Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TIDB 单机集群启动失败
[TiDB Usage Environment] Production Environment / Test / Poc
[TiDB Version] tidb-community-server-v6.5.2-linux-amd64.tar
[Reproduction Path] Use tiup cluster start tidb-test --init to start the cluster
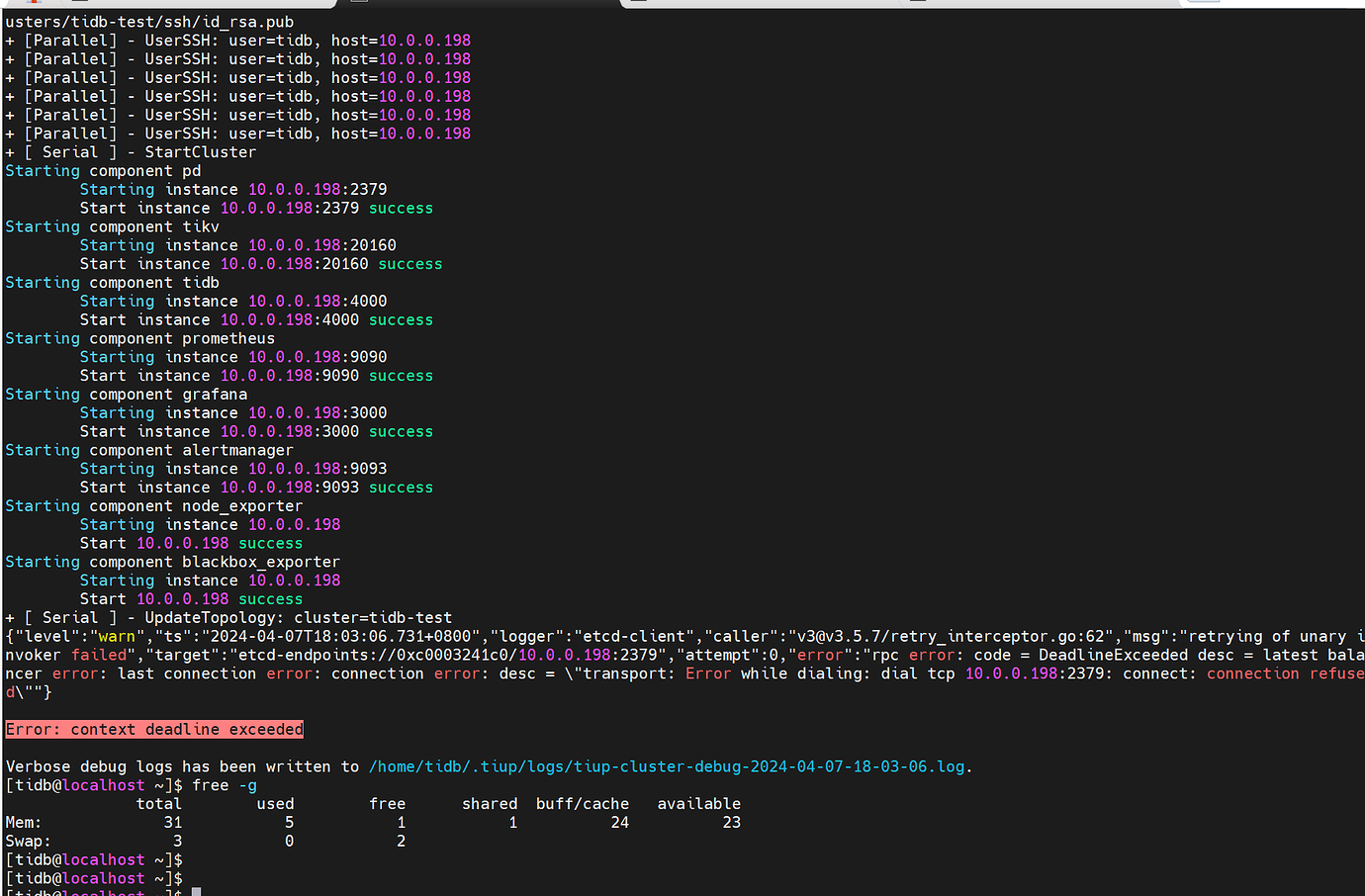
[Encountered Issue: Issue Phenomenon and Impact] Error when starting the cluster: Error: context deadline exceeded, resources are sufficient
[Resource Configuration] Enter TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachment: Screenshot/Log/Monitoring]
Use tiup cluster display tidb-test to check the cluster status.
Additionally, for single-machine deployment, you can just use the IP 127.0.0.1. Regardless of the machine’s IP, it can be accessed remotely.
Error in connection. According to its prompt, check the logs for any content.
The first step in troubleshooting is to check the logs. Without looking at the logs, it is very difficult to find the cause of the problem.
Port issue, file permission issue
Please provide the specific logs.
There is too little information. Check the logs and analyze further.
Is there a problem with the port?
It is recommended to upload the logs for further inspection regarding the port or permissions.
Refer to the documentation:
First, check the status and logs of the pd-server process to ensure that the pd-server has successfully started and the corresponding port is open: lsof -i:port.
If the pd-server is functioning normally, you need to check the connectivity between the tidb-server machine and the pd-server corresponding port. Ensure that the network segment is connected and the corresponding service port has been added to the firewall whitelist. You can check this using tools like nc or curl.
For example, suppose the tidb service is located at 192.168.1.100, and the pd that cannot be connected is located at 192.168.1.101, with 2379 as its client port. You can execute nc -v -z 192.168.1.101 2379 on the tidb machine to test if the port can be accessed. Or use curl -v 192.168.1.101:2379/pd/api/v1/leader to directly check if the pd is serving normally.
You can use tiup playground for quick deployment.
You’re experiencing a communication failure with etcd. Etcd stores the cluster metadata, and the cluster can’t function without it.
Is it because of a firewall or something?
According to the official documentation, I have quickly deployed several sets. I have never encountered this kind of problem. Usually, when I encounter a situation where it won’t start, I just delete it and reinstall it, and there are no issues.
You need to check if there are any related logs. You can search for the keyword “ERROR” to see if there are any error messages.