[TiDB Usage Environment] Production Environment / Testing / Poc
System Version: Ubuntu 20.04
TiDB Version: v.6.5.1 v6.5.0
[Reproduction Path]
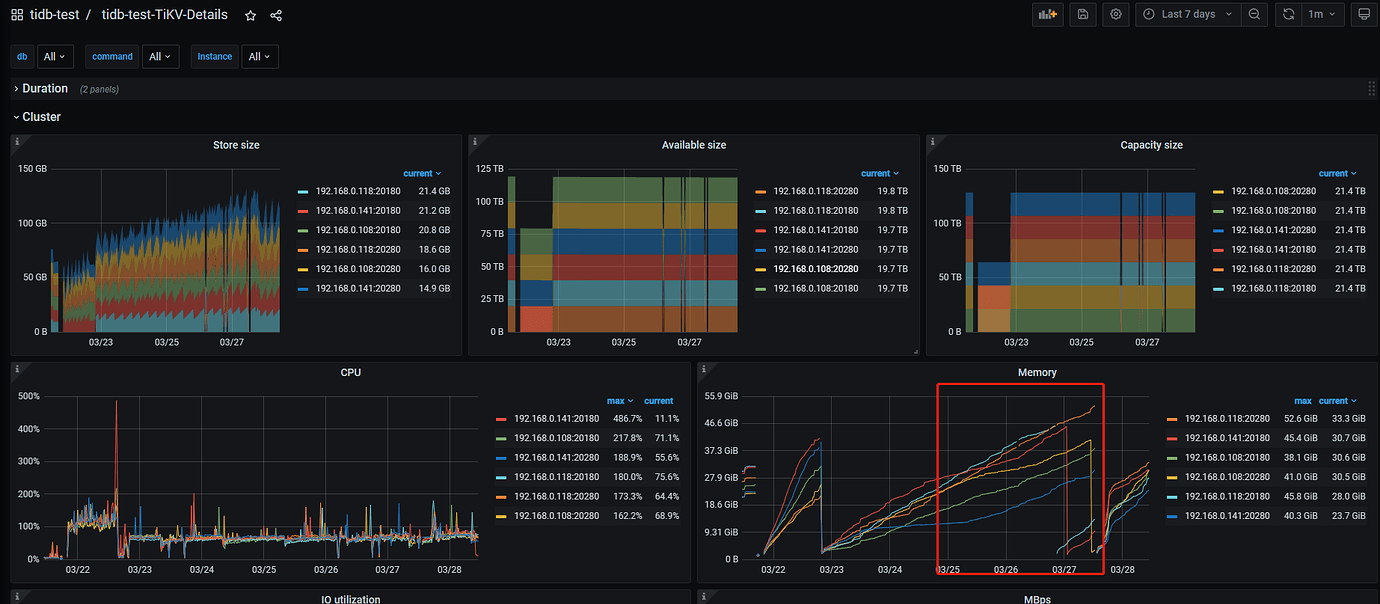
During e2e testing, memory usage continues to grow even after the pressure stabilizes. If long-term e2e testing is conducted, it will trigger OOM.
[Encountered Problem: Problem Phenomenon and Impact]
Situation Description:
Three hosts: 16C 128G 20T*3
Three TiDB, three PD, six TiKV (with multiple disks), and sufficient host resources.
Note: Mixed with business, but confirmed that it is not the business or other basic components occupying resources that triggered OOM, causing TiKV to be mistakenly killed.
If mixed deployment is used, pay attention to the memory configuration of TiKV. Otherwise, if the system memory is insufficient, Linux will kill TiKV as a zombie process.
Is there a recommended value for this memory configuration? My host has 128G of memory, running two TiKV instances should be sufficient, right? Other programs don’t really use much memory.
If an OOM occurs, just kill the process with the highest memory usage. Which process is using the most memory? TiKV limits its usage to 80%. How much memory do your other services use?
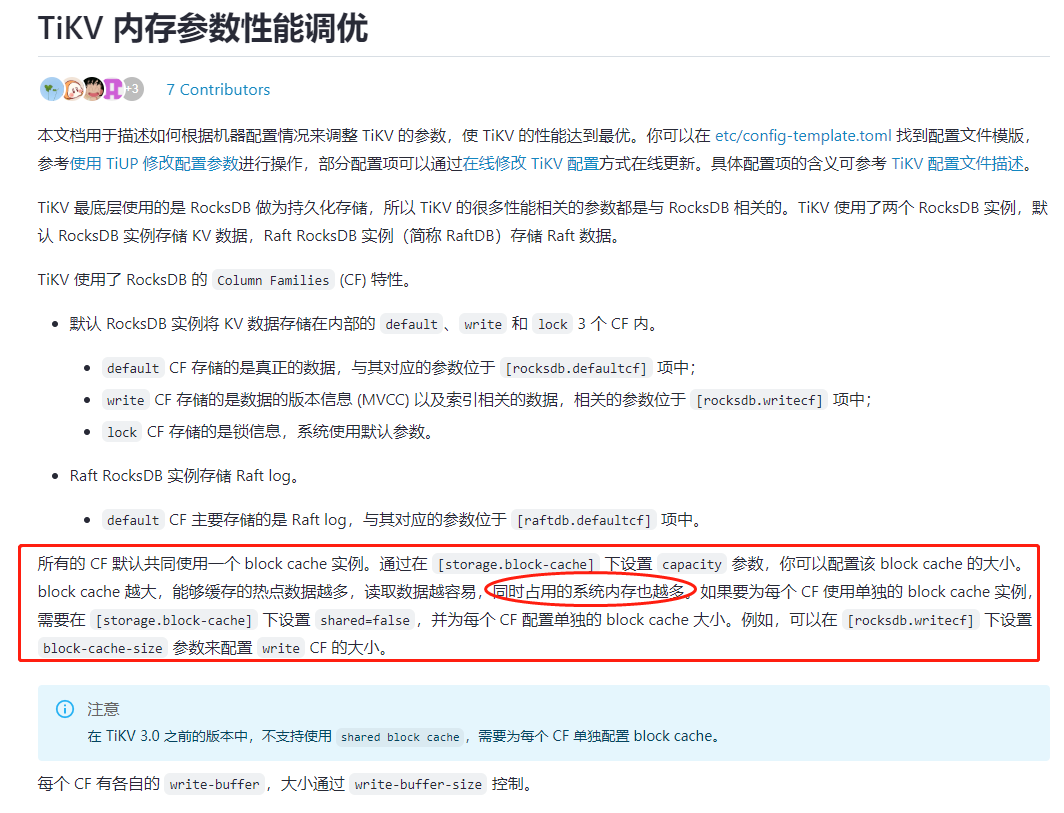
SHOW config WHERE TYPE=‘tikv’ AND NAME LIKE ‘%storage.block-cache.capacity%’;
Check this parameter. If a single TiKV is deployed on one server, set it to 45% of the server’s memory. If two TiKVs are deployed on one server, set it to 22.5% of the server’s memory. Additionally, if two TiKVs are deployed on one server, you can bind each TiKV to a single NUMA node by specifying numa_node to prevent mutual interference.
We originally had slow disk writes but couldn’t add more machines, so we added disks and mixed two TiKV instances. The disk write latency is very high with SAS disks.