[TiDB Usage Environment] Production Environment
[TiDB Version] 5.2.1
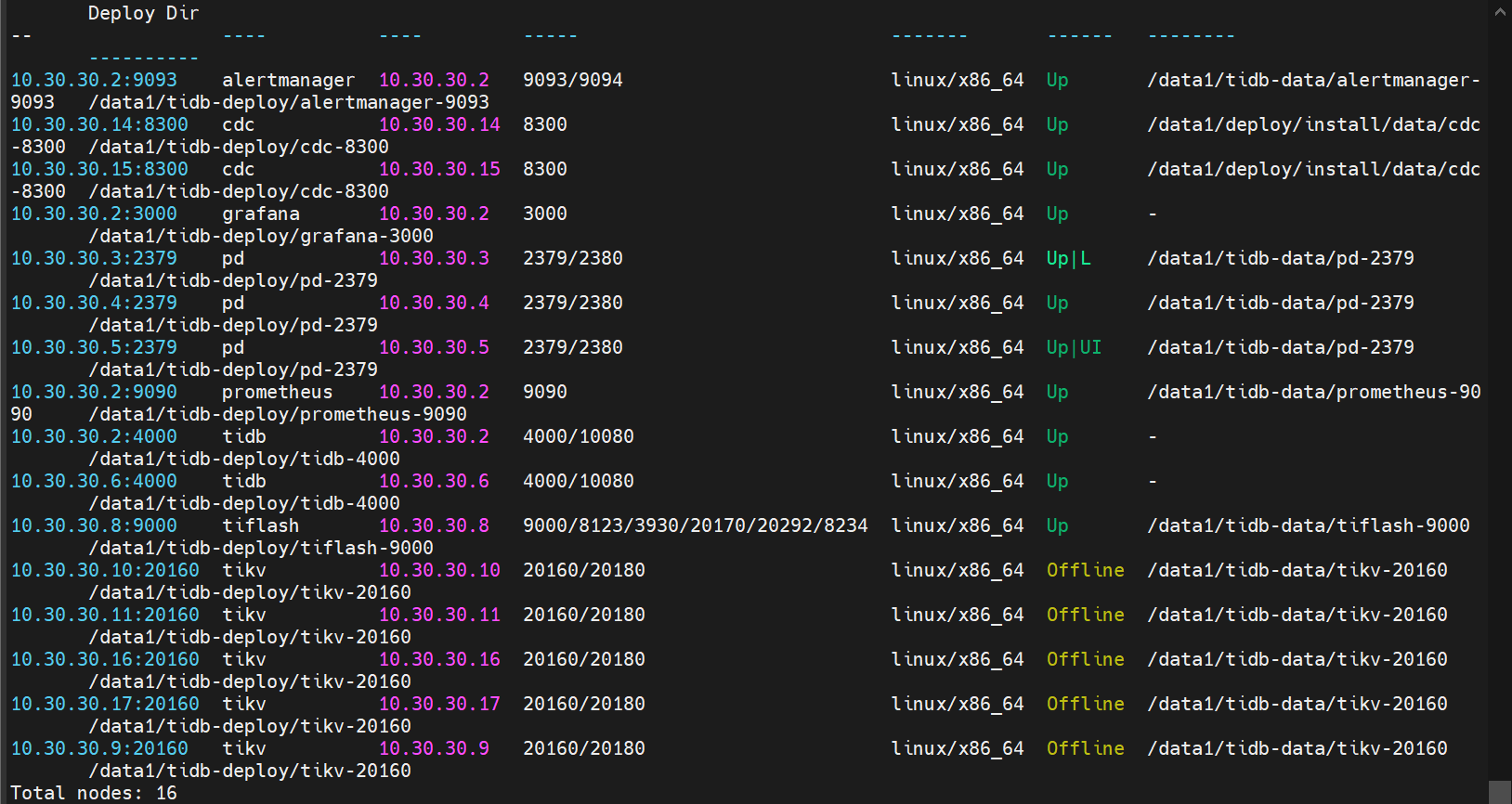
[Reproduction Path] TiFlash suddenly OOM, then it keeps automatically restarting and OOMing, unable to start. Scale-in and re-scale-out don’t work either. Manually deleting the synchronized store ID and synchronization rules in PD, it prompts successful deletion, but queries still show it. TiUP cluster display shows TiFlash as normal, but all TiKV nodes are in an offline state.
[Encountered Problem: Problem Phenomenon and Impact]
[Resource Configuration]
[Attachment: Screenshot/Log/Monitoring]
Before scaling TiFlash, is the TiFlash table canceled first?
Which specific rule (placement?) and operation method is this deletion referring to?
Use pd-ctl store to check if TiKV is offline, it might be related to the rules you deleted earlier. If Pd-ctl also shows it as offline, you can try the following command to see if it can be brought up:
curl -X POST http://:/pd/api/v1/store/<store_id>/state?state=Up
It should be fine now. Before scaling down, the synchronization table was canceled through ALTER TABLE SET TIFLASH REPLICA 0.
According to the official documentation 使用 TiUP 扩容缩容 TiDB 集群 | PingCAP 文档中心, the deletion rules are specified there. Because the deletion of the store is not very detailed, I thought all the store IDs queried by the command needed to be deleted. Fortunately, it can be restored.