Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tikv硬盘故障 tidb集群无法启动
[TiDB Usage Environment] Production Environment
[TiDB Version] 5.2.4
[Reproduction Path]
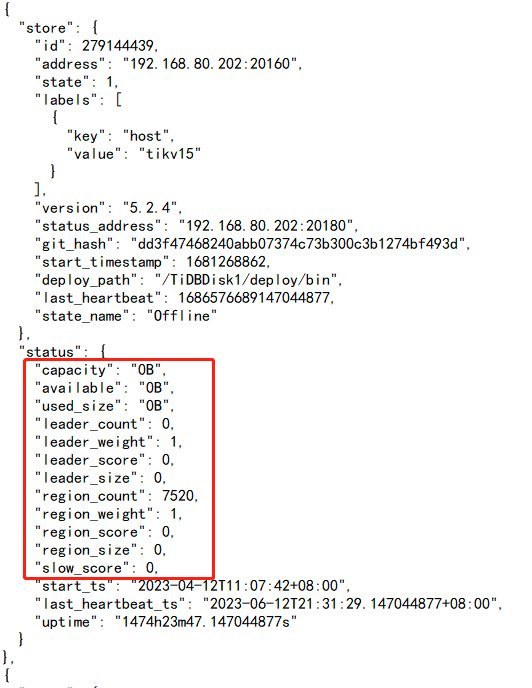
There was a power outage in the park last night. The TiDB cluster service was stopped before the power outage. After turning on the machine this morning, the system reported an error that two SSDs of TiKV could not be recognized. After changing the slots, the system still could not recognize these two disks, and the cluster could not be started. The TiKV capacity is 12TB, with 5TB used. How can I skip these two disks to start TiKV? How should this situation be handled?
What is the error message when the cluster fails to start?
Whether it’s a production or testing environment, since TiKV has multiple replicas, you can change the new machine, update the configuration file, and restart the cluster service.
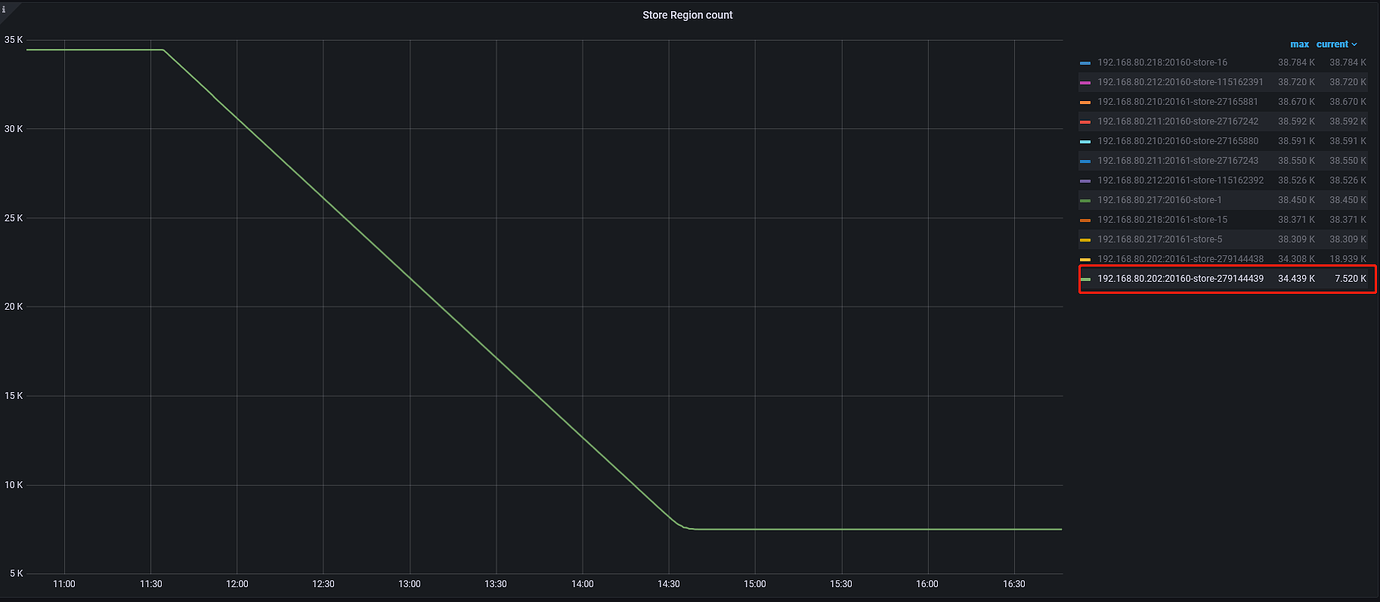
The cluster is up, but these two disks cannot be connected, resulting in many down-peers. When querying large tables in the database, the query times out. Can these two nodes be taken offline directly and let other nodes complete the data?
If the number of replicas is sufficient, you can configure offline processing.
You can directly take it offline. If it cannot be taken offline, there will be a prompt.
tiup cluster scale-in test-cluster --node 192.168.80.202:20160
tiup cluster scale-in test-cluster --node 192.168.80.202:20161
If check miss-peer is empty, that means all replicas are intact and can be safely taken offline, right?
That’s right. Just take it offline.
Two nodes failed to go offline successfully, and more than 5700 region counts could not be removed because two of the three replicas have peers in the TiKV of the two faulty disks, which belong to multiple replica damages and have no leader. How should this situation be handled?
I’ve read the “Three Axes” column. I want to ask, if two replicas are lost, will using unsafe-recover remove-fail-stores --all-regions to forcibly recover data result in data loss? Will the remaining one peer complete the other replicas?
The official documentation says to use with caution as there are risks.
Okay, I will ask about the two offline TiKV nodes. Since there was a disk failure, do I need to execute the unsafe-recover remove-fail-stores command on the two failed TiKV nodes? Or should I only execute it on the healthy store, and the failed TiKV nodes will be normally offline?
is used to handle faulty nodes.
If the number of replicas is sufficient and there is still one replica on another TiKV node, it will be scheduled for recovery according to the balancing principle.
In the current situation, if two nodes fail, the number of replicas will definitely be insufficient, and the region will automatically balance and recover.
I suggest you first check whether the number of replicas is consistent with before the failure…
Make sure there is no impact on the data before executing unsafe-recover.
I understand your meaning. Now, let me sort out the regions that are not offline. If they all have two peers on faulty stores and one peer on a normal store, I will start executing the unsafe-recover command. This command is executed on all normal stores to remove the dependent faulty peers. After the removal is completed, the two offline stores will normally transition to tombstone mode.
Yes, you can follow the instructions in this document:
If the number of replicas is sufficient, you can configure offline processing.
Is the cluster three replicas? Why are two TiKV instances on one machine?