Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tidb tikv scale-in后scale-out大量报错 pending-peer
[TiDB Usage Environment] Poc
[TiDB Version] v6.1.2
[Reproduction Path] Operations performed that led to the issue
There is an issue with a TiKV node. After scaling in and then scaling out, a large number of errors occurred.
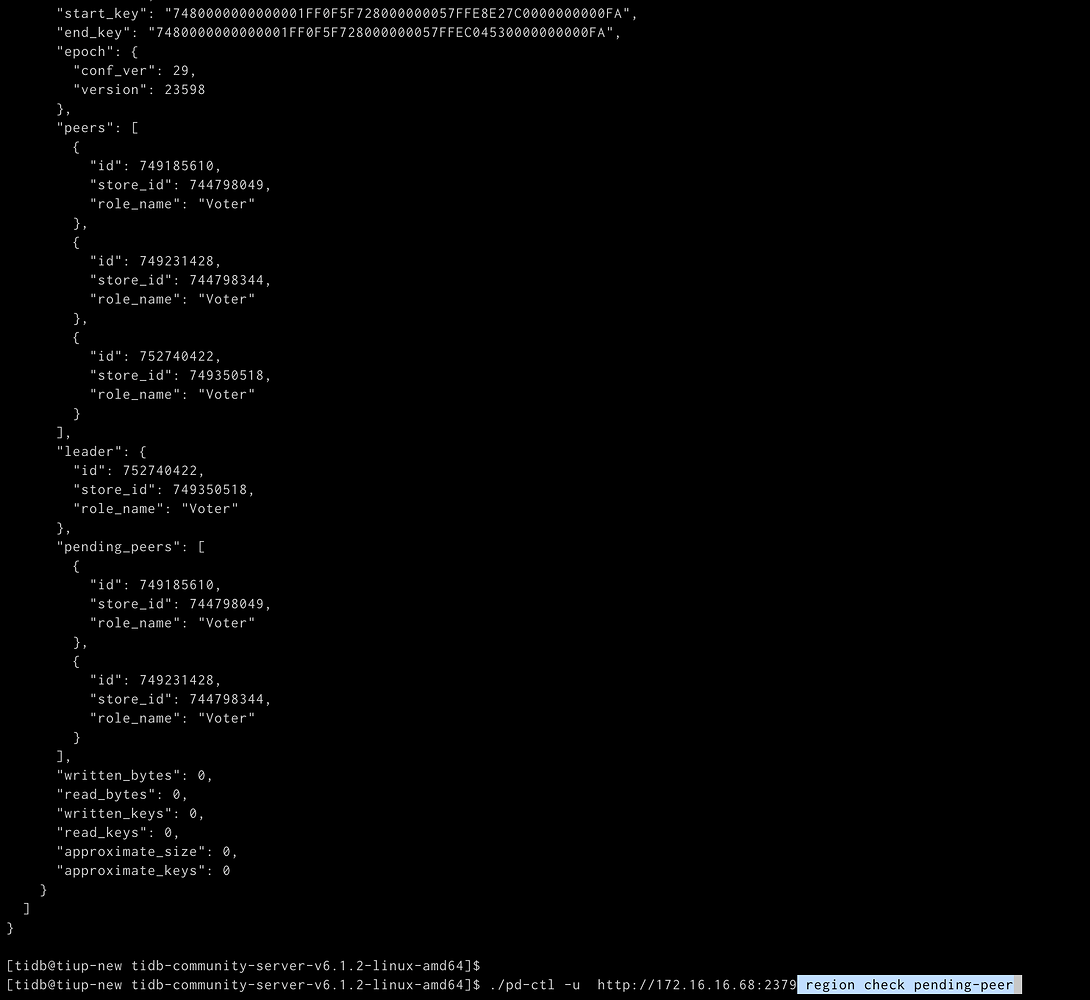
pending-peer
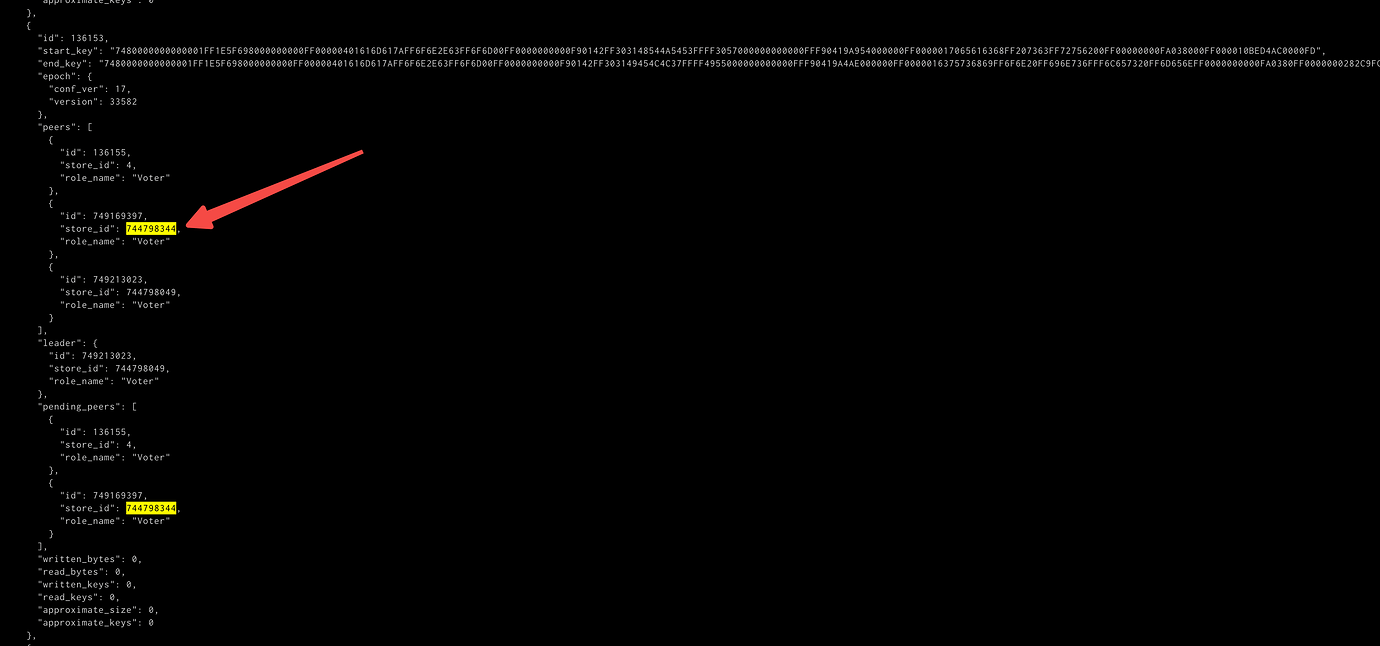
The store_id in the image no longer exists.
[Encountered Issue: Issue Phenomenon and Impact]
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
A normal intermediate state, Pending indicates that the raft log of the Follower or Learner has a significant lag compared to the Leader. A Follower in the Pending state cannot be elected as Leader.
After scaling in, all TiKV nodes need to balance the data. When scaling out, the balanced data needs to be moved again, which will result in many regions showing a pending status. Once these regions return to normal status, the scale-out process will be successful.
Error 9005 when querying - Region is unavailable, Time: 40.712000s
Basic troubleshooting for region unavailable:
Handling issues with scaling down and decommissioning:
tikv a lot of errors [2023/03/12 11:07:04.166 +08:00] [WARN] [endpoint.rs:621] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 159989, leader may None" not_leader { region_id: 159989 }”]
pd-ctl region xx
Check the status of those regions in the logs.
This post is not about the same system, right?
{
“id”: 749271237,
“start_key”: “7480000000000005FF9E5F728000000004FF8ACA9C0000000000FA”,
“end_key”: “7480000000000005FF9E5F728000000004FF8B7F850000000000FA”,
“epoch”: {
“conf_ver”: 870,
“version”: 3584
},
“peers”: [
{
“id”: 749271238,
“store_id”: 744798049,
“role_name”: “Voter”
},
{
“id”: 749271240,
“store_id”: 1,
“role_name”: “Voter”
},
{
“id”: 749271643,
“store_id”: 744798344,
“role_name”: “Voter”
},
{
“id”: 749350570,
“store_id”: 749350518,
“role”: 1,
“role_name”: “Learner”,
“is_learner”: true
}
],
“leader”: {
“role_name”: “Voter”
},
“written_bytes”: 0,
“read_bytes”: 0,
“written_keys”: 0,
“read_keys”: 0,
“approximate_size”: 0,
“approximate_keys”: 0
}
{
“id”: 749271237,
“start_key”: “7480000000000005FF9E5F728000000004FF8ACA9C0000000000FA”,
“end_key”: “7480000000000005FF9E5F728000000004FF8B7F850000000000FA”,
“epoch”: {
“conf_ver”: 870,
“version”: 3584
},
“peers”: [
{
“id”: 749271238,
“store_id”: 744798049,
“role_name”: “Voter”
},
{
“id”: 749271240,
“store_id”: 1,
“role_name”: “Voter”
},
{
“id”: 749271643,
“store_id”: 744798344,
“role_name”: “Voter”
},
{
“id”: 749350570,
“store_id”: 749350518,
“role”: 1,
“role_name”: “Learner”,
“is_learner”: true
}
],
“leader”: {
“role_name”: “Voter”
},
“written_bytes”: 0,
“read_bytes”: 0,
“written_keys”: 0,
“read_keys”: 0,
“approximate_size”: 0,
“approximate_keys”: 0
}
Is the store ID of the learner peer still there? In such cases where a leader cannot be elected, it might only be resolved by recreating the region or tombstoning the region. Refer to the previous documentation.
Both of these stores no longer exist.
- Directly locate abnormal regions.
(1) Regions without a leader
pd-ctl region --jq='.regions[]|select(has("leader")|not)|{id: .id,peer_stores: [.peers[].store_id]}'
(2) Regions with fewer than a certain number of peers
pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length==1) } '
(3) Check bad regions
./tikv-ctl --data-dir /data1/tidb-data/tikv-20160 bad-regions
For version 5.x: ./tikv-ctl --db /data1/tidb-data/tikv-20160/db bad-regions
First, locate these regions.
Then, there are three ways to handle them:
- Refer to recovery methods.
- If recovery is not possible, you can only rebuild.
- Choose to delete directly.
However, in some cases, when it is not convenient to remove the replica from PD, you can use the --force option of tikv-ctl to forcibly set it to tombstone:
tikv-ctl --data-dir /path/to/tikv tombstone -p
127.0.0.1:2379 -r <region_id>,<region_id> --force
The steps for scaling up and down were not handled correctly. First, follow the article on handling scaling exceptions to deal with that store.
After stopping the cluster, the TiKV log reports a warning: [2023/03/12 15:16:58.687 +08:00] [WARN] [endpoint.rs:621] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 226029, leader may None" not_leader { region_id: 226029 }”]
That store was forcibly deleted.
TiUP only forcibly deleted it on the surface, but there are still some unfinished processes inside. Refer to the document on scaling down for more details.
The three tricks are indeed powerful. I only used the second one and it solved the problem smoothly.