Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tikv reload报 metric tikv_raftstore_region_count{type=“leader”} not found
[Version] v6.1.0 ARM
raft-engine.dir: /raft/raftdb
[Phenomenon] After adding a label to tikv using pd-ctl store label and executing reload -R tikv, a certain tikv node reports:
Restart instance xxx130.96:20160 success
Error: failed to evict store leader xxx130.97: metric tikv_raftstore_region_count{type=“leader”} not found
[Inspection]
-
Checked the region information on tikv, all are 0
-
Checked tikv status
-
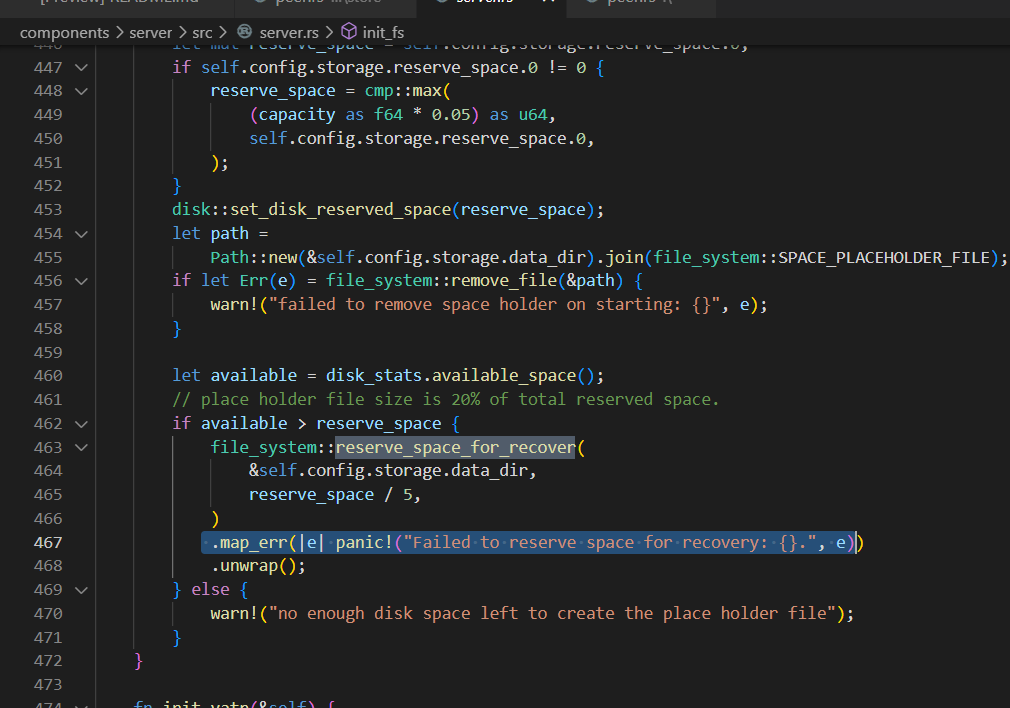
Found errors in tikv.log
[FATAL] [lib.rs:491] [“Failed to reserve space for recovery: Structure needs cleaning (os error 117).”] -
Checked file system, parameters, placeholder files
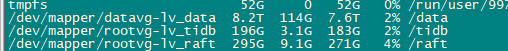
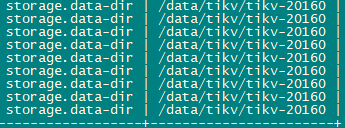
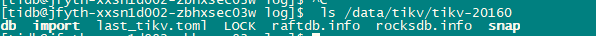
-
Tried restarting tikv, still reported the above error
[2022/08/17 15:39:27.324 +08:00] [INFO] [config.rs:891] [“data dir”] [mount_fs=“FsInfo { tp: "ext4", opts: "rw,noatime,nodelalloc,stripe=64", mnt_dir: "/data", fsname: "/dev/mapper/datavg-lv_data" }”] [data_path=/data/tikv/tikv-20160/raft]


[2022/08/17 15:33:40.836 +08:00] [WARN] [server.rs:457] [“failed to remove space holder on starting: No such file or directory (os error 2)”]
[2022/08/17 15:33:44.895 +08:00] [FATAL] [lib.rs:491] [“Failed to reserve space for recovery: Structure needs cleaning (os error 117).”] [backtrace=" 0: tikv_util::set_panic_hook::{{closure}}
at /var/lib/docker/jenkins/workspace/build-common@3/go/src/github.com/pingcap/tikv/components/tikv_util/src/lib.rs:490:18
1: std::panicking::rust_panic_with_hook
at /root/.rustup/toolchains/nightly-2022-02-14-aarch64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/panicking.rs:702:17
2: std::panicking::begin_panic_handler::{{closure}}
at /root/.rustup/toolchains/nightly-2022-02-14-aarch64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/panicking.rs:588:13
3: std::sys_common::backtrace::__rust_end_short_backtrace
at /root/.rustup/toolchains/nightly-2022-02-14-aarch64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/sys_common/backtrace.rs:138:18
4: rust_begin_unwind
at /root/.rustup/toolchains/nightly-2022-02-14-aarch64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/panicking.rs:584:5
5: core::panicking::panic_fmt
at /root/.rustup/toolchains/nightly-2022-02-14-aarch64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/panicking.rs:143:14
6: server::server::TiKvServer::init_fs::{{closure}}
at /var/lib/docker/jenkins/workspace/build-common@3/go/src/github.com/pingcap/tikv/components/server/src/server.rs:467:26
core::result::Result<T,E>::map_err
at /root/.rustup/toolchains/nightly-2022-02-14-aarch64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/result.rs:842:27
server::server::TiKvServer::init_fs
at /var/lib/docker/jenkins/workspace/build-common@3/go/src/github.com/pingcap/tikv/components/server/src/server.rs:463:13
7: server::server::run_impl
at /var/lib/docker/jenkins/workspace/build-common@3/go/src/github.com/pingcap/tikv/components/server/src/server.rs:124:5
server::server::run_tikv
at /var/lib/docker/jenkins/workspace/build-common@3/go/src/github.com/pingcap/tikv/components/server/src/server.rs:163:5
8: tikv_server::main
at /var/lib/docker/jenkins/workspace/build-common@3/go/src/github.com/pingcap/tikv/cmd/tikv-server/src/main.rs:189:5
9: core::ops::function::FnOnce::call_once
at /root/.rustup/toolchains/nightly-2022-02-14-aarch64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/ops/function.rs:227:5
std::sys_common::backtrace::__rust_begin_short_backtrace
at /root/.rustup/toolchains/nightly-2022-02-14-aarch64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/sys_common/backtrace.rs:122:18
10: main
11: __libc_start_main
12:
"] [location=components/server/src/server.rs:467] [thread_name=main]
[Questions]
-
The tikv node is already down, why does it still check the leader count using metric tikv_raftstore_region_count{type=“leader”} during reload? Can this state be skipped or handled in another way? (Maybe this tikv had issues during deployment, but it wasn’t noticed at the time)
-
In emergencies, the space holder file can be deleted to free up disk space. Here, the error [“Failed to reserve space for recovery: Structure needs cleaning (os error 117).”] is reported during restart. OS error code 117: Structure needs cleaning. What structures need to be cleaned? The placeholder file has not been manually deleted before.