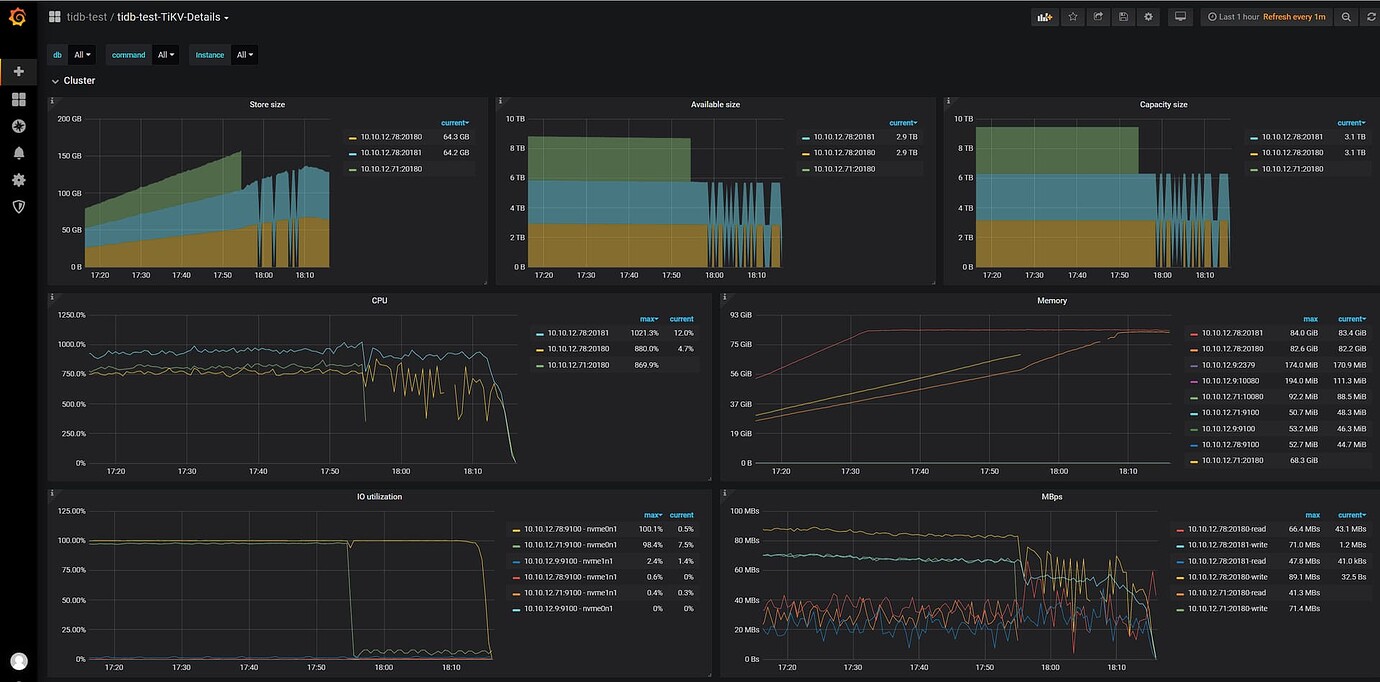
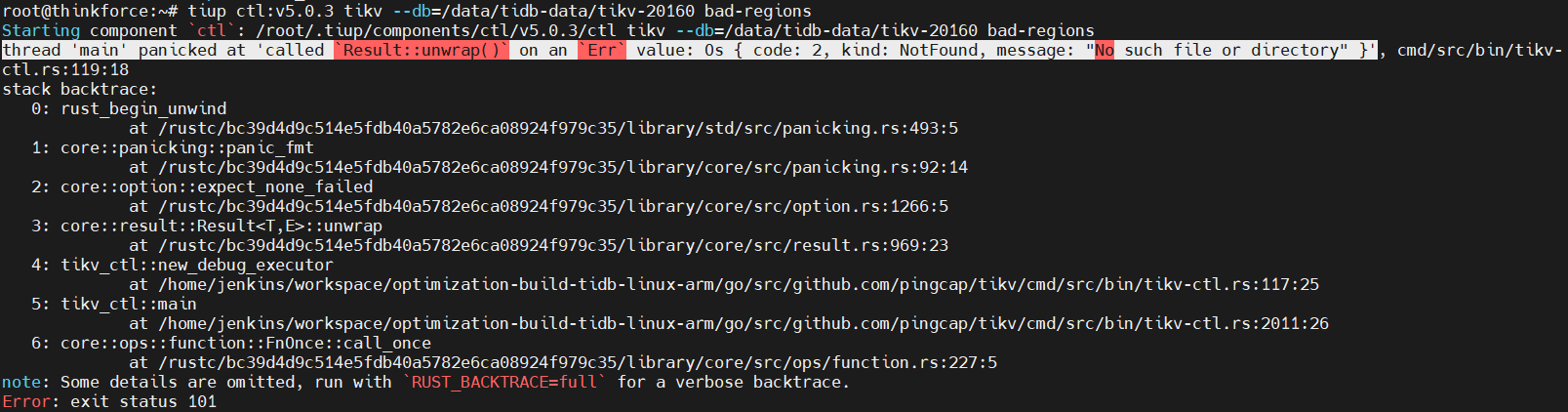
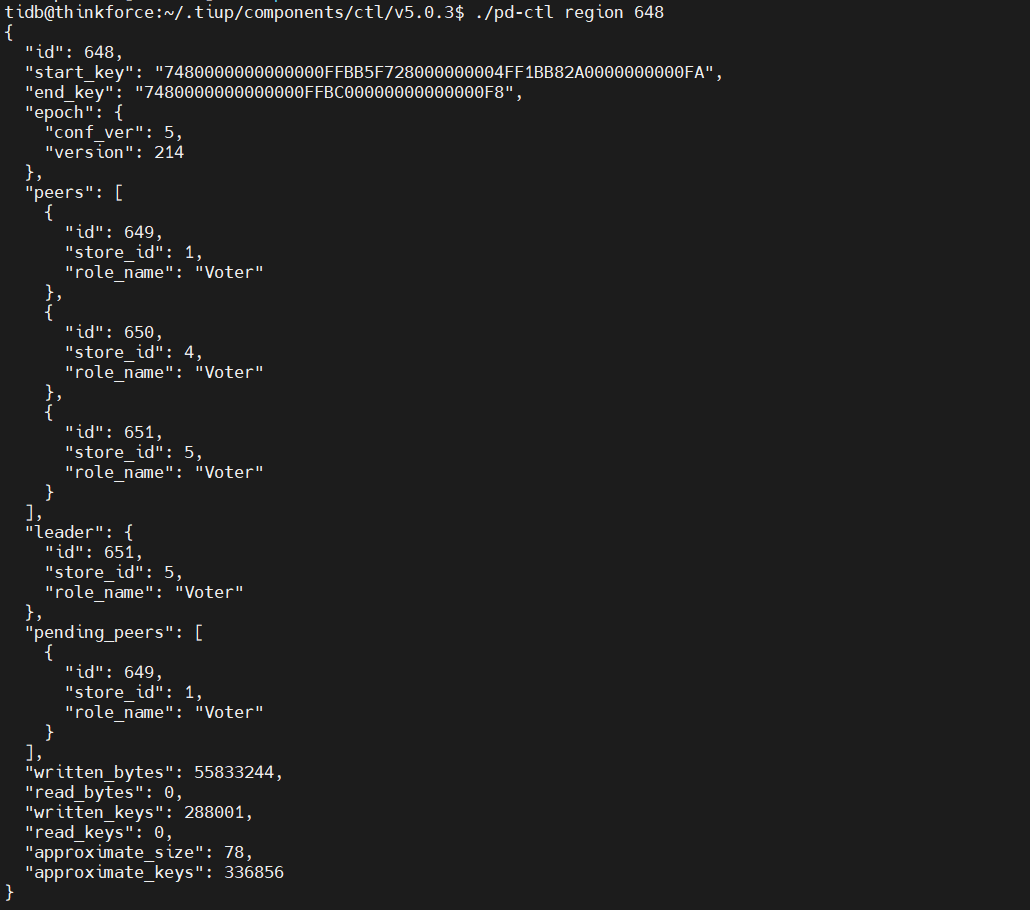
The store information found by pd-ctl is as follows:
{
"count": 3,
"stores": [
{
"store": {
"id": 5,
"address": "10.10.12.78:20160",
"labels": [
{
"key": "host",
"value": "h1"
},
{
"key": "zone",
"value": "z0"
}
],
"version": "5.0.3",
"status_address": "10.10.12.78:20180",
"git_hash": "63b63edfbb9bbf8aeb875aad28c59f082eeb55d4",
"start_timestamp": 1674902194,
"deploy_path": "/data/tidb-deploy/tikv-20160/bin",
"last_heartbeat": 1674959822476930860,
"state_name": "Up"
},
"status": {
"capacity": "2.864TiB",
"available": "2.597TiB",
"used_size": "56.64GiB",
"leader_count": 874,
"leader_weight": 1,
"leader_score": 874,
"leader_size": 75180,
"region_count": 1748,
"region_weight": 1,
"region_score": 162305.90022865508,
"region_size": 147112,
"start_ts": "2023-01-28T10:36:34Z",
"last_heartbeat_ts": "2023-01-29T02:37:02.47693086Z",
"uptime": "16h0m28.47693086s"
}
},
{
"store": {
"id": 1,
"address": "10.10.12.78:20161",
"labels": [
{
"key": "host",
"value": "h1"
},
{
"key": "zone",
"value": "z1"
}
],
"version": "5.0.3",
"status_address": "10.10.12.78:20181",
"git_hash": "63b63edfbb9bbf8aeb875aad28c59f082eeb55d4",
"start_timestamp": 1674902194,
"deploy_path": "/data/tidb-deploy/tikv-20161/bin",
"last_heartbeat": 1674959822977079499,
"state_name": "Up"
},
"status": {
"capacity": "2.864TiB",
"available": "2.597TiB",
"used_size": "56.63GiB",
"leader_count": 874,
"leader_weight": 1,
"leader_score": 874,
"leader_size": 71932,
"region_count": 1748,
"region_weight": 1,
"region_score": 162305.90022885762,
"region_size": 147112,
"start_ts": "2023-01-28T10:36:34Z",
"last_heartbeat_ts": "2023-01-29T02:37:02.977079499Z",
"uptime": "16h0m28.977079499s"
}
},
{
"store": {
"id": 4,
"address": "10.10.12.71:20160",
"labels": [
{
"key": "host",
"value": "h3"
},
{
"key": "zone",
"value": "z0"
}
],
"version": "5.0.3",
"status_address": "10.10.12.71:20180",
"git_hash": "63b63edfbb9bbf8aeb875aad28c59f082eeb55d4",
"start_timestamp": 1674959822,
"deploy_path": "/data/tidb-deploy/tikv-20160/bin",
"last_heartbeat": 1674917576942024622,
"state_name": "Down"
},
"status": {
"capacity": "2.864TiB",
"available": "2.658TiB",
"used_size": "61.8GiB",
"leader_count": 0,
"leader_weight": 1,
"leader_score": 0,
"leader_size": 0,
"region_count": 1748,
"region_weight": 1,
"region_score": 162076.62883248986,
"region_size": 147112,
"start_ts": "2023-01-29T02:37:02Z",
"last_heartbeat_ts": "2023-01-28T14:52:56.942024622Z"
}
}
]
}
Tikv has labeled.