Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: TIDB写入超级慢
To improve efficiency, please provide the following information. A clear problem description will help solve the issue faster:
【TiDB Usage Environment】
TiDB v5.4.0, TiKV configuration: 20 vCPU, 256GB memory, regular STAT mechanical hard drive
【Overview】 Scenario + Problem Overview
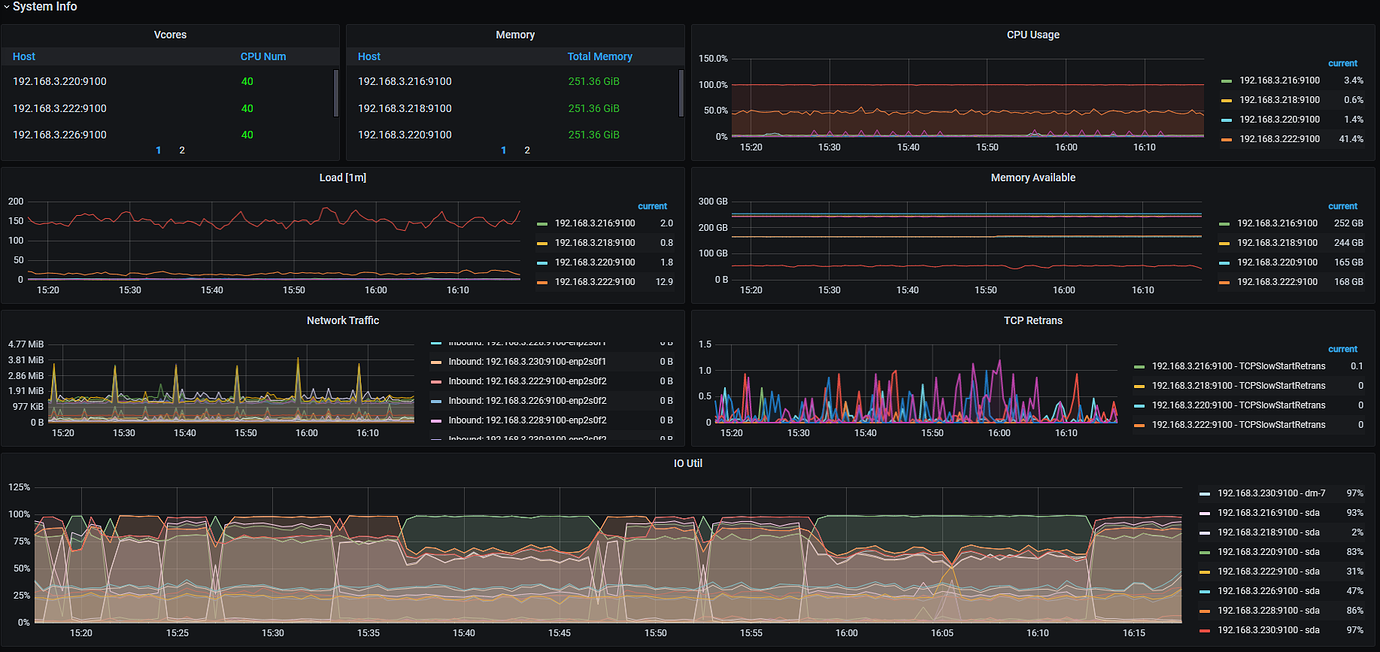
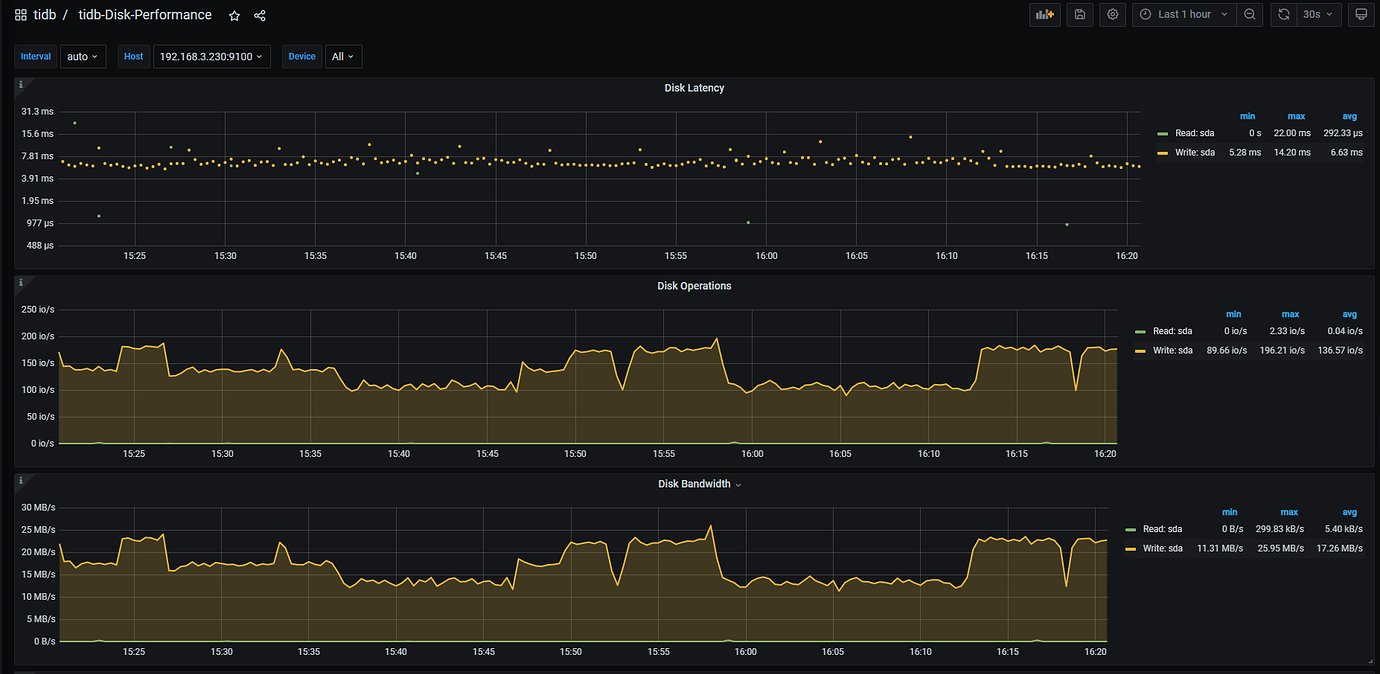
3 TiDB + 3 TiKV cluster + 2 TiFlash, write speed is around 200 records per second, Disk Latency delay is 5~10ms. Another cluster with the same TiDB v5.4.0 and TiKV configuration (20 vCPU, 256GB memory, regular STAT mechanical hard drive) is 4~6 times faster than this one.
【Background】 Actions taken
Newly deployed cluster
【Phenomenon】 Business and database phenomena
Data write to business table is extremely slow, database Disk IO Utilization is 58%~98%, avg 84%
【Problem】 Current issue encountered
How to solve this? No clue where the problem lies. PS: Stopped all read/write operations on the entire cluster, but writing to a table without a primary key is still slow.
【Business Impact】
Write speed is not improving, data delay is too long
【TiDB Version】
TiDB v5.4.0
【Application Software and Version】
【Attachments】 Relevant logs and configuration information
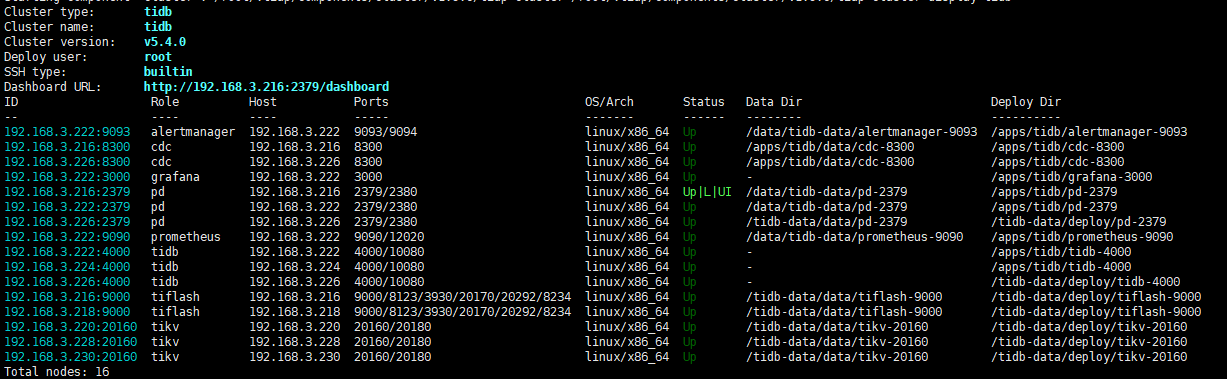
- TiUP Cluster Display Information
Removing mixed deployment of tidb, pd, CDC has the same effect
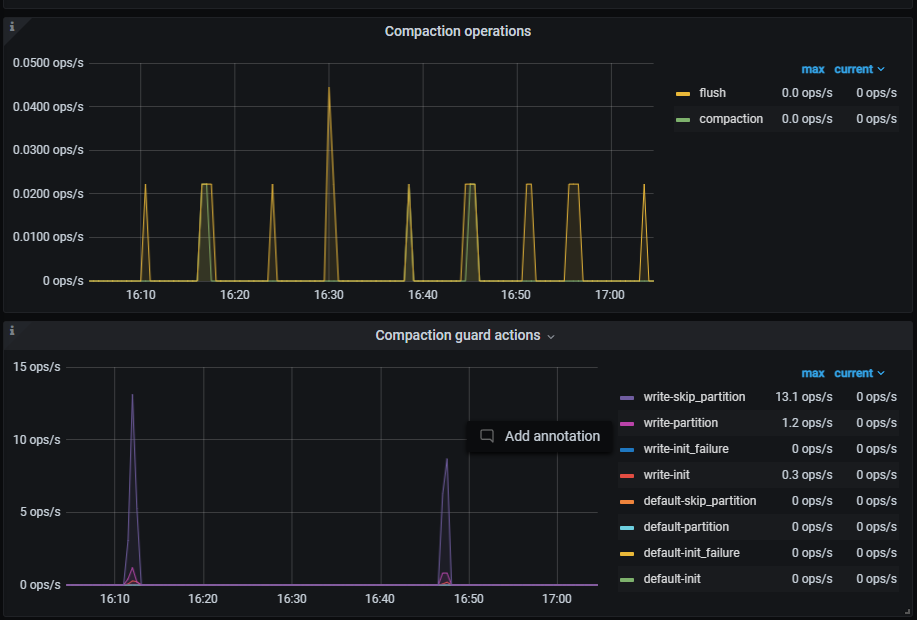
Monitoring (https://metricstool.pingcap.com/)
- TiDB-Overview Grafana Monitoring
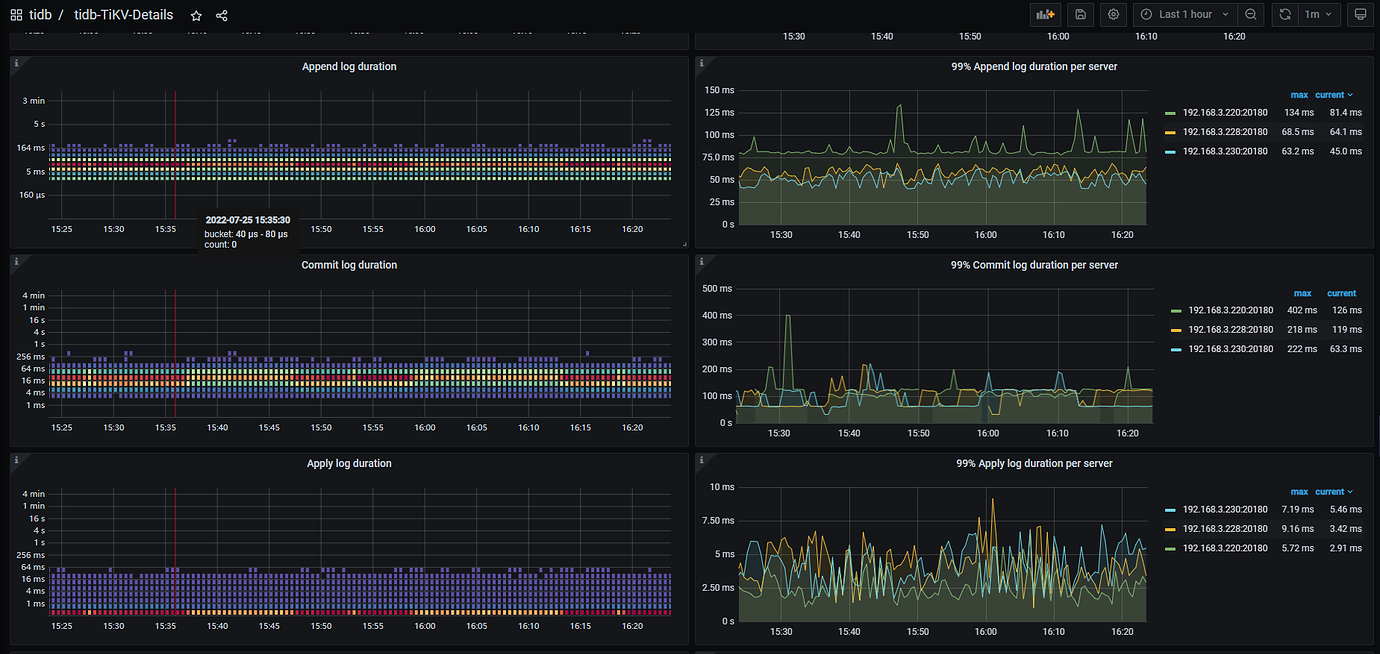
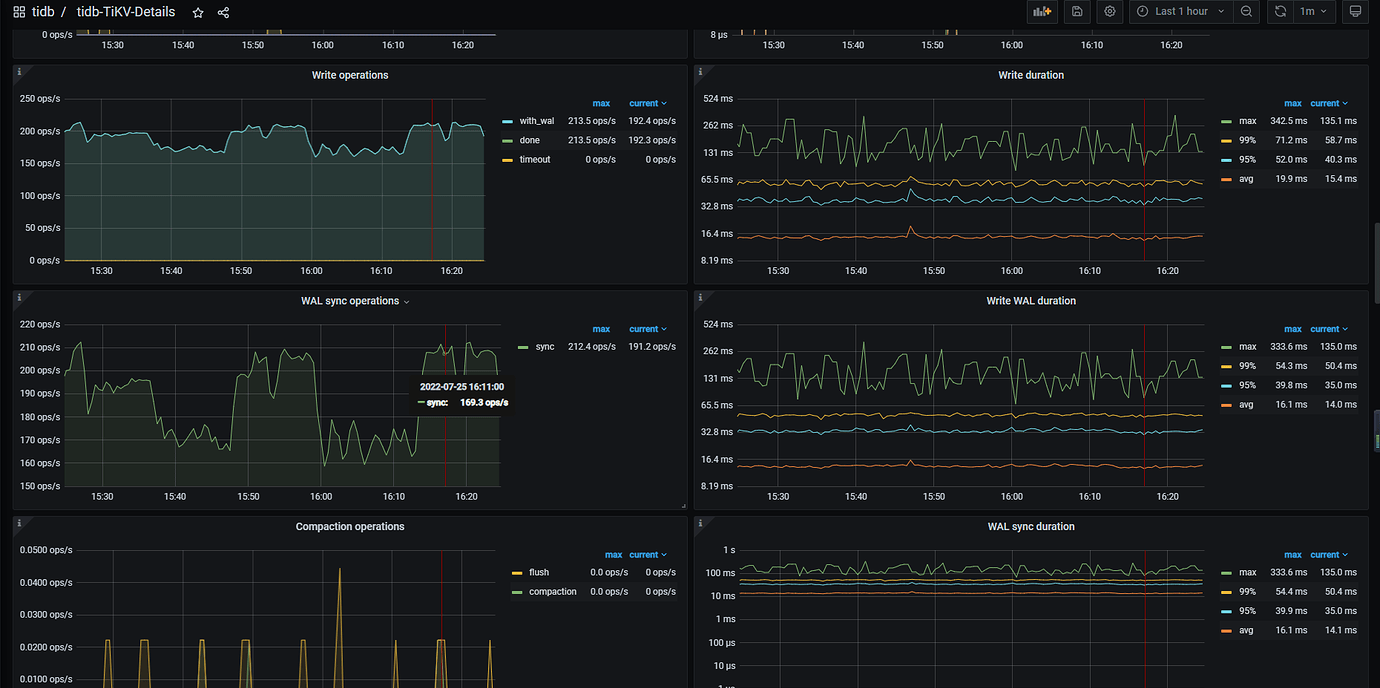
- TiKV Grafana Monitoring