To improve efficiency, please provide the following information. Clear problem descriptions can lead to faster resolutions:
[TiDB Usage Environment]
Production Environment
[Overview] Scenario + Problem Overview
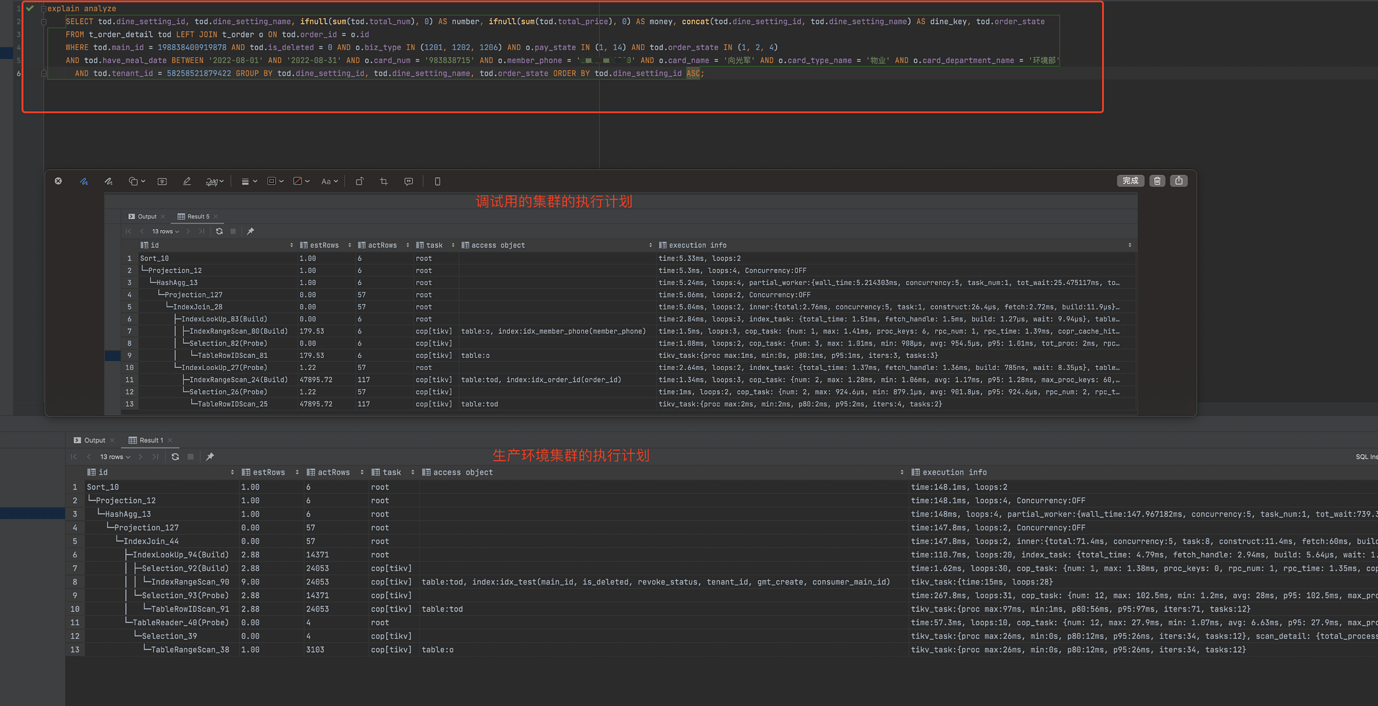
SQL query generates an inaccurate execution plan, leading to long SQL execution times.
[Background] Actions Taken
Synchronized production data to the debugging cluster, checked the SQL execution plan, and found that the SQL could correctly generate an accurate execution plan, achieving the expected query speed.
[Phenomenon] Business and Database Phenomenon
Business queries are too slow.
[Problem] Current Issues Encountered
1: Two clusters with the same data content and version generate different execution plans.
[Business Impact]
1: Slow queries.
[TiDB Version]
v5.4
Corresponding Module Logs (including logs 1 hour before and after the issue)
If the question is related to performance optimization or fault troubleshooting, please download the script and run it. Please select all and copy-paste the terminal output results for upload. tableSql (10.7 KB)
I have just uploaded the table structures of two tables. Both tables have around ten million records. By comparing the files, the table structures in the two clusters are consistent.
I found the reason. In the production environment cluster, the default value of tidb_analyze_version was changed from 2 to 1 by the operations team. The solution is to change the version back to 2, clear the statistics, and re-analyze the table. Finally, the SQL query will use the correct index.
Statistics in Version 2 avoid the significant errors that could occur in large datasets due to hash collisions in Version 1, while maintaining estimation accuracy in most scenarios.