Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TIDB v5.0.0-rc漏扫修复修改server-version,reload部分节点报错
【TiDB Usage Environment】Testing
【TiDB Version】5.0.0-rc
【Reproduction Path】Edit-config to modify the server-version, then reload some nodes and report errors
【Encountered Issues: Problem Phenomenon and Impact】
【Resource Configuration】Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
【Attachments: Screenshots/Logs/Monitoring】
In the past, check with df -h to see if the disk is full.
The disks of the three nodes with errors are not full.
Are you sure you only changed the server-version? This should only require reloading the tidb-server, tikv and pd should not be affected.
Use tiup cluster edit-config <cluster-name> and send your entire system configuration file to take a look.
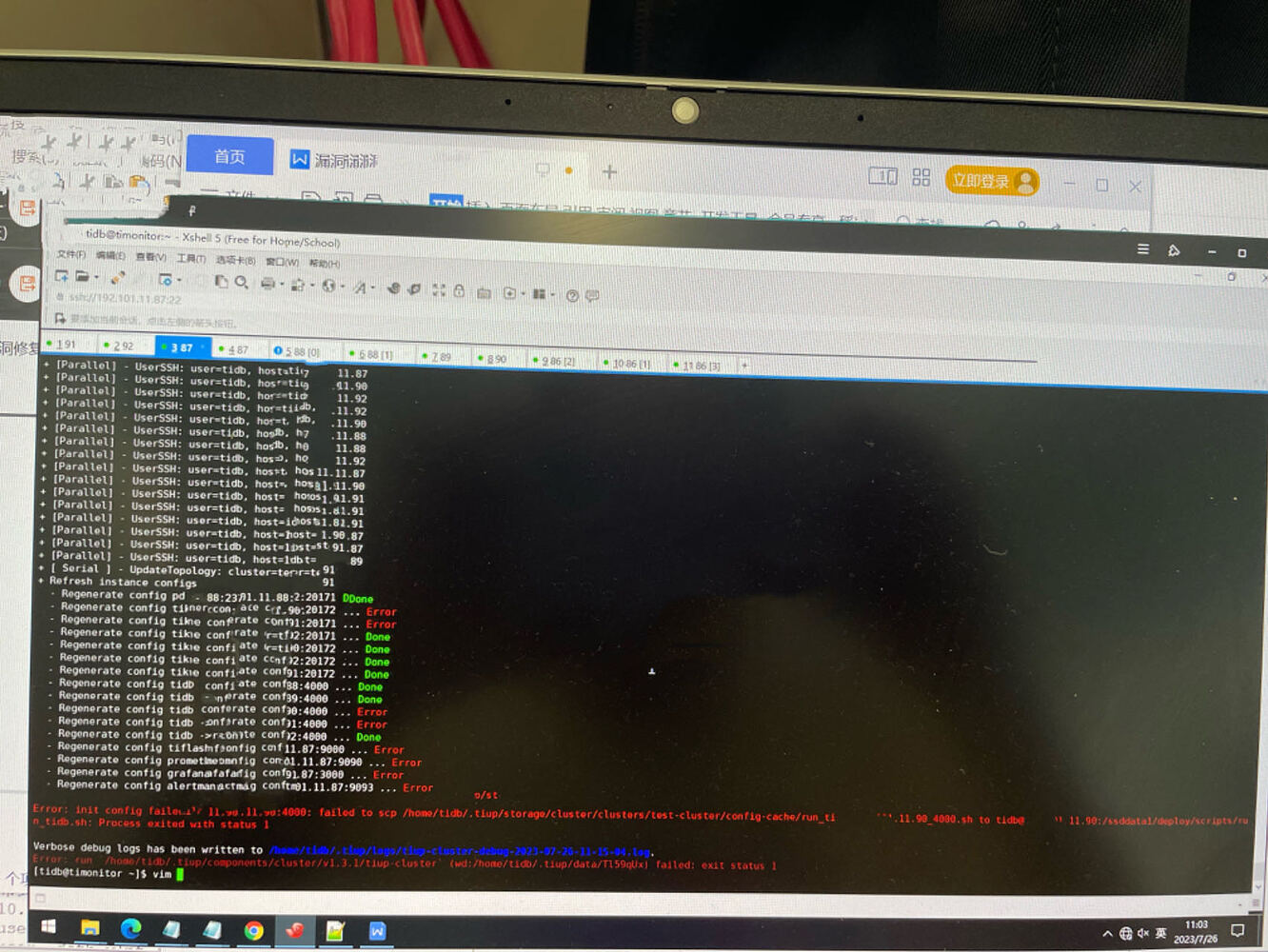
The log shows: 1. tiup generates the /tmp tidb.toml configuration file locally 2. scp it over. Your current issue is that the scp was unsuccessful. Generally, this is either because the disk is insufficient to generate the file or the target disk is insufficient to accept it, or due to network issues.
SCP not working, is it because SSH mutual trust is not configured for each node?
I didn’t check the cluster status before operating, and I suspect there might be issues with the cluster.
I can’t extract the configuration file, so I had to take photos. I have reverted the server version.
Is 87 your control machine? Try SSH from 87 to 87, 90, and 91. It seems that 88, 89, and 92 are fine.
You can SSH over; the node should have crashed a long time ago. The 90 tikv.log is from a long time ago.
So the configuration files on your nodes 87, 90, and 91 have been different for a long time, and the processes are gone? Is that why comparing them with the current configuration files revealed issues?
It looks like this. How can I fix it? Since I didn’t set this up, I’m not sure about the specifics. I see that the directory for datadir displayed is not present on the node. The node has /nvmedata1 and /nvmedata2, but not /ssddata1.
First, use tiup cluster meta backup <cluster-name> to back up the current cluster configuration. Then, use tiup cluster edit-config <cluster-name> to remove the information of the nodes that you are sure no longer exist (e.g., 87/90/91), and restart the cluster.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.