Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tispark写入10万记录OK,50万开始报错
[TiDB Usage Environment] Testing
[TiDB Version] 6.5
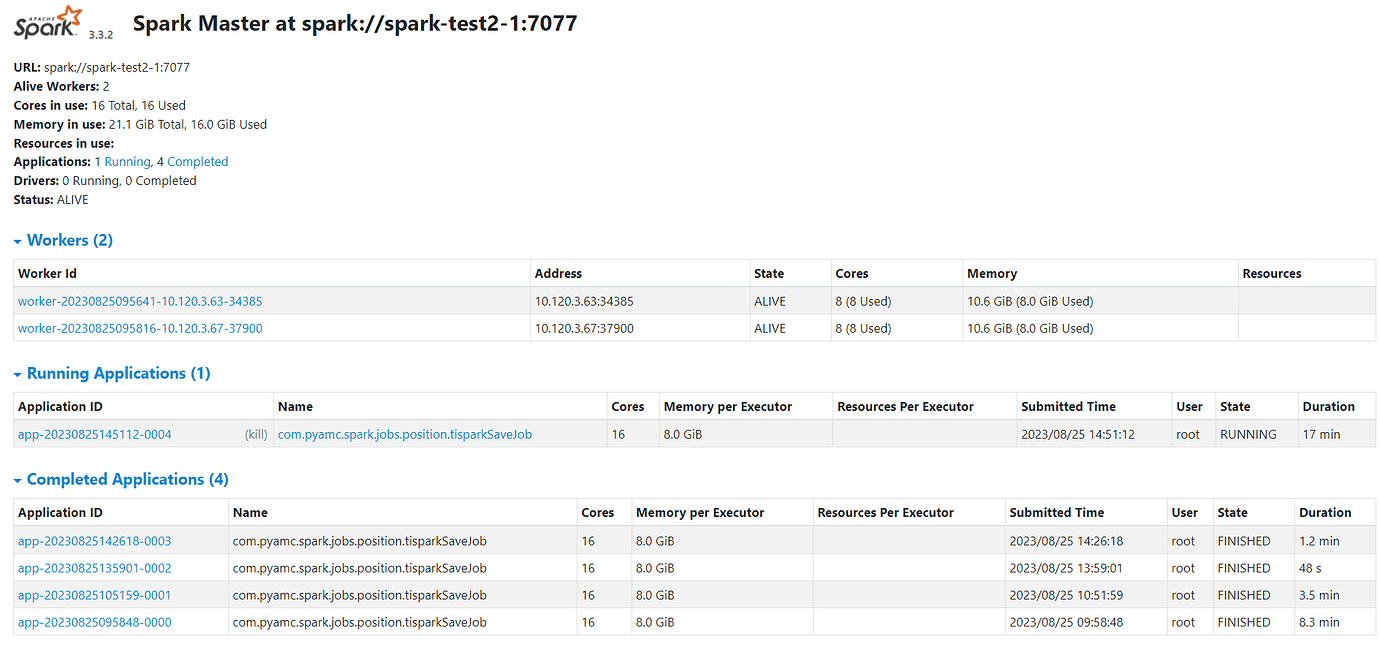
[Reproduction Path] Currently using Spark to transform existing business. In one scenario, Spark writes the computed data into TiDB. The data records are approximately 8 million, with each record having 10 fields. Writing directly into TiDB using Spark takes 5 minutes. Considering that using TiSpark might be faster, I set up a simple Spark standalone cluster with one master and two workers. The Spark version is 3.3.2, and the TiSpark jar package is tispark-assembly-3.3_2.12-3.1.3.jar. The data is written into the same TiDB test database.
Writing 50,000 records takes 48 seconds; 100,000 records take 1.2 minutes. When the data volume increases to 500,000, an error occurs.
Just started using TiSpark, not sure what caused the issue. Any experienced experts’ guidance would be appreciated.
[Encountered Problem: Problem Phenomenon and Impact] For 500,000 data, the log shows it was divided into 37 tasks. The 20th task reported “Error reading region,” and subsequent tasks reported the same error.
23/08/25 14:53:36 WARN TaskSetManager: Lost task 20.0 in stage 0.0 (TID 20) (10.120.3.63 executor 1): com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:191)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:168)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:114)
at org.apache.spark.sql.tispark.TiRowRDD$$anon$1.hasNext(TiRowRDD.scala:70)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.columnartorow_nextBatch_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at scala.collection.Iterator$SliceIterator.hasNext(Iterator.scala:268)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:140)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:186)
… 20 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:243)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:92)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
… 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: retry is exhausted.
at com.pingcap.tikv.util.ConcreteBackOffer.doBackOffWithMaxSleep(ConcreteBackOffer.java:153)
at com.pingcap.tikv.util.ConcreteBackOffer.doBackOff(ConcreteBackOffer.java:124)
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:708)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:689)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:229)
… 7 more
Caused by: com.pingcap.tikv.exception.GrpcException: TiKV down or Network partition
… 10 more
23/08/25 14:53:36 INFO TaskSetManager: Lost task 18.0 in stage 0.0 (TID 18) on 10.120.3.67, executor 0: com.pingcap.tikv.exception.TiClientInternalException (Error reading region:) [duplicate 1]
23/08/25 14:53:36 INFO TaskSetManager: Starting task 18.1 in stage 0.0 (TID 26) (10.120.3.67, executor 0, partition 18, ANY, 9207 bytes) taskResourceAssignments Map()
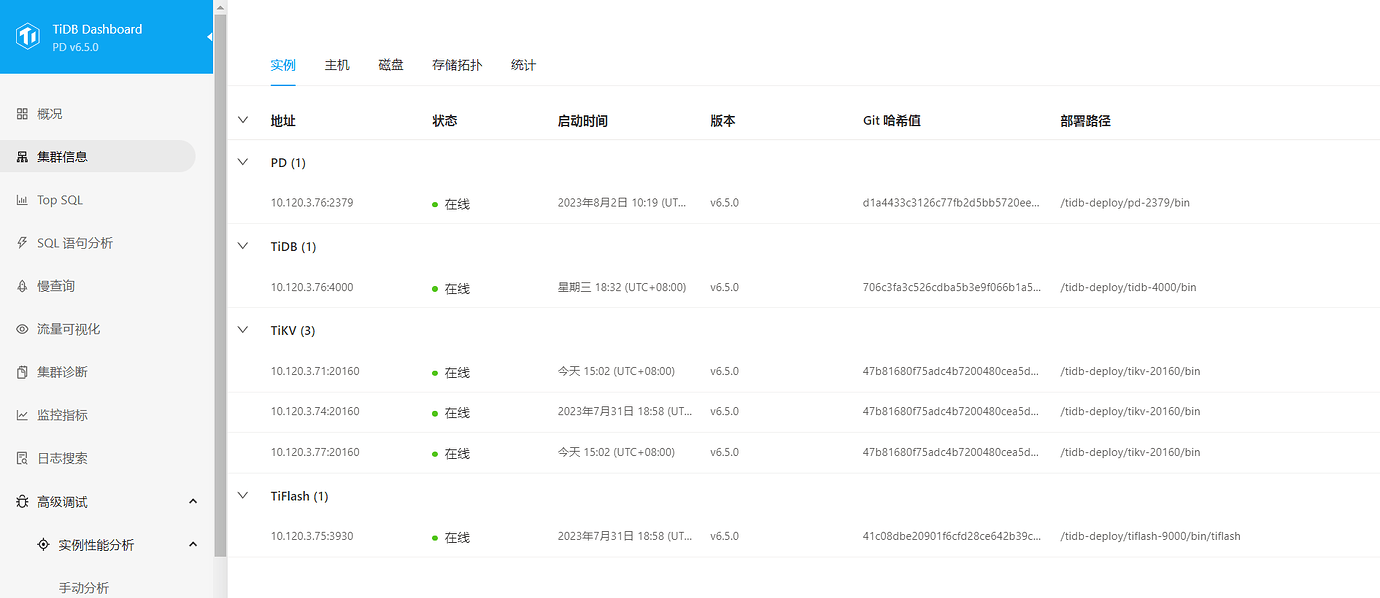
[Resource Configuration] Enter TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]
tispark_write_500k_records_log.txt (146.7 KB)