Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiKV节点无法启动
[TiDB Usage Environment] Production environment
[TiDB Version] v7.1.1
[Reproduction Path] Unable to start after being killed by the system due to high memory usage
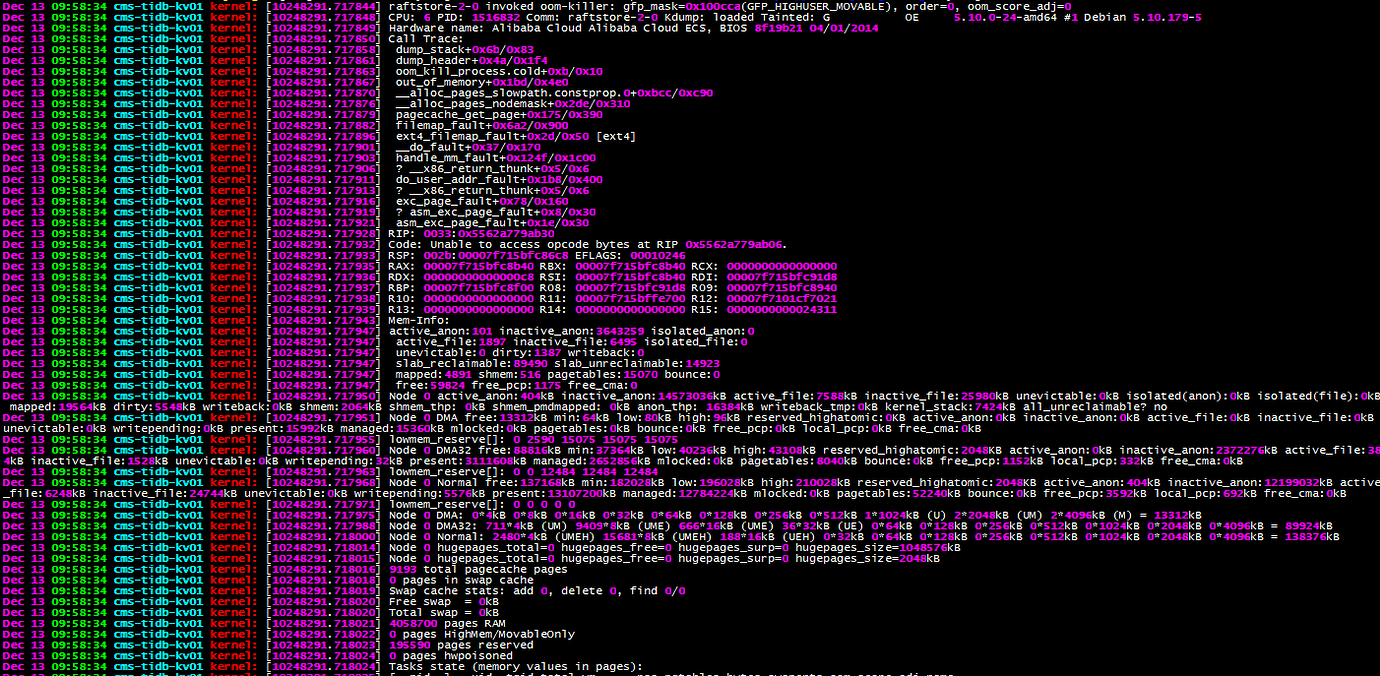
[Encountered Problem: Phenomenon and Impact] Startup reports [FATAL] [setup.rs:309] [“invalid configuration: Cannot find raft data set.”]
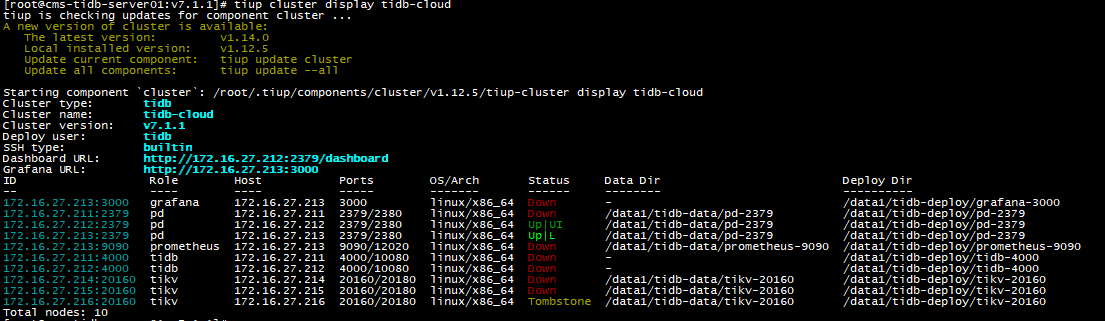
3 KV nodes, 2 cannot start
[Resource Configuration] 3 PD nodes, 4c8g; two server nodes 4c8g; 3 KV nodes, 8c16g, 500G SSD
[Attachments: Screenshots/Logs/Monitoring]
After data repair, it still cannot start.
Two out of three TiKV nodes are down, check out the three-step solution… 专栏 - TiKV缩容下线异常处理的三板斧 | TiDB 社区
Hello, expert! When starting the kv node, it shows [2023/12/13 15:28:42.268 +08:00] [FATAL] [setup.rs:309] [“invalid configuration: Cannot find raft data set.”] Can it still be started?
How are you handling this now? It looks like there’s a configuration issue, and it can’t find the raft file.
How did it end up like this? 
The kv process has exited, and restarting the process gives this error.
None of the 3 KV nodes can start now. Can I create a new cluster to recover using the data files?
Currently, all three KV nodes are down. Node 1 reports:
[2023/12/13 22:08:33.016 +08:00] [ERROR] [util.rs:682] ["connect failed"] [error="Grpc(RpcFailure(RpcStatus { code: 4-DEADLINE_EXCEEDED, message: \"Deadline Exceeded\", details: [] }))"] [endpoints=http://172.16.27.211:2379]
[2023/12/13 22:08:33.021 +08:00] [FATAL] [setup.rs:309] ["invalid configuration: Cannot find raft data set."]
Node 2 reports:
[2023/12/13 22:06:43.282 +08:00] [ERROR] [util.rs:682] ["connect failed"] [error="Grpc(RpcFailure(RpcStatus { code: 4-DEADLINE_EXCEEDED, message: \"Deadline Exceeded\", details: [] }))"] [endpoints=http://172.16.27.211:2379]
[2023/12/13 22:06:49.727 +08:00] [FATAL] [server.rs:921] ["failed to start node: Engine(Other(\"[components/raftstore/src/store/fsm/store.rs:1230]: \\\"[components/raftstore/src/store/entry_storage.rs:657]: [region 16] 17 validate state fail: Other(\\\\\\\"[components/raftstore/src/store/entry_storage.rs:472]: log at recorded commit index [12] 19 doesn't exist, may lose data, region 16, raft state hard_state { term: 5 commit: 5 } last_index: 5, apply state applied_index: 19 commit_index: 19 commit_term: 12 truncated_state { index: 17 term: 11 }\\\\\\\")\\\"\"))"]
Node 3 reports:
[2023/12/13 22:07:33.620 +08:00] [ERROR] [util.rs:682] ["connect failed"] [error="Grpc(RpcFailure(RpcStatus { code: 4-DEADLINE_EXCEEDED, message: \"Deadline Exceeded\", details: [] }))"] [endpoints=http://172.16.27.211:2379]
[2023/12/13 22:07:42.971 +08:00] [FATAL] [server.rs:921] ["failed to start node: StoreTombstone(\"store is tombstone\")"]
It seems like it’s all because PD can’t connect. That’s why it won’t start.
Yesterday, I set up a new cluster according to the original configuration. It started normally, and then I copied the data files of the old cluster’s PD and KV to the new cluster for startup. I found that this method didn’t work, and the old cluster was also contaminated by the new cluster. When starting, I found that the new cluster had connections to the old cluster. I suspect that the PD data files recorded the cluster information. At this point, I shut down the new cluster and found that one PD in the old cluster was down, and the startup reported an error:
[2023/12/13 20:44:55.410 +08:00] [ERROR] [kv.go:295] [“fail to load safepoint from pd”] [error=“context deadline exceeded”]
[2023/12/13 20:44:55.528 +08:00] [ERROR] [pd_service_discovery.go:221] [“[pd] failed to update member”] [urls=“[http://172.16.26.212:2379,http://172.16.26.213:2379,http://172.16.27.211:2379]”] [error=“[PD:client:ErrClientGetMember]get member failed”]
Can it still be rescued?
The original cluster is 172.16.27.211-216, and the new cluster is 172.16.26.211-216.
Your cloud environment looks quite unreliable. The errors on nodes 1 and 2 are due to data loss or corruption, causing them to fail to start. Is node 3 tombstone due to scaling down? Starting a new cluster with old data files seems untested, especially since your original data files are already compromised. Even if you set up a new cluster, the new cluster’s PD still needs to use pd-recover to restore the cluster-id and alloc-id.
Can you explain this in detail? Or provide some documentation, thanks!
This environment has been running for a long time without any issues. Yesterday morning, one KV node suddenly went down, and the system logs showed it was OOM. The node couldn’t be brought back up. By noon, another KV node went down, also due to OOM, and it couldn’t be brought back up either.
It’s unbelievable that the cloud environment can cause IO corruption, it’s so unreliable.