Start 8 nodes, where 3 nodes have the label disk_type=mix, and the other 5 nodes have the label disk_type=ssd. Then, load data and observe that there is no leader on the mix nodes, which is expected.
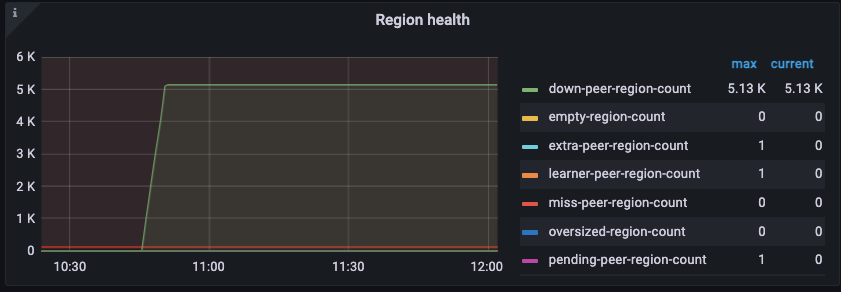
After disabling the placement-rule, down-peer starts to recover normally.
I don’t know if this is due to a problem with the logic of the placement rule itself causing the replica to be incomplete or if my policy is causing it to be incomplete.
I don’t see any problem with your rule either.
You could manually add an operator to add a replica when a down-peer appears and see if it succeeds.
I don’t know much about placement rules, so I’ll also wait for others to solve it.
No special modifications, it should be the default value of 30m.
It is worth noting that after I disabled the placement rule, the cluster was able to automatically complete the replicas immediately. I suspect the issue lies with the placement rule.
Yes, we have many instances deployed on k8s.
Since we are using rawkv, there is no way to define it with SQL.
If we use SQL, what would the actual plan look like? Would I still encounter the same issue?
If there is a server with 2 or more TiKV deployments, then it is not unusual.
I understand that placement is configured through the SQL interface. I don’t know if there is the same issue, I can only suggest trying it out. Higher versions recommend using SQL for configuration. But you are using rawkv.
3. I don’t have any good suggestions, just wait for other experts or check the answers to your issue.
I suspect this is the cause. It seems that your configuration requires at least one follower replica on label disk_type=mix. Configuring Placement Rule through PD by yourself can easily lead to problems. What is the background for doing this? What effect are you trying to achieve? It looks like you want to decommission the three nodes with label disk_type=mix?