Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tiflash 报错
[TiDB Usage Environment] Production Environment / Test / Poc
Production Environment
[TiDB Version]
5.3
[Encountered Problem]
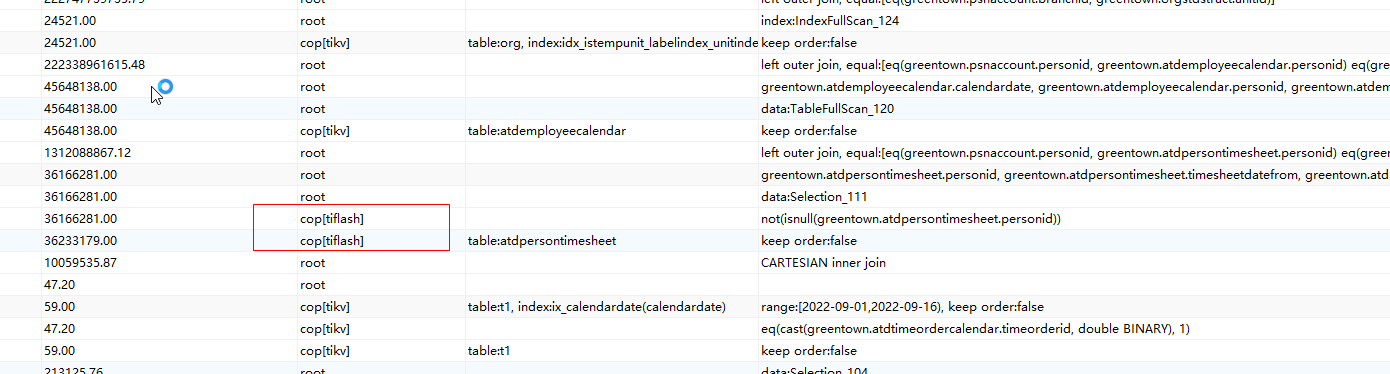
SQL query error
[Reproduction Path] What operations were performed to cause the problem
[Problem Phenomenon and Impact]
After adding a TiFlash node to the existing TiDB cluster, executing long-running SQL queries using Navicat reports the following error:
2013 - Lost connection to MySQL server during query
The following errors appear in the TiFlash logs, not sure if they are related:
2022.10.16 09:24:51.975714 [39737] pingcap.pd: Receive TsoResponse failed
2022.10.16 09:24:51.975778 [39737] pd/oracle: update ts error: Exception: Receive TsoResponse failed
2022.10.16 09:24:53.976258 [39737] pingcap.pd: Receive TsoResponse failed
2022.10.16 09:24:53.976306 [39737] pd/oracle: update ts error: Exception: Receive TsoResponse failed
2022.10.16 09:24:53.977036 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379
2022.10.16 09:24:54.050870 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379
2022.10.16 09:24:54.831483 [16] pingcap.pd: get safe point failed: 2: rpc error: code = Unavailable desc = not leader
2022.10.16 09:24:54.832153 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379
2022.10.16 09:24:55.166030 [16] pingcap.pd: get safe point failed: 2: rpc error: code = Unavailable desc = not leader
2022.10.16 09:24:55.166628 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379
2022.10.16 09:24:56.005505 [16] pingcap.pd: get safe point failed: 2: rpc error: code = Unavailable desc = not leader
2022.10.16 09:24:56.006069 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379
2022.10.16 09:24:57.730025 [16] pingcap.pd: get safe point failed: 2: rpc error: code = Unavailable desc = not leader
2022.10.16 09:24:57.730672 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379
2022.10.16 09:24:57.982660 [39737] pingcap.pd: Receive TsoResponse failed
2022.10.16 09:24:57.982698 [39737] pd/oracle: update ts error: Exception: Receive TsoResponse failed
2022.10.16 09:24:57.983241 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379
2022.10.16 09:24:59.647515 [16] pingcap.pd: get safe point failed: 2: rpc error: code = Unavailable desc = not leader
2022.10.16 09:24:59.648101 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379
2022.10.16 09:25:01.988044 [39737] pingcap.pd: Receive TsoResponse failed
2022.10.16 09:25:01.988095 [39737] pd/oracle: update ts error: Exception: Receive TsoResponse failed
2022.10.16 09:25:01.988677 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379
2022.10.16 09:25:02.635989 [16] pingcap.pd: get safe point failed: 2: rpc error: code = Unavailable desc = not leader
2022.10.16 09:25:02.636562 [39738] pingcap.pd: failed to get cluster id by: http://10.215.200.186:2379