Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tikv查看netstat存在大量僵尸连接
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version]
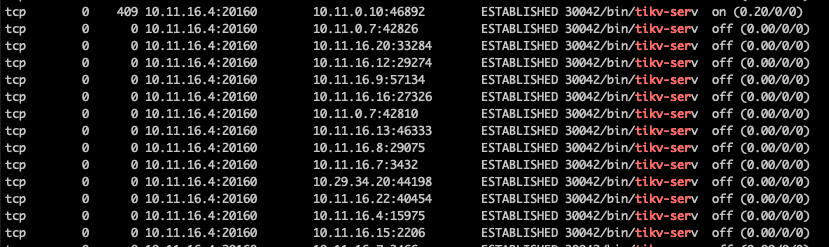
[Reproduction Path] Execute netstat -nop | grep -i “tikv-serv”
[Encountered Problem: Problem Phenomenon and Impact]
When executing netstat -nop | grep -i “tikv-serv”, many IP hosts that have already gone offline still show the connection status as ESTABLISHED.
The system has already set
net.ipv4.tcp_keepalive_time=60
net.ipv4.tcp_keepalive_intvl=5
net.ipv4.tcp_keepalive_probes=3
However, TiKV has not enabled the tcp_keepalive function, so connections cannot be reclaimed.
- How can TiKV enable the tcp_keepalive function?
- How can these connections be closed or reclaimed? (Preferably without restarting or affecting the business)
Determine the parent process of the zombie process. In the output of the ps command, the PPID (Parent Process ID) column shows the parent process ID of each process.
Analyze the behavior of the parent process. Why hasn’t it reclaimed its child process’s resources? It could be because the parent process is waiting for certain conditions to reclaim the resources, or the parent process itself has crashed or is hung.
In what scenarios would this be used? Is it an application mode for bare TiKV? But the client side has a connection recycling mechanism, could it be caused by forced closure?
Is this the connection between tikv and tidb server?
There are no zombie processes; the client’s host has already gone offline, but the connection is still ESTABLISHED.
The use case is as the metadata storage for JuiceFS, in the TiKV txn mode. It is likely caused by forcibly shutting down the process.
No, the connection is generated by connecting directly to TiKV using client-go.
I suggest going to the machine of the client (fourth column) to see which process is connecting to TiKV. It’s not just the TiDB server that can connect to TiKV; tools like Lightning can also connect.
client-go has a paradigm for handling abnormal connections, right? Could it be that it was missed, causing the issue?
For now, let’s not consider how it was generated; let’s solve the current problem first.
The connection generated is very clear; it is client-go in the juicefs client. The key issue is that the machine has already gone offline, but the connection status is still ESTABLISHED.
Restart by node instance… It’s best to have enough nodes to support the number of replicas…
As for the program’s pitfalls, finding a workaround from elsewhere? That seems quite difficult, but you can try more… 
The program is used unreasonably, so the database side does not need to do self-protection. Theoretically, the server side should also handle it.
In the open-source community, there currently might not be the capability to support this. You can raise an issue to see if there are any plans for iteration.
If you have a particularly strong need for this feature, you might consider seeking support from the original developers, upgrading your service level, and possibly finding a solution.
You can try packet capturing first. In theory, gRPC also has application-layer keepalive, so there shouldn’t be any lingering connections.
Join the group for consultation.
Go to the source and see what tool or application is connecting.
Has this issue been resolved?