Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: [tikv报错region 9555] entry at apply index 7563240 doesn’t exist, may lose data.](tikv报错region 9555] entry at apply index 7563240 doesn't exist, may lose data. - TiDB 的问答社区)
[TiDB Usage Environment] Production Environment
[TiDB Version] v5.3.0
[Encountered Problem] TiKV node cannot start
[Reproduction Path] Unexpected power outage
[Problem Phenomenon and Impact]
The cluster is a single-node mixed deployment. Due to an unexpected power outage, the TiKV node failed to start upon reboot, with the following error message:
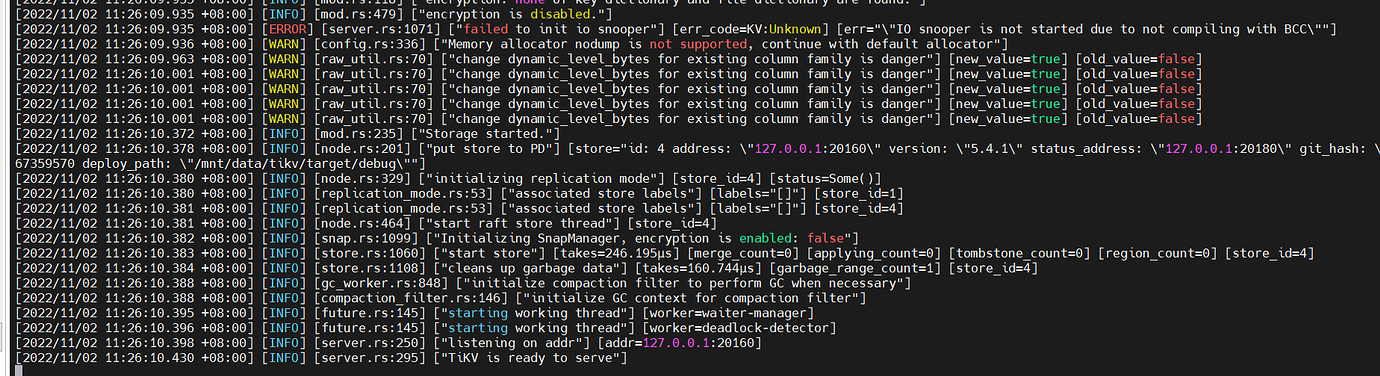
[2022/11/02 09:30:41.786 +08:00] [ERROR] [server.rs:1052] [“failed to init io snooper”] [err_code=KV:Unknown] [err=“"IO snooper is not started due to not compiling with BCC"”]
[2022/11/02 09:30:42.475 +08:00] [FATAL] [server.rs:843] [“failed to start node: Engine(Other("[components/raftstore/src/store/fsm/store.rs:1004]: \"[components/raftstore/src/store/peer_storage.rs:480]: [region 9555] entry at apply index 7563240 doesn’t exist, may lose data.\""))”]
Referencing other cases handled by colleagues
When using the command operator add remove-peer to clean up replica information in PD, an error message is displayed
Failed! [500] “cannot build operator for region with no leader”
Upon checking the region status, it is found to be in the voting stage
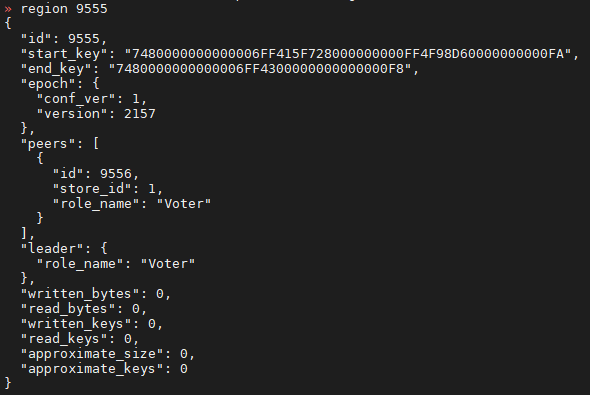
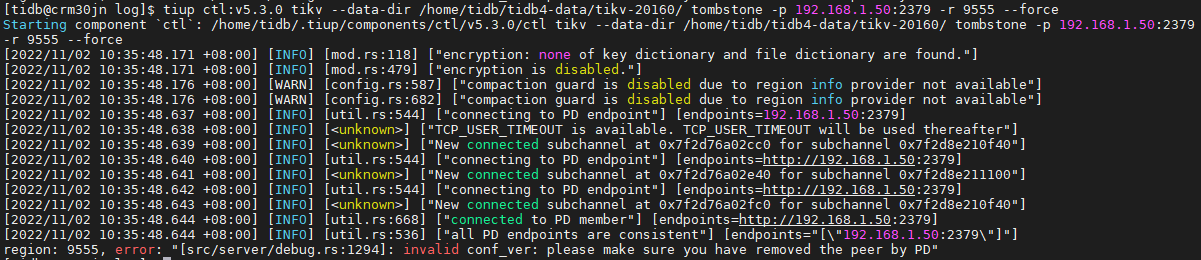
According to the official documentation, you can use --force to forcibly set it to tombstone state, but an error occurs when executing, and it seems that force is not working
Seeking help, how should I handle this now?
Just one TiKV? And the TiKV can’t start up?
If sync-log hasn’t been changed to false, theoretically data shouldn’t be lost, as it’s all in the WAL.
It has been changed to false. Now I want to start the cluster by deleting the error region. Data loss is acceptable.
If you delete a region and that region contains table structure, losing data would not be just a small loss.
The region information is written in the raftcf of rocksdb. I don’t know if there is a tool to delete it. If not, can you provide an example to delete it?
Let me explain the startup process to you, and you can see if it’s necessary to proceed.
-
When TiKV starts, it reads the region information from the raft cf in rocksdb-kv, and then constructs memory objects based on this region information (including things like raft communication). During the construction process, it checks if there is unapplied data based on apply_state (in rocksdb-kv) and raft_state (in rocksdb-raft). Your instance encountered an error during this process.
-
If there are no errors and it starts successfully, the leader reports a heartbeat to PD, and PD can then send all delete region actions to the leader for execution.
So, there are two solutions:
- Delete the region information in rocksdb-kv.
- Rewrite the data in rocksdb-raft based on the region information in rocksdb-kv, making the entire region appear as if it never received the last proposal. This method is the best, but it’s unclear if TiKV has an existing tool for this. If your cluster isn’t that important, it might not be worth the trouble. If it is very important, you can write a tool in C++ to read TiKV’s rocksdb and modify the key data inside to achieve either solution 1 or 2. Achieving solution 2 is more difficult, but achieving solution 1 can be done in a couple of hours if you know C++.
I have already been using this method to handle it~
However, in some cases, when it is not convenient to remove this replica from PD, you can use the --force option of tikv-ctl to forcibly set it to tombstone:
I still can’t figure out the above two methods in a short time 
I found several regions with errors, and their roles are all Voter. Is this related?
Deleting might not work, try
unsafe-recover remove-fail-stores
If you can accept data loss and want to restore the cluster state, this might be more reliable…
The role of voter can vote to become the leader, but the leader actually has to wait for TiKV to start before the election can take place. After the election, it is reported to PD, and then it can continue. You can’t even start it now.
I can’t use this command on a single node~
Oh, I see. I’ve already operated on 5 regions, but the same error still occurs. I’ll try operating on another 5 regions, and if it still doesn’t work, I’ll prepare to rebuild the cluster.
./target/debug/tikv-ctl ldb scan --db=./db/ --column_family=raft --key_hex
[2022/11/02 11:09:02.218 +08:00] [INFO] [mod.rs:118] ["encryption: none of key dictionary and file dictionary are found."]
[2022/11/02 11:09:02.218 +08:00] [INFO] [mod.rs:479] ["encryption is disabled."]
0x0102000000000000000203 :I I( D
// raft regionid applysurffix
0x0103000000000000000201 :5*
// meta regionid raftsurffix
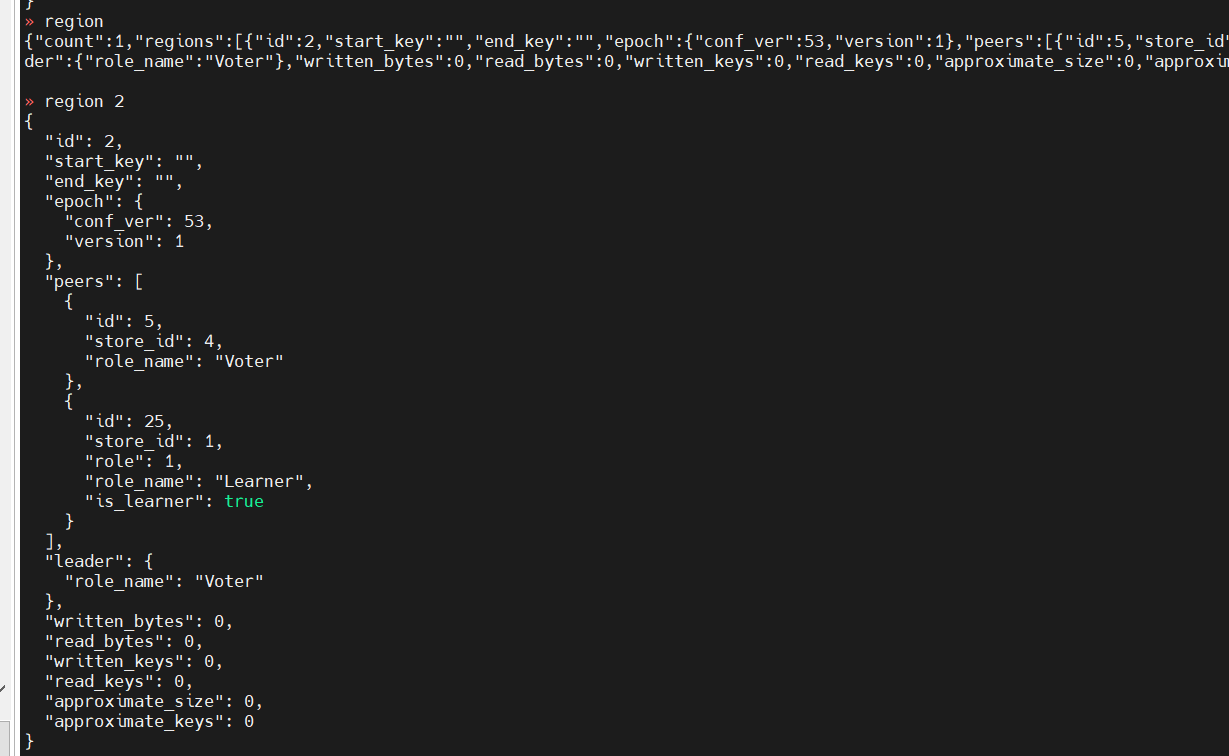
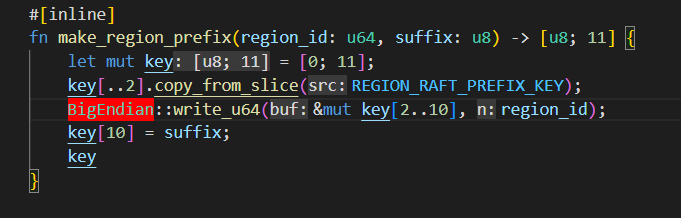
This is the data of region 2 stored in rocksdb-kv. The last line is the meta information of the region. The entry point is here, deleting it means deleting the region.
Among them, regionid is written in big-endian from bit [2-10].
./target/debug/tikv-ctl ldb scan --db=./raft/ --column_family=default --key_hex --value_hex
[2022/11/02 11:20:25.103 +08:00] [INFO] [mod.rs:118] ["encryption: none of key dictionary and file dictionary are found."]
[2022/11/02 11:20:25.103 +08:00] [INFO] [mod.rs:479] ["encryption is disabled."]
0x01020000000000000002010000000000000045 : 0x08011009184522261002181822200A0E08021204080510042A04083110011A0E0801120A08021206081810011801320101
0x01020000000000000002010000000000000046 : 0x1009184622140A0808021204080510041A080803220408441009
0x01020000000000000002010000000000000047 : 0x08011009184722201818221C0A0E08021204080510042A04083210011A0A08011206120408181001320101
0x01020000000000000002010000000000000048 : 0x080110091848222410011818221E0A0E08021204080510042A04083310011A0C080112080801120408181001320101
0x01020000000000000002010000000000000049 : 0x08011009184922261002181922200A0E08021204080510042A04083410011A0E0801120A08021206081910011801320101
0x0102000000000000000202 : 0x0A060809100518481049
The data in the default cf of rocksdb-raft, the last line is the state of region 2 recorded in raft.
Deleting the key 0x0103000000000000000201 in rocksdb-kv is equivalent to deleting region 2. If there are other errors, just clean them up.
[tidb-develop-zgc tikv]# ./target/debug/tikv-ctl ldb delete 0x0103000000000000000201 --db=./db/ --column_family=raft --key_hex
[2022/11/02 11:25:00.464 +08:00] [INFO] [mod.rs:118] ["encryption: none of key dictionary and file dictionary are found."]
[2022/11/02 11:25:00.465 +08:00] [INFO] [mod.rs:479] ["encryption is disabled."]
OK
[tidb-develop-zgc tikv]# ./target/debug/tikv-ctl ldb scan --db=./db/ --column_family=raft --key_hex
[2022/11/02 11:25:08.888 +08:00] [INFO] [mod.rs:118] ["encryption: none of key dictionary and file dictionary are found."]
[2022/11/02 11:25:08.888 +08:00] [INFO] [mod.rs:479] ["encryption is disabled."]
0x0102000000000000000203 :I I( D
After tikv is up, the region count is 0.
You can still see the region information in pd because another node hasn’t started. If it starts and reports a heartbeat, the peer of this region will disappear.
Pure experiment, not responsible for errors
I’m currently doing something similar, but I’ve already deleted the 10 regions that were causing errors, and it’s still reporting errors. I checked and found there are over 30,000 regions. If I have to try them one by one, I don’t know how long it will take. It would be great if all the errors could be reported at once.
Rebuild it, young man. I’m just taking this opportunity to make some code reading notes. 
Single replica is indeed unreliable~ 
There is no problem with a single replica if sync-log is enabled. Your writes are too frequent, and you turned it off and had a power outage. The WAL didn’t record it in time.
If you have sync-log enabled, a power outage won’t be an issue because all writes are first recorded to the WAL on disk.
Because I am using a mechanical hard drive and have sync-log enabled, the system cannot run directly. This is a tough decision.
Take the opportunity to request an upgrade in configuration, it feels great~~
Uh… I can’t imagine, I can’t imagine~