [PD:client:ErrClientTSOStreamClosed]encountered TSO stream being closed unexpectedly”]
[2024/03/15 00:12:31.209 +00:00] [ERROR] [pd.go:236] [“updateTS error”] [txnScope=global] [error=“[PD:client:ErrClientTSOStreamClosed]encountered TSO stream being closed unexpectedly”]
[2024/03/15 00:39:04.806 +00:00] [ERROR] [advancer.go:398] [“listen task meet error, would reopen.”] [error=“etcdserver: mvcc: required revision has been compacted”]
[2024/03/15 00:39:04.816 +00:00] [ERROR] [domain.go:1743] [“LoadSysVarCacheLoop loop watch channel closed”]
[2024/03/15 00:39:04.824 +00:00] [ERROR] [domain.go:1680] [“load privilege loop watch channel closed”]
[2024/03/15 00:39:04.847 +00:00] [ERROR] [pd_service_discovery.go:257] [“[pd] failed to update member”] [urls=“[http://192.168.0.160:2379]”] [error=“[PD:client:ErrClientGetMember]get member failed”]
[2024/03/15 00:41:36.166 +00:00] [ERROR] [tso_dispatcher.go:202] [“[tso] tso request is canceled due to timeout”] [dc-location=global] [error=“[PD:client:ErrClientGetTSOTimeout]get TSO timeout”]
[2024/03/15 00:41:36.166 +00:00] [ERROR] [tso_dispatcher.go:498] [“[tso] getTS error after processing requests”] [dc-location=global] [stream-addr=http://192.168.0.160:2379] [error=“[PD:client:ErrClientGetTSO]get TSO failed, %v: [PD:client:ErrClientTSOStreamClosed]encountered TSO stream being closed unexpectedly”]
[2024/03/15 00:41:36.167 +00:00] [ERROR] [pd.go:236] [“updateTS error”] [txnScope=global] [error=“[PD:client:ErrClientTSOStreamClosed]encountered TSO stream being closed unexpectedly”]
[2024/03/15 00:53:11.374 +00:00] [ERROR] [pd_service_discovery.go:284] [“[pd] failed to update service mode”] [urls=“[http://192.168.0.160:2379]”] [error=“[PD:client:ErrClientGetClusterInfo]error:rpc error: code = DeadlineExceeded desc = context deadline exceeded target:192.168.0.160:2379 status:READY: error:rpc error: code = DeadlineExceeded desc = context deadline exceeded target:192.168.0.160:2379 status:READY”]
[2024/03/15 00:53:11.377 +00:00] [ERROR] [pd_service_discovery.go:284] [“[pd] failed to update service mode”] [urls=“[http://192.168.0.160:2379]”] [error=“[PD:client:ErrClientGetClusterInfo]error:rpc error: code = Unavailable desc = error reading from server: EOF target:192.168.0.160:2379 status:CONNECTING: error:rpc error: code = Unavailable desc = error reading from server: EOF target:192.168.0.160:2379 status:CONNECTING”]
[2024/03/15 00:53:11.377 +00:00] [ERROR] [tso_dispatcher.go:202] [“[tso] tso request is canceled due to timeout”] [dc-location=global] [error=“[PD:client:ErrClientGetTSOTimeout]get TSO timeout”]
[2024/03/15 00:53:11.377 +00:00] [ERROR] [tso_dispatcher.go:498] [“[tso] getTS error after processing requests”] [dc-location=global] [stream-addr=http://192.168.0.160:2379] [error=“[PD:client:ErrClientGetTSO]get TSO failed, %v: rpc error: code = Unavailable desc = error reading from server: EOF”]
[2024/03/15 00:53:11.378 +00:00] [ERROR] [pd.go:236] [“updateTS error”] [txnScope=global] [error=“rpc error: code = Unavailable desc = error reading from server: EOF”]
[2024/03/15 00:53:11.478 +00:00] [ERROR] [pd_service_discovery.go:257] [“[pd] failed to update member”] [urls=“[http://192.168.0.160:2379]”] [error=“[PD:client:ErrClientGetMember]get member failed”]
[2024/03/15 01:04:24.717 +00:00] [ERROR] [tso_dispatcher.go:202] [“[tso] tso request is canceled due to timeout”] [dc-location=global] [error=“[PD:client:ErrClientGetTSOTimeout]get TSO timeout”]
[2024/03/15 01:04:24.718 +00:00] [ERROR] [tso_dispatcher.go:498] [“[tso] getTS error after processing requests”] [dc-location=global] [stream-addr=http://192.168.0.160:2379] [error=“[PD:client:ErrClientGetTSO]get TSO failed, %v: rpc error: code = Canceled desc = context canceled”]
There will be several times when it reaches 6000%, and it will drop quickly after reaching it.
Consider network interruptions and check with network monitoring.
Is there only one PD in total? Try expanding the PD to three.
Okay, I’ll give it a try.
Separate the PD nodes and do not mix them with TiDB…
It looks like it crashed and then came back up again.
TiDB needs to communicate with PD, but it seems that it cannot connect to PD. Separate PD and check the topsql at this point in time.
I’ve encountered a similar issue. It might be due to large SQL queries or batch tasks running simultaneously during that period, causing an OOM (Out of Memory) error. Subsequently, the SQL execution might have completed or failed, leading to a decrease in resource usage.
It should be OOM. Check the slow logs and tidb logs.
Your configuration is interesting; the resources of several TiDB nodes are different. If you want to deploy them in a mixed manner, at least choose machines with higher resources. I suggest scaling out PD nodes on two machines with 64-core CPUs.