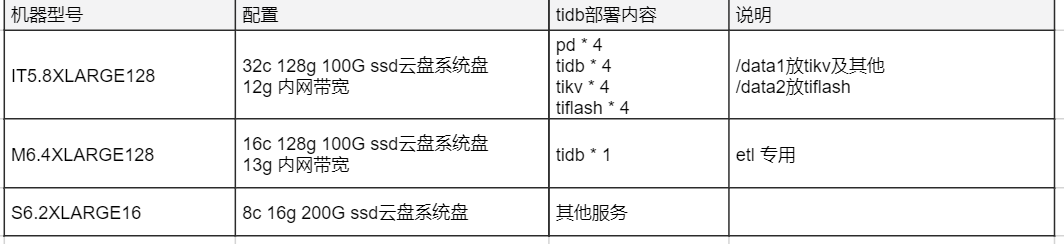
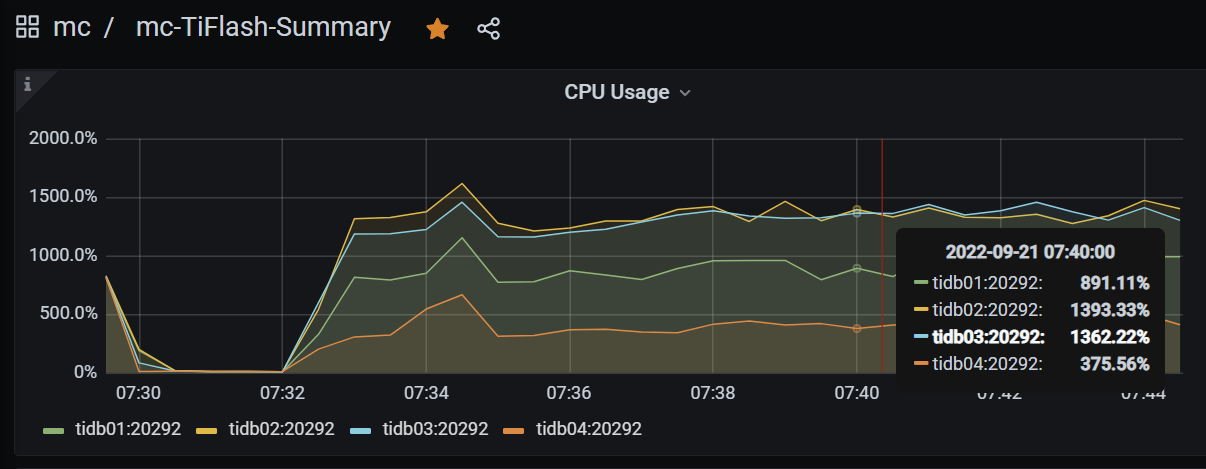
Performed stress testing on this cluster, with 20 concurrent replays of about 4.5 million SQLs.
The SQL ratio is about 95% for AP and 5% for TP, captured from the production environment, involving almost half of the tables.
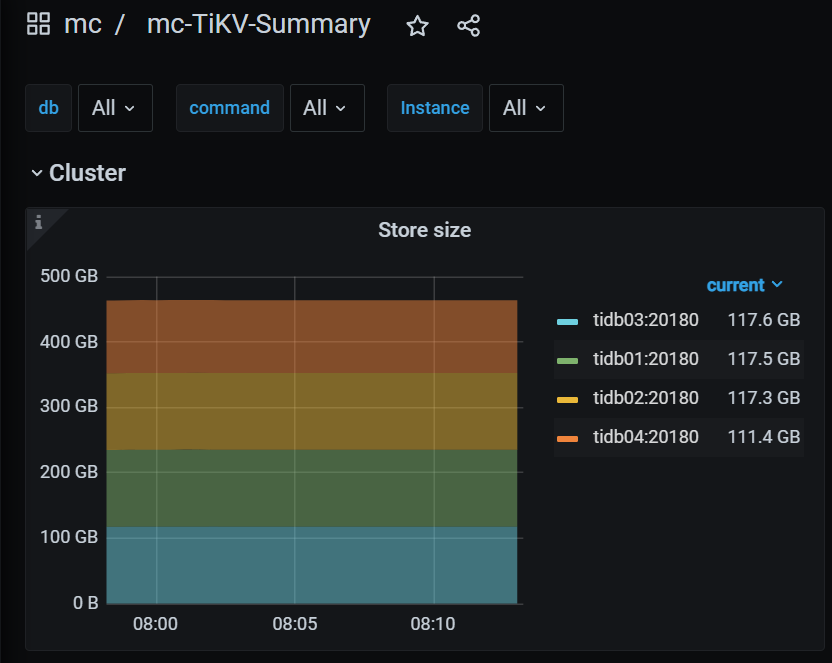
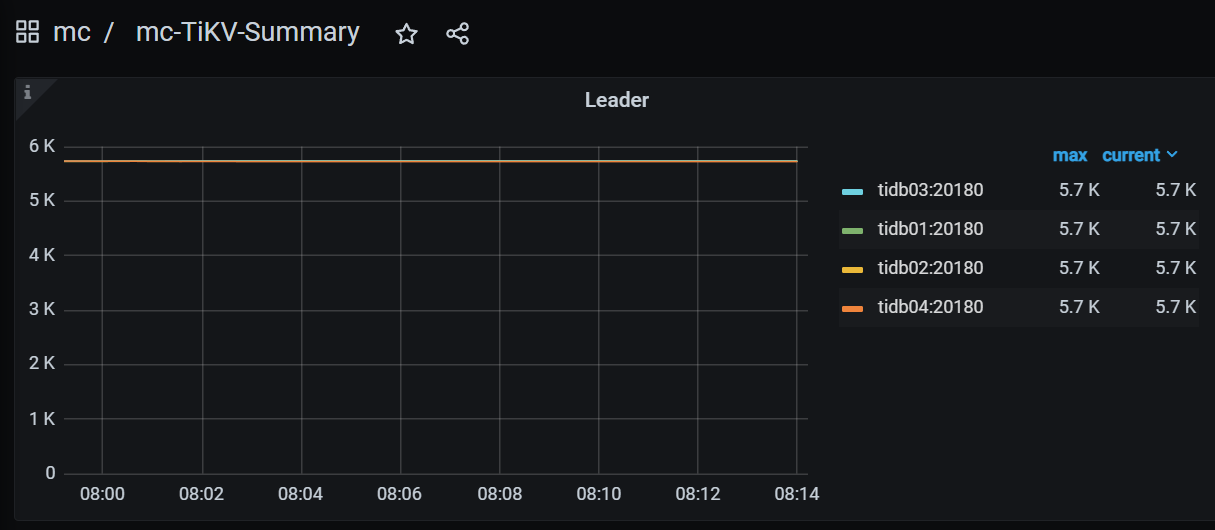
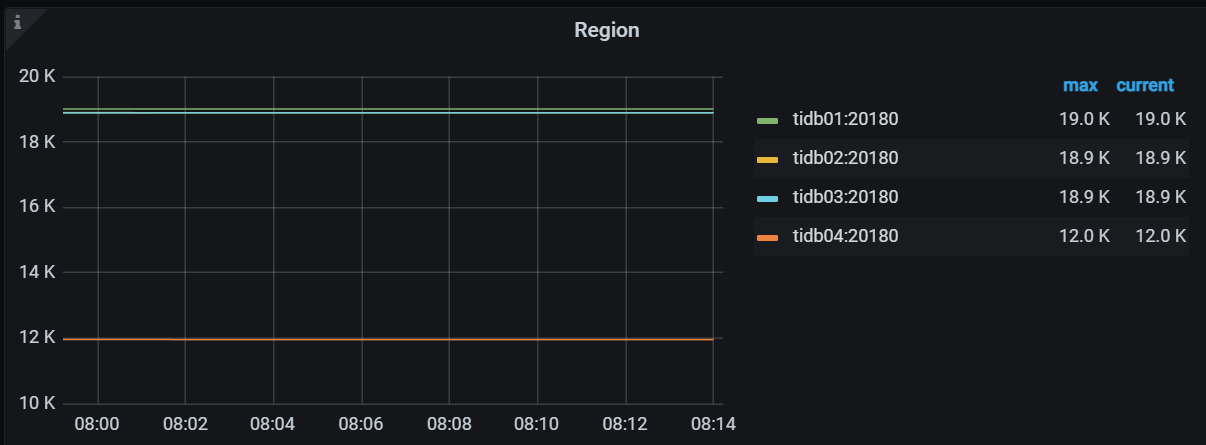
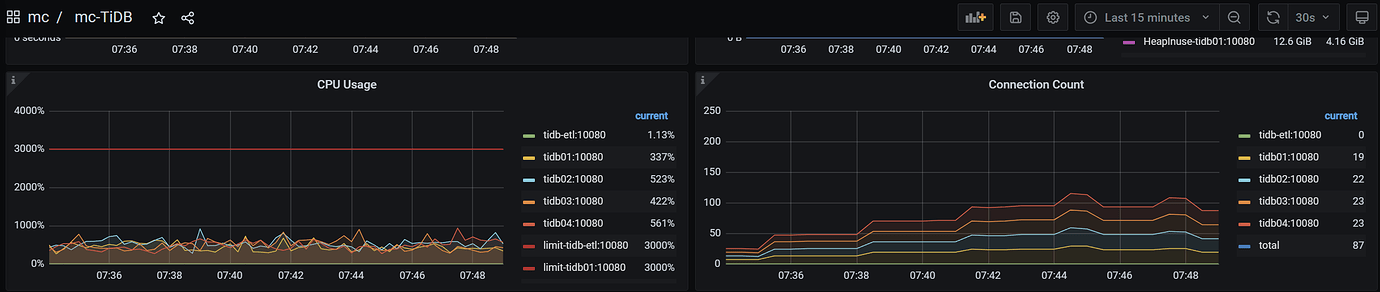
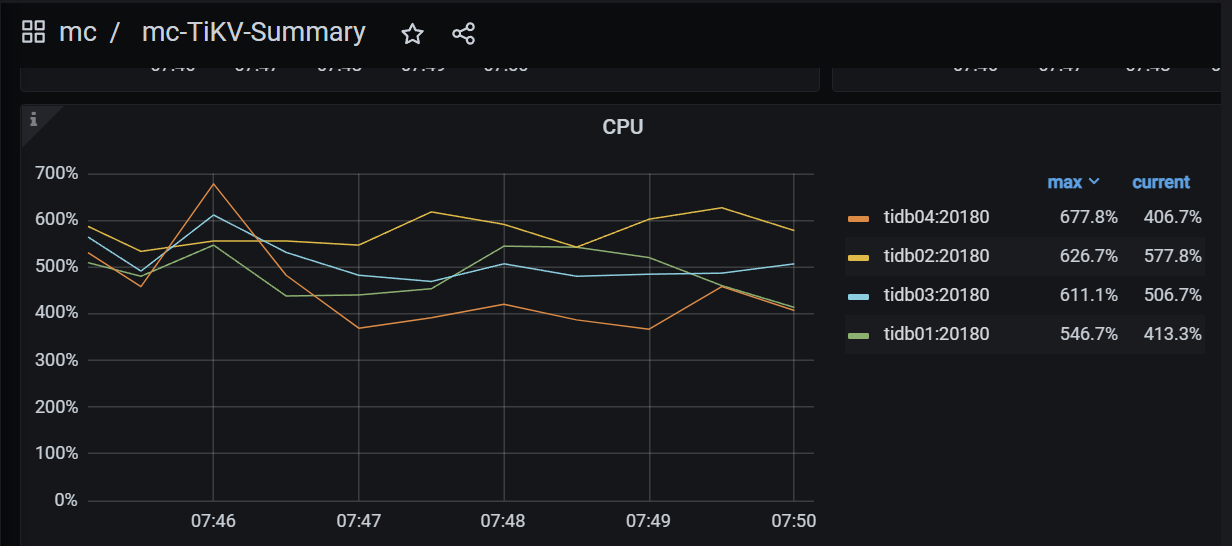
The 4 tidb nodes have evenly distributed connections and relatively balanced CPU load:
I noticed there is an issue related to this problem on GitHub, which is still open:
According to the description in the issue, if a tiflash node goes down and then recovers, the region cache of tidb will cause it to have no load.
For this reason, I restarted all tidb services (tiup cluster restart xxx -R tidb -y).
After rerunning the stress test, no tiflash service anomalies occurred.
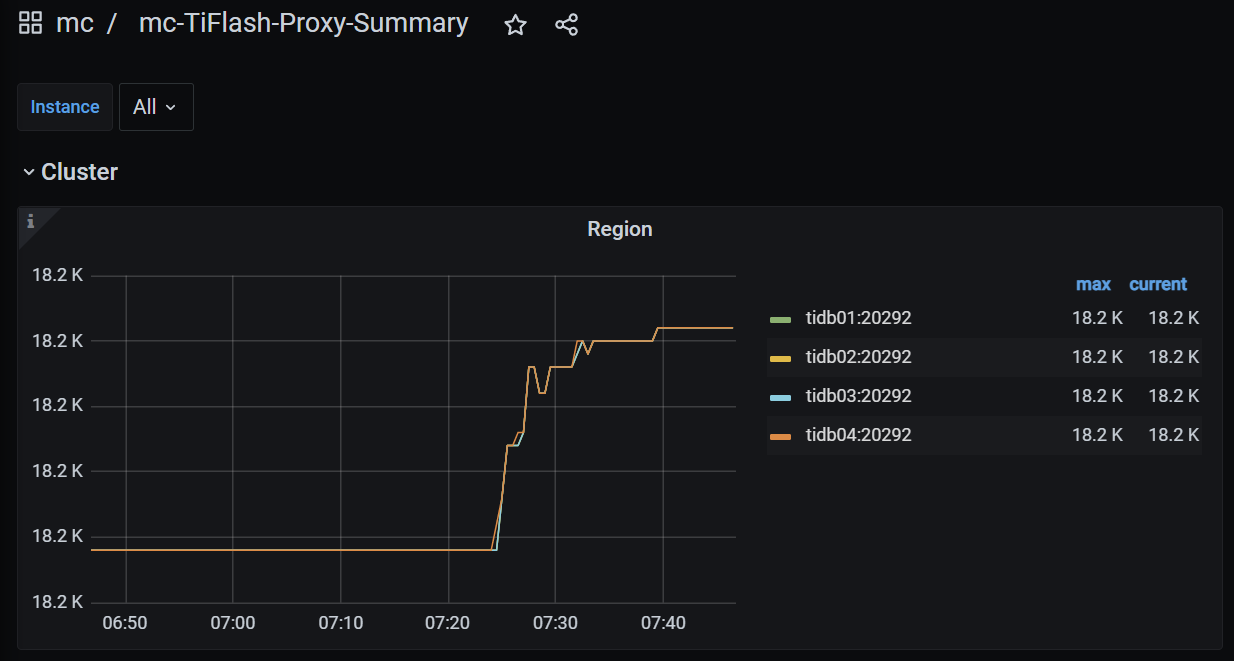
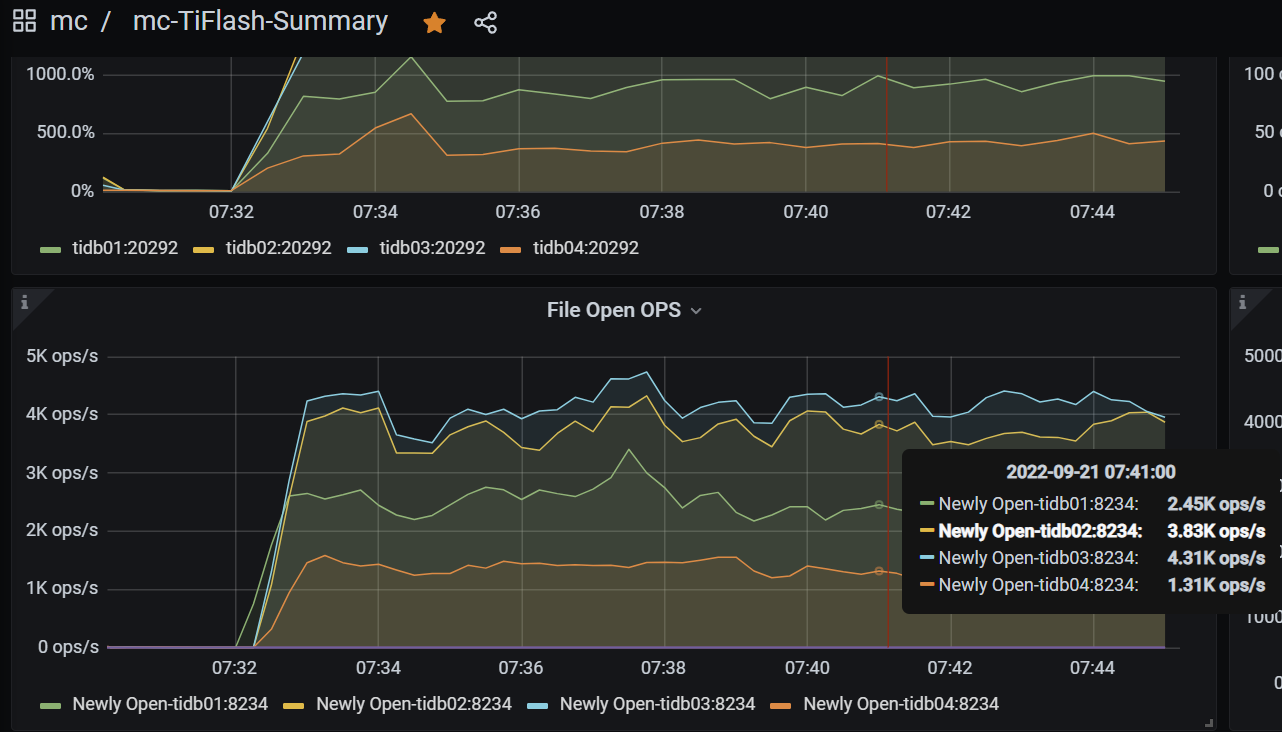
The load on tiflash is still very unbalanced, but the load ratio of each node has changed significantly:
Next, I restarted the entire cluster (tiup cluster restart xxx -y).
After rerunning the stress test, no tiflash service anomalies occurred.
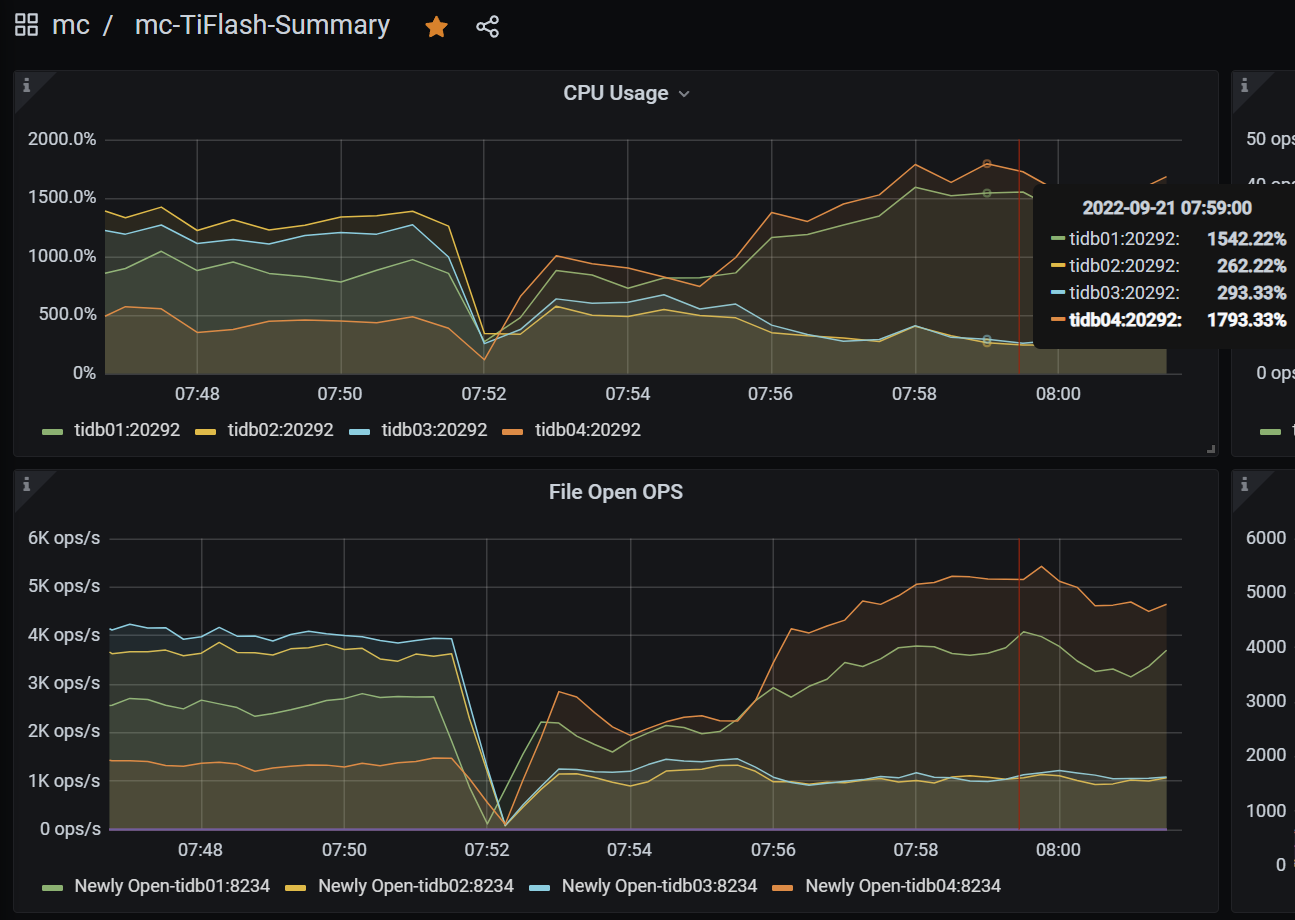
The tiflash load is similar to the previous figure:
Currently, when TiDB generates TiFlash MPP tasks, it balances all regions of the table across all TiFlash nodes. For example, if the table has 100 regions, TiDB will try to ensure that each TiFlash reads 25 regions. In your scenario, there should be 4 nodes with 4 replicas, so it should ensure that each TiFlash reads 25 regions.
However, TiDB only performs this balancing within a single query. If the table has relatively few regions, for instance, in an extreme case where there is only one region, and there are 100 concurrent reads to this table, TiDB MPP currently does not balance between queries. Therefore, in such cases, it is possible for the load to be uneven across different TiFlash nodes. Considering your cluster has over 4000 tables but only 23,000 regions, this situation could occur.
You can enable TiDB’s debug log, which will show logs similar to the following for MPP queries:
Before region balance xxxx
After region balance xxxx
Let me continue to ask:
Assuming there are 4 nodes named A, B, C, and D, and the SQL is executed on the TiDB service of node A.
Assuming this SQL only involves one region of a table, and this region has 4 TiFlash replicas available on nodes A, B, C, and D, what is the logic for choosing which replica to use?
If accessing TiFlash using MPP or BatchCop, a replica of a region is chosen and used continuously until an error is encountered on that replica. If accessing TiFlash using cop, each query will switch to the next replica.
This indeed explains my observation. Was this balance logic added recently? When I first used version 5.4 for stress testing, it seemed quite balanced.
In my real business scenario, the data distribution and SQL distribution are causing TiFlash resources to be wasted. What can I do to achieve load balancing? Are there any parameters that can be set?
I studied the code and changed this parameter from false to true.
Because I found that inside the GetTiFlashRPCContext function, if loadBalance = false, it always returns the first store found, which causes a hotspot. If changed to true, it will switch each time.
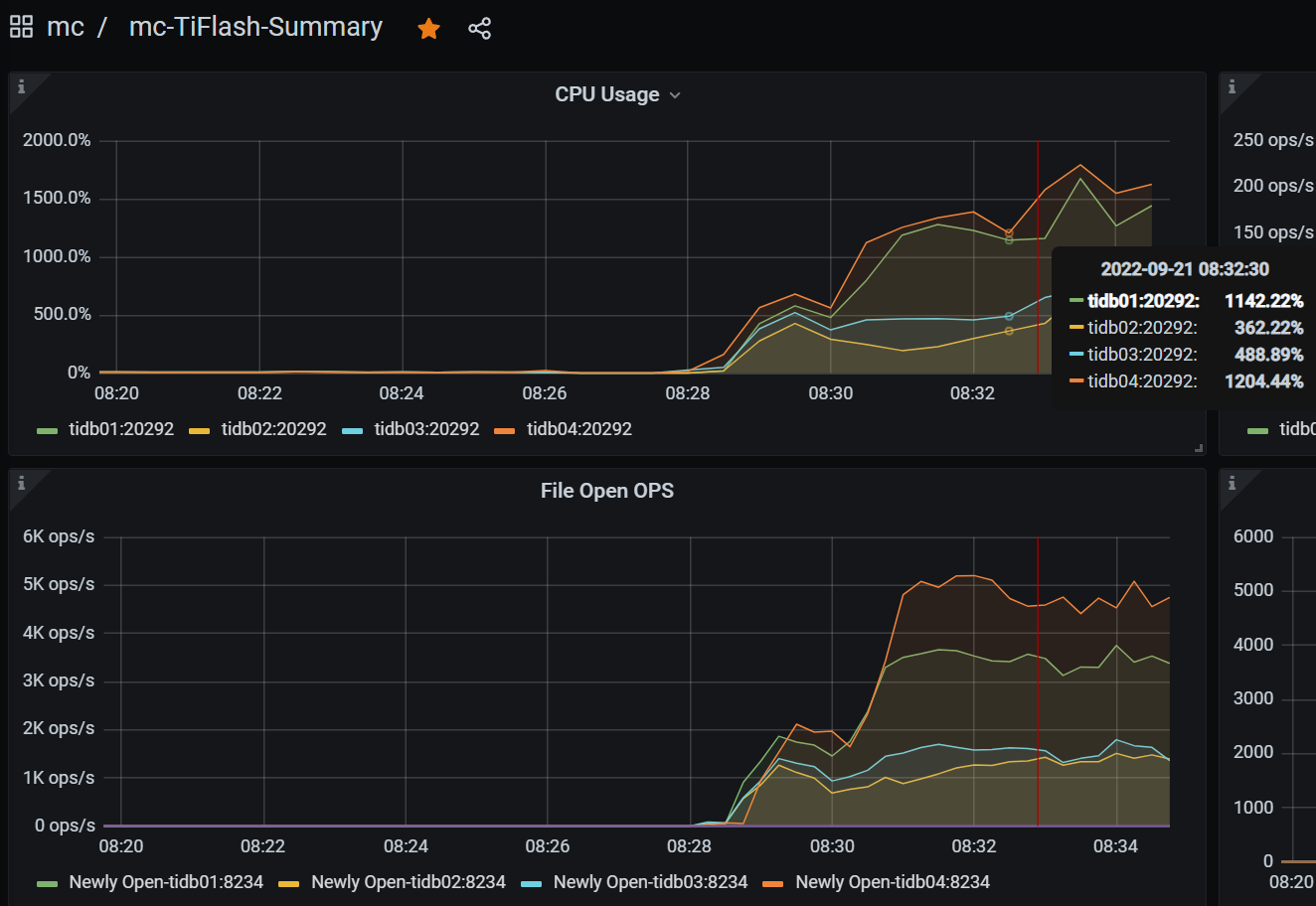
After compiling and replacing, the load test is completely balanced:
However, I don’t know the original consideration for passing in false, and what side effects there might be if changed to true? Is it as mentioned in the comment:
// loadBalance is an option. For MPP and batch cop, it is pointless and might cause trying the failed store repeatedly.
If it’s just this, then in my business scenario, it is acceptable because the probability of store failure is still very small.
This is due to historical reasons. Currently, for MPP, it can be completely changed to true. There might still be issues with batchCop, but since batchCop can basically be completely replaced by MPP, changing it to true is not a problem.
If you are not confident about batchCop, you can check whether mppStoreLastFailTime is nil. If it is not nil, it is MPP; if it is nil, it is batchCop. This way, you can enable region load balance only for MPP.
I ran all the stress tests overnight without any issues.
So I simply changed this parameter.
I suggest that TiDB could add a parameter in the new version to control this balance.
Thanks for the guidance!
Yes, after we added load balancing within queries, we overlooked load balancing between queries. We are planning to fix this issue in the latest version of TiDB.