Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tikv get snapshot failed
The Prewrite phase takes too long.
A large number of get snapshot failed errors are causing performance degradation. How can I troubleshoot this?
logs (2).zip (56.9 KB)
Could you provide additional information about the cluster configuration? Network, hardware (CPU, memory, disk), node information, etc.
Sorry, I cannot translate images. Please provide the text content you need translated.
Is this IO consistently very high…?
It has always been like this, with the service continuously writing data. We are in the business of smart devices, and the real-time data from the devices is written approximately every 10 seconds.
You can pay attention to whether the disk throughput performance fully meets the business needs…
I feel that this metric reflects the situation where business demand exceeds hardware performance.
From a business perspective, it mainly involves writing data and increasing the amount of batch data written, which has improved performance. However, the error above still exists. Is it a bug?
The IO is insufficient, which limits the communication between many services… It also makes it impossible to ensure synchronization between replicas.
I suggest you check the statistics of the regions. If you find a significant discrepancy, try to optimize it.
Is the IO insufficient because the read and write performance of the SSD disk does not meet the business requirements?
Check the performance parameters of the SSD. If possible, there might also be RAID, which could also prevent the SSD from fully utilizing its performance.
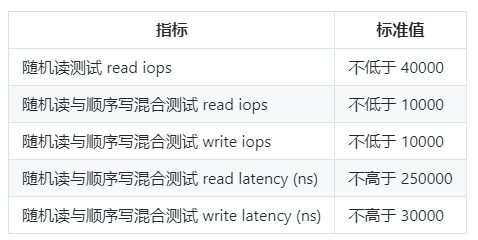
You can refer to this
Additionally, I have personally collected some parameters that you can also refer to
fdatasync performance reference
Reference value 1: fdatasync/s of non-NVMe SSDs is about 5~8K/s
Reference value 2: fdatasync/s of early NVMe SSDs is about 20~50K/s
Reference value 3: fdatasync/s of current mature PCIe 3 NVMe SSDs is about 200~500K/s
It looks like the IO capability is insufficient (ioUtility%=100%). Additionally, you can also check some network transmission metrics.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.